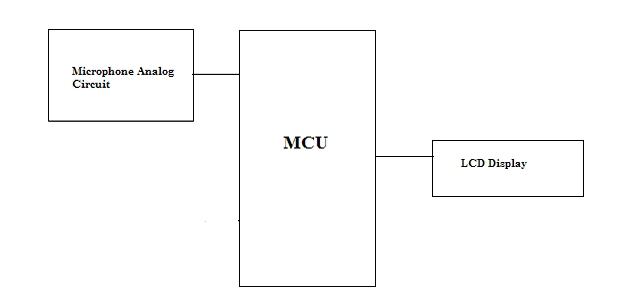
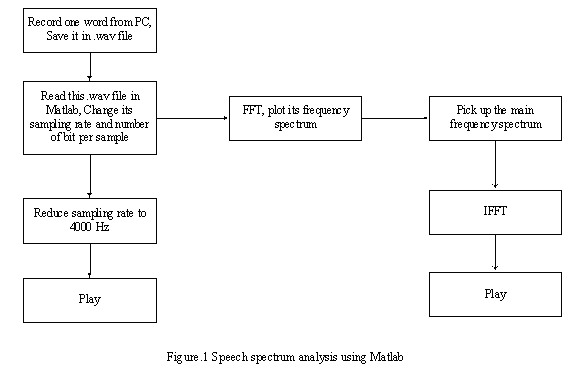
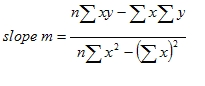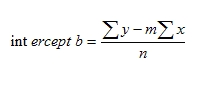Generally the human speech spectrum is less than 4000Hz. According to Nyquist theory, the minimum sampling rate for speech should be 8000samples/second. Due to our system is voice-controlled safety system; it is very helpful to analyze the speaker's voice before our actual design.
Our design is based on the recorder program installed in Windows XP and FFT function in Matlab. After we speak one word, the recorder program will store the word in a .wav file. Notice this file is sampled at 16000 samples/second, 16bit/sample, so we need to convert it into 8000samples/second, 8bits/sample. The whole analysis procedure is as the following figure.
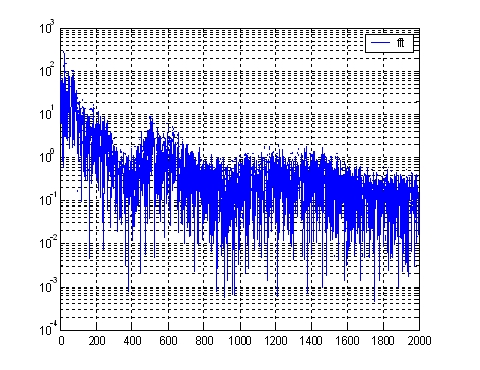
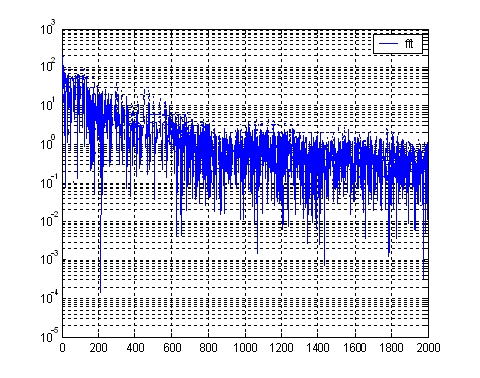
The following figures are tester's "hello" and "left" frequency spectrum.
