


An exploration into the way sound interacts with your head.
Introduction
For our ECE 5030 final project, we designed a system that would investigate head-related transfer functions (HRTF). The project was broken into two main sections: a data acquisition device that would import data relating to the HRTF into MATLAB and custom hardware to stream music from any audio device and convert the sound into binaural sound played through a pair of headphones.
We chose this project due to our interest in acoustics as well as understanding how the human body is able to interpret binaural sounds. However there have not been many publications on binaural sound recording or synthesis on low end processors. This inspired us to implement our own binaural sound data acquisition and synthesis using a relatively low end microprocessor.
High Level Design
Rationale and Sources
A head-related transfer function is the response of the ear that characterizes how sound is received from a point in space. Using a pair of HRTFs for each ear can be used to synthesize a binaural sound. Extensive research has been done on HRTFs to understand how the people detect where sound is coming from. This research has been applied film making, music recording, as well as video games to improve the user experience.
There have been several published methods for obtaining and implementing a head-related transfer function for a subject, including patents, which are discussed later on in the section about Intellectual Property. A paper by Wenzel et al.(1993) showed individualized HRTFs are not necessary for the listener to obtain some useful directional information from synthesized interaural difference cues, but also that the use of non-individualized HRTFs can increase incidences of front-back confusion. The paper by Pec et al. (2007) presented work similar to our interests, focusing on developing an electronic travel aid for the blind by using spatialized audio through stereo headphones by using HRTFs. This particular group fabricated their own equipment for data collection and measured HRTFs for individuals. For our project, we chose to calculate the HRTF for a given individual and emit spatialized audio using the HRTF. We accomplish obtaining the HRTF by using a portable speaker to emit a chirp generated by MATLAB and recording from the ear canals of a subject, and then the data is then analyzed in order to obtain the HRTF. The HRTF is then used to produce binaural sound through headphones.
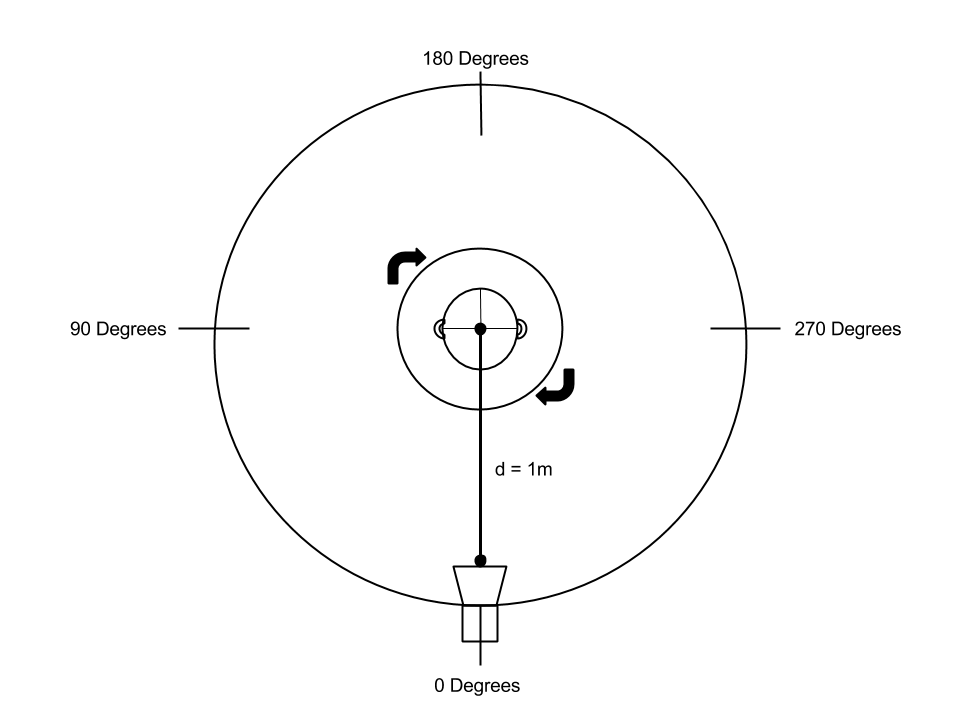
Normally the head related transfer function is function of the azimuth angle, elevation angle, frequency, and distance. In order to simplify the analysis and the data acquisition set up we chose to have focus only the azimuth and frequency components of the HRTF. The elevation angle was kept at zero and the distance of the sound source was held constant at one meter. One meter was used to balance between the tradeoffs of having the sound source at different distances. At very short distances we approach the near field of the HRTF where sound is no longer naturally traversing to both ears and at very long distances our signal-to-noise ratio of our sampled data decreases due to noise in the testing room.
Logical Structure
The project can be broken down into three distinct sub-sections. The first encompasses experimental design and data collection. The second involves the analysis of HRTFs using the obtained data. The third is the implementation of the system in order to produce spatialized audio.
Data Acquisition
In the data acquisition subsection of the project, the data required to analyze the HRTF of the subject is acquired. In order to complete this, the hardware and experimental set up were designed and fabricated. For the experimental setup, the subject sits in a rotating chair with stationary speakers that are set at eye level and one meter away from the subject's head. Linear chirp functions are played at different angles relative to the subject's head. The sound propagates through the air to the subject's ears, where the sound is picked up by the microphones in the subject's ear canals. The analog signals pass through a microphone amplifier circuit which is then sampled by the microcontroller's internal ADC at 32 kHz. The data is then stored in on board SRAM chips. When the chirp function is finished playing the user can import the data into MATLAB.
Data Analysis
In this subsection, the acquired data is analyzed using MATLAB. When the data is imported, it passes through a series of various filter types to reduce the acoustic noise that was present in the room where the data acquisition set up was performed. Once the data is filtered, a few scripts are made to generate plots for power intensity versus angle in each ear, time-delay between ears versus angle, and power spectral density plots. The power intensity plots are normalized to each other and then those plots and time-delay data are then interpolated by splicing the plots and using linear function approximations to implement the HRTF.
System Implementation
In the system implementation, a simplified version of the HRTF is implemented on the microprocessor. Audio data is streamed into an amplifier and the data is then sampled after that. The appropriate magnitude and time-delays are applied by the processor and then the data is outputted to a pair of DACs (digital to analog converters). The analog signals are then sent to an amplifier to increase the power of the signal and produce low output impedance to drive the low resistive headphone load.
Hardware/Software Tradeoffs
Due to the limitations of our embedded processor, ideas were explored for implementing various techniques in hardware for recreating the HRTF. However, implementing time delays in hardware is not an easy task since it would either need to be implemented with some sort of delay buffer or with an all-pass filter with variable phase changing rates. Furthermore, the amplitude changes would probably need to be done with some sort of feedback loop to use a MOSFET as a variable controlled resistor or using a digital controlled trim pot. Both elements of the HRTF are more easily implemented in firmware since microcontrollers can easily create variable delays by changing the pointer locations in a buffer, and the amplitude changes were efficiently implemented since the microcontroller architecture contains a hardware multiplier. All the amplification necessary to improve signal to noise ratio (SNR) and headphone driver circuitry has to be implemented in hardware since these are analog functions.
Standards
One of the few main standards that are applicable to our project is interfacing our system to standard audio inputs. Since it is ideal to conform our system with any consumer audio device, we need to match our input amplifier to the standard set voltage levels for audio signals. Several sources confirmed that the consumer audio line-levels are at -10dBV, which corresponds to an RMS voltage of 0.316V with a peak-to peak swing of 0.447V. Lab measurements using smart phones and computers have confirmed these numbers for normal volume levels.
The only other standards applicable to the project are related to system communication. To communicate between the microcontroller and the computer, our system uses the RS-232 communication standard. For communication between the microcontroller and the SRAM as well as the microcontroller and the DACs, variations of the serial peripheral interface (SPI) communication standard are followed.