|
|
| Fig.2 The frequency spectrum of "HELLO" | Fig.3 The frequency spectrum of "LEFT" |
From the above analysis result, we select the sampling rate in our system is 4000sample/second, 8bits/sample. The cutoff frequency for LPF and HPT is 50Hz, 1500Hz respectively. In order to get the accurate fingerprint of the code, we use seven filters, their working range are:
- LPF: [0-50Hz]
- BPF_1: [50-350Hz]
- BPF_2: [350-500Hz]
- BPF_3: [500-750Hz]
- BPF_4: [750-1000Hz]
- BPF_5: [1000-1500Hz]
- HPF: [> 1500Hz]
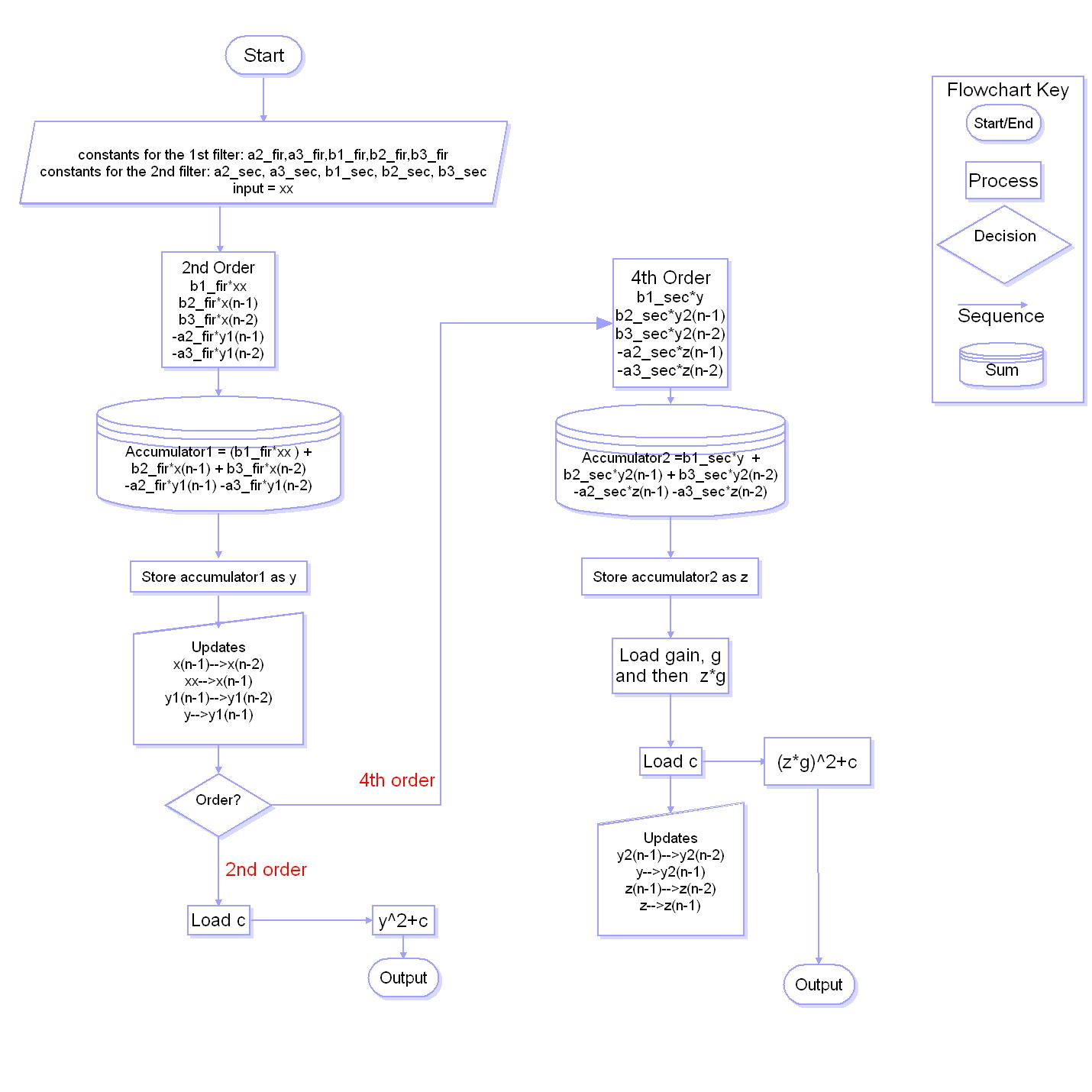
From previous analysis, we know the frequency range of each filter. So first we use Matlab to generate their coefficients. Here we use ChebychevII filter.