Intellectual Property
Currently, there are several patents that involve obtaining or the use of head-related transfer functions. Some patents focus on the use of head-related transfer functions for spatial audio rendering. Other patents such as the one by Budnikov(US 2005/0069143 A1) or Chen and Lau (US 2006/71167881 B1) describe filtering methods for obtaining the head-related transfer functions. The patent by Lapicque (US2006/7079658 B2) describes a system and method for localization of sounds using HRTFs, but the system involves the processing of multiple audio files These patents are sufficiently different from our project. When designing our system we did not look into active/patented designs of collecting data for HRTFs or synthesizing binaural sound. Our design was entirely based off of concepts in electrical engineering that we have learned throughout our academic careers, as well as the basic knowledge of HRTFs that we came across in preliminary research relating to the topic. We planned on expanding our knowledge on HRTFs with the completion of this project.
Furthermore, due to the fair-use doctrine for copyrights, and copyrighted music used in a nonprofit, educational environment, there is no concern about using music that is copyrighted during our tests. Since the music is not being distributed to others, and using it as an educational example, we are well within the bounds of the fair-use doctrine defined by both the US Government, as well as Cornell University's policy on music sharing.
Data Acquisition
Experimental Setup
As mentioned above, the HRTF for this project focuses on the full azimuth range, but not elevation. In order to record signals, the subject is asked to sit in the center of a rotating tray. The angles at which the signals would be recorded are marked out on the floor around the rotating tray. The speaker used for emitting the high-energy signal is set to the eye-level of subject, using a stack of book of differing widths in order to adjust the height. For recording the signals, cap microphones are held to each ear canal, and a high-energy signal is played from the signal for recording. With each recording, the subject is then asked to rotate the table to the next angle marking, and then the data would be collected.
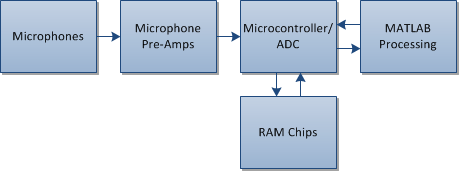
Hardware Design
The hardware for data acquisition included the microphones, the preamplifiers, the ADC/microcontroller, the RAM chips, and the level shifter. All components receive their voltage input either from the power supply or the LM2937, a low dropout (LDO) regulator family. The selected family member was the 3.3V part.
Microphone and PreAmplifier
For recording the data, three cap microphones are used. The wires attached to all microphones are soldered and twisted together. For two of the microphones, sound is recorded from the blocked ear canal of the subject. This was accomplished by attaching the microhphones to the end of shortened, commercially available earplugs by running the microphone wires through a hole created at the end of the earplug. The third microphone is used as a reference and is attached to the subject's chest using tape. Each of these microphones are attached to separate preamplifiers which are connected to the microcontroller.
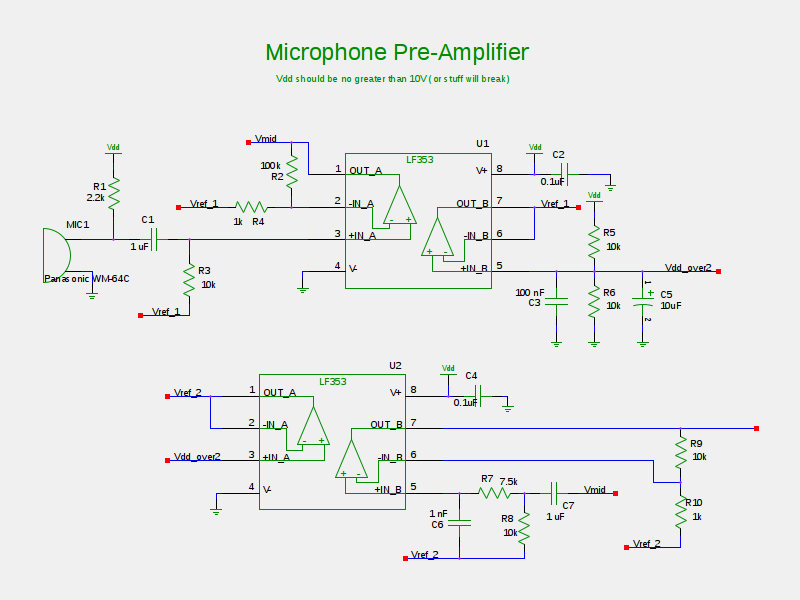
The preamplifier circuitry starts with a biasing resistor that is a 2.2 k\(\Omega\) resistor for the internal JFET, which acts as an output buffer stage for the microphone. The audio signal then passes through a high pass filter with a cutoff frequency of 16 Hz. The purpose for this filter is to re-bias the DC component of the signal to 1.65V (half the supply rail) to act as a virtual ground. A virtual ground is necessary to prevent clipping since there is no negative voltage rail in our design. Without a virtual ground, signals that are biased at ground will experience clipping on the negative component and signals that are biased at levels above ground will saturate to the positive rail since the DC component of the signal will experience the high gain of the amplifier. The virtual ground is created by using a voltage divider with two 10 k\(\Omega\) resistors between the supply rail and ground. The divider node is sent into an op-amp channel of the LM353 which is set up as a voltage follower. This is done to prevent any circuit loads connected to the virtual ground reference to affect the output voltage. The capacitors are used to decouple perturbations that were coupling onto the reference voltage line.
The signal then passes through a non-inverting amplifier using an LF353 op-amp. The gain is set to be about one hundred times the gain. The signal then leaves the first stage of the amplifier and passes on to the second stage of the amplifier. The second stage has the same high pass filter as the first stage to eliminate any input offset voltage that would re-bias the signal after the first stage. The signal is then passed to a passive low pass filter, which has a cutoff frequency of about 21 kHz. The audio signal then passes through another non-inverting amplifier, set with a gain of about ten. The signal is then sent to the ADC/Microcontroller circuitry.
Microcontroller and Peripherals
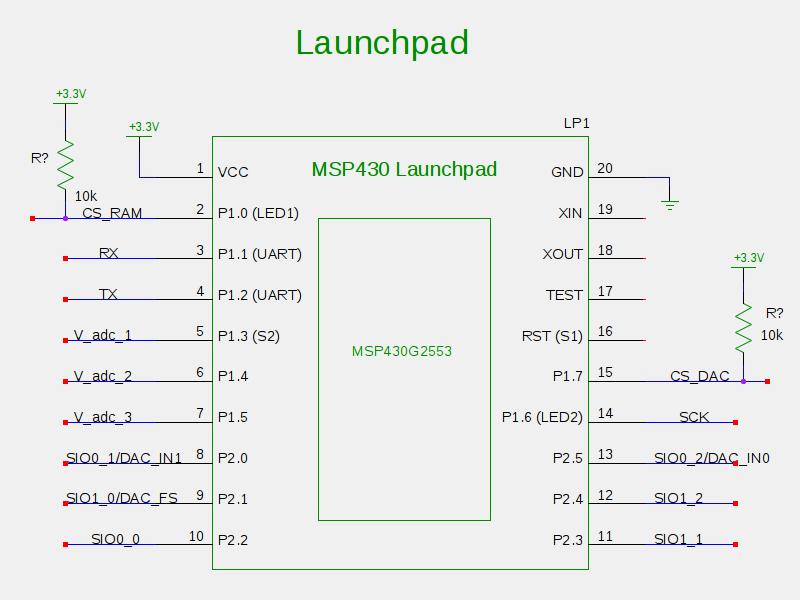
The ADC/Microcontroller circuitry starts with the analog input buffering circuit. The input to the circuit is another high pass filter which re-biases the circuit to the microcontroller virtual ground, which is approximately 1.65V (half of the microcontroller voltage supply rail), which is created in a very similar manner as the virtual ground for the pre-amplifier circuitry. Since the pre-amplifier boards are powered by 5V and the microcontroller is powered by 3.3V, potentiometers are used on each channel to make sure that the input to the ADC is not saturating. The re-biased signals are then passed through a buffer implemented with a voltage follower circuit using the MCP6001 op-amp. These signals are then passed to the ADC of the microcontroller.
The microcontroller used in this project was the MSP430G2553, which was part of the LaunchPad Development Kit from Texas Instruments. The code implemented for the data acquisition software was to record sampling data from the microphones and store the data on the RAM chips, as well as interface with the user using the RS-232 communication protocol to determine when to start sampling data and when to start transmitting all the stored data. Since the microcontroller only had 512 bytes of RAM, the 23LC1024 SRAM chips were used. One SRAM chip was used for each microphone channel, providing a total of 384 kilobytes of RAM to store the data. The reason data is not streamed during the sampling process is because the serial communication is too slow (even with a very high baud rate) to allow a 32 kHz sampling frequency. The internal ADC for the microcontroller is a 10-bit ADC, but since the SRAM chips were 8-bit chips, the two least significant bits of the digitized value are thrown out.