- Fs=4000; %Hz
- Fnaq=Fs/2; % Nyquist
- [B0, A0]=cheby2 (2, 20, f0); % LPF
- [B6, A6]=cheby2 (2,20, f6, 'high'); % HPF
- [B1, A1]=cheby2 (2, 20, [f0 f1]); % BPF
For LPF and HPF, we just use second order filter. For BPF filters, we use fourth-order filter. In implementation, the fourth-order filter actually is cascaded by two second-order filters. The coefficients of these two second-order filters are obtained by the following Matlab command:
[sos1, g1]=ft2sos (B1, A1,'up', 'inf');
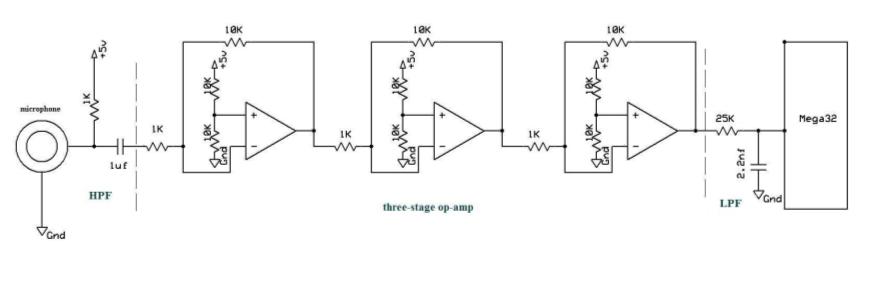
For the LPF and HPF filter, we take Bruce's sample code as a reference. However, we made a little change. The fingerprint of the speech is the accumulation of the square of the output of each filter. So we combine the calculation the square and accumulation in one filter function. For the fourth-order BPF, we duplicate the second-order filter but using different coefficients. After finishing our code, we tested the filter based on two cases.
First, using an Impulse sequence to test it and compare the result with Matlab. This case is to test whether our filter correction is correct. Here we used sample impulse sequence xn=[16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ]
Second, using source generator to generate different frequency sine waves and send them to the filter. The results are also comparing with Matlab's result. This case is to test whether our filter's frequency setup is correctly or not. The following figure is our test result of the second case. We print the sine wave's fingerprint to the hyper terminal and use Matlab to plot its figure.
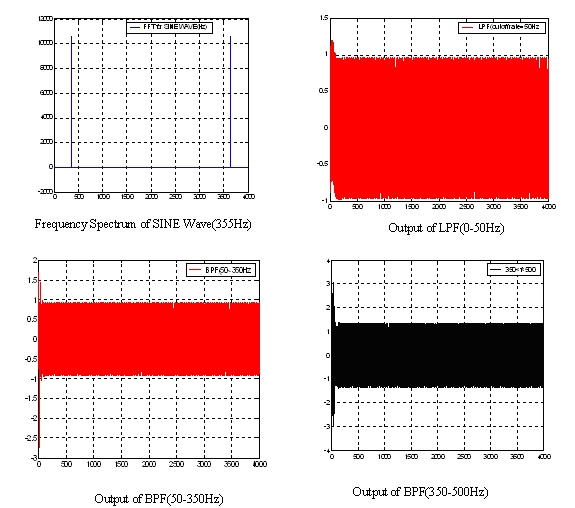
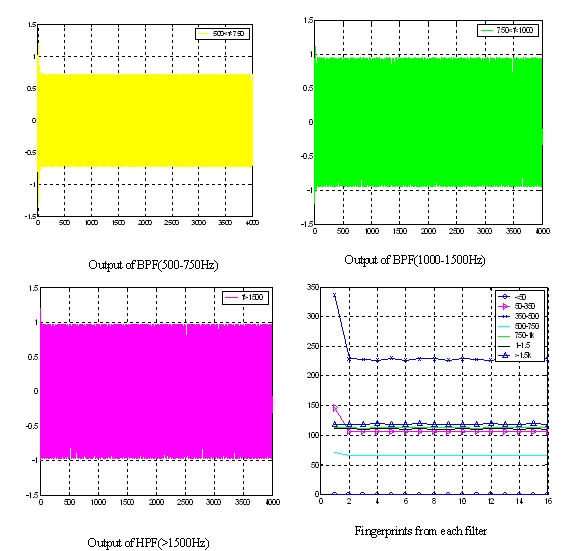
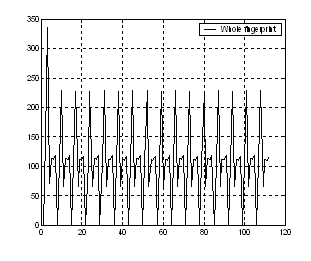
Figure. 4 Fingerprints of sine wave (f=355Hz)
From the above plots, the output from BPF (350-500Hz) has a maximum value, which exactly matches the testing sine wave (355Hz).
We also use 800Hz sine wave to test our filter arrays. Figure.5 shows the result which also proves our filter design is correct.
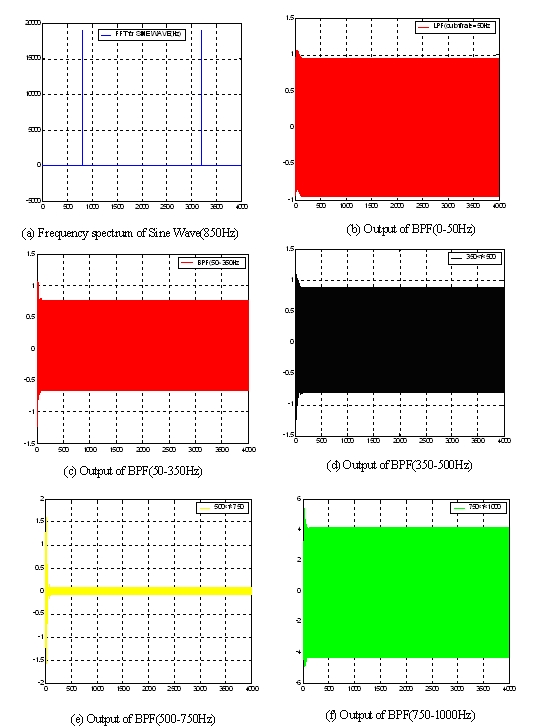
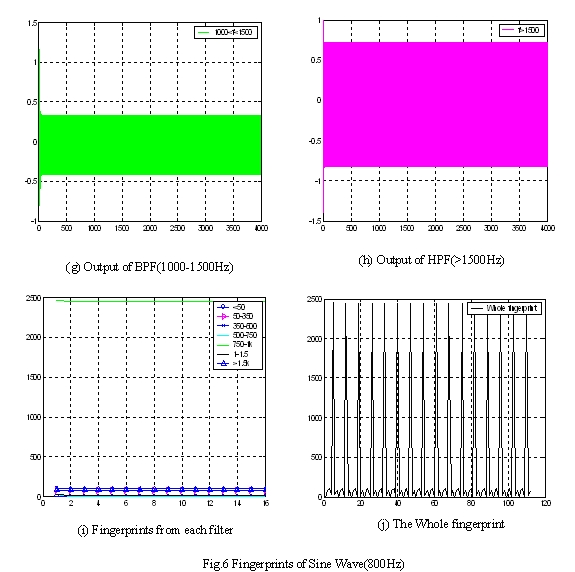
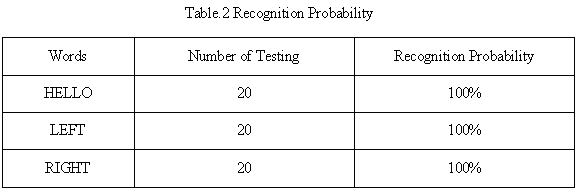
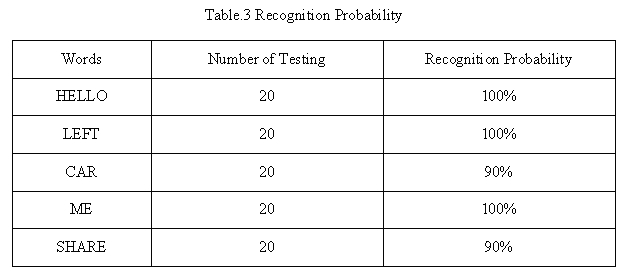
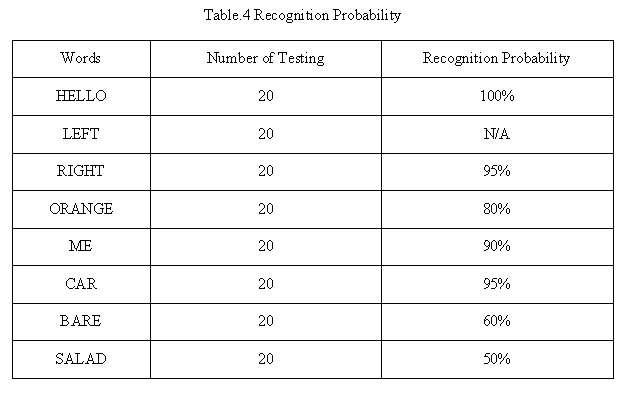
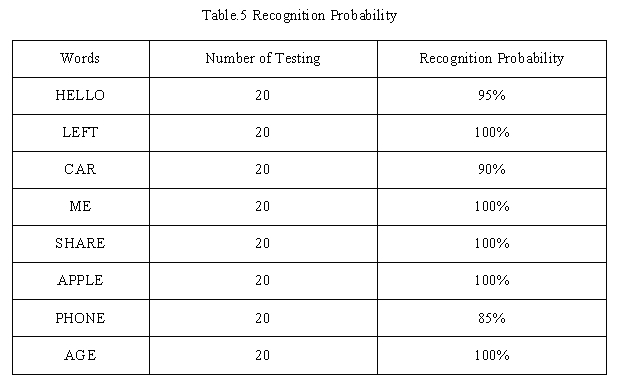
Finally, we tested the running time of our filter. Table1 shows the result.
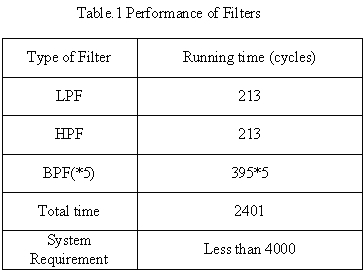
The sample interval is 1/4000*16M=4000cycles, which is much longer than processing time of all filters. So our filter design can meet the real time requirement of speech recognition.
Each sample of the speech will pass all eight filters and gets its corresponding outputs. The fingerprint of each filter is an accumulation of 250 consecutive outputs square of this filter. Basically, different words has different frequency spectrum, then it has different fingerprint. Same words have same fingerprints. However, even one person speaks the same word for several times, its fingerprints are a little different. So we need to calculation the difference of different words and compare to the difference of same words to test whether system can recognize it.
Because LPF and HPF have some frequency components which we are not interested, in actual process, we disable these two filters and just use other five filter to analysis the speech.
The first method we used in this project is to calculate the Euclidian distance. That is the accumulation of the square of each difference. The formula is as following
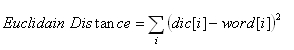
Because all codes are written using fixed-point algorithm, the maximum value of integer is only 256. So if we use Euclidian distance, the result will overflow. To solve this problem, we first convert output of ADC, ADCH from the unsigned char to integer and send it to filter without using int2fix () function. That is, the input of the filter is always less than one. There is no overflowing anymore.
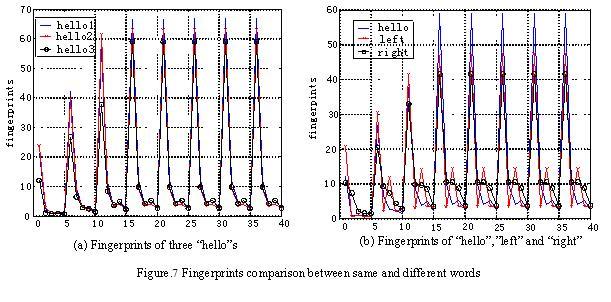
During the test, when we plot the fingerprint of the same word as figure 7 shows, we found their shapes are similar but they have different amplitude. At that time, Euclidian distance will judge them as different words. So here we used correlation to tell the similarities of the same word's fingerprint.
From mathematics view, the correlation is to detect the linear relationship between two vectors. Suppose Y and X and two vectors, if Y=aX+b, where a and b are constants, we say Y and X are closely correlated.
Actually, in our project, we combine correlation and Euclidian distance together. The system first detects the correlation of dictionary and testing code. If they are distinct, the system thinks it already recognize the word. If more than two correlation results are close, and then calculate the Euclidian distance of these similar words. Pick up the minimum of the Euclidian distance as its recognition result.
There are two hardest parts in our speech recognition project. One is for filter design, the other is fingerprints analysis. The shortcoming for filter is its frequency spectrum resolution is coarse and can't tell the difference in its band. So we have to select some distinct words as our codes. FFT is a good candidate for filter design. For fingerprints analysis, because the outputs of each band filter are largely different, so we tried to modify the gain to equalize them. However, the improvement seems little for us.
Another problem is when a tester spoke the same word, even if there is a tiny difference when he spoke, the fingerprint changed a lot. We didn�t solve this problem until now. But we think if we increase frequency resolutions, maybe it will be helpful.