A MAX3233E RS-232 transceiver is used as the level shifter to communicate between the TTL voltage levels of the microcontroller and the higher voltage lines required by the RS-232 communication standard. The level shifting to go from 3.3V levels to the approximately 10V levels is done by using internal charge pump capacitors in the level shifter.
Software Design
The code for this part of the project involves generating and playing the linear chirp function, obtaining measurements, and saving the data to the computer. These tasks are split between MATLAB running on a laptop and the MSP430 microcontroller.
MSP430 Code
In our system, the MSP430 performs all of the direct steps necessary for sampling data for all three channels (left ear, right ear, and reference) using its internal ADC. We used a timer interrupt handler firing at 32 kHz to first get sample data from all three channels, then save it to the SRAM chips. Each set of three samples is written to the SRAM immediately. Since the internal ADC is a 10-bit ADC, we throw out the two least significant bits in order to write the data into the SRAM. Once the sampling process is initiated, we continue acquiring data until the external SRAM is full.
To communicate with all three SRAMs simultaneously, we implemented the communication protocol described in the 23A1024 datasheet in which bits can be sent two at a time (the SDI variant described in the datasheet) by manually toggling the microcontroller pins on the microcontroller for the serial clock and serial data lines (colloquially known as "bit-banging"). Our implementation of everything related to the sampling process is designed to run as fast as possible, since this is what limits our sampling rate.
In order to tell the microcontroller to begin sampling, transfer data to the computer, and perform general debugging, we implement a simple terminal-style interface over UART, with which we can send commands and view reponses from the microcontroller.
The set of all of the commands we implement for this portion of the project are as follows:
| Command | Purpose |
| reset | Performs a software reset of the microcontroller. |
| uptime | Returns the amount of time in seconds the MCU has been running without being reset |
| sample | Begin sampling from the ADCs |
| getdata | Begin the sampled data transfer process |
| next | While transferring data, signifies that the MCU should transfer the next block of data |
| invalid | While transferring data, signifies that the MCU should resend the same block of data |
| done | Provides confirmation that the data transferral process is complete |
| testram | Executes an SRAM communication test, returning whether or not the SRAMs can be read from and written to |
| testadc | Executes an ADC test, returning single samples from each of the three channels |
MATLAB Code
When performing the data acquisition experiment, MATLAB is used to generate the linear chirp function as well as communicate with the microcontroller to perform the sampling and data transfer tasks. The purpose of the linear chirp function is to get a broadband signal that has equal magnitude components over the frequency range of interest. The original plan was to use an impulse function to generate the desired broadband signal of interest. However, it turns out that to get a broadband signal with approximately equal magnitude content from 0 - 20 kHz with a 40 kHz sampling frequency, the impulse function needs to be about 30 microseconds long. When generating this sound on the computer, the energy content was too small and the microphones would not hear anything.
The linear chirp function is defined as follows: \(x(t) = \sin\left(\phi_0 + 2\pi\left(f_0t + \frac{kt^2}{2}\right)\right)\) where \(f_0\) is starting frequency and k is the rate of frequency increase, also known as the chirp rate. This function allows us to play a high output energy signal that had equal magnitude frequency components in the range of the chirp. Our frequency sweep range is from 50 Hz to 10 kHz and lasts for three seconds. The time length is computed to finish just before the SRAM is filled.
When the data is being transferred from the microcontroller to the computer, a simple error correction scheme is implemented where we send a block of 64 samples for each channel followed by a 1-byte checksum. Once the computer receives all 64 bytes, the computer recomputes the checksum and compares it with the received one. Since the checksum is only one byte, meaning its range is from 0 to 255, the computer needed to take the modulus of the computed checksum and 256. If the checksums do not match, the computer sends the invalid command to the microcontroller and it resends the packet. Otherwise it sends the next command, which prompts the microcontroller to send the next set of data. Once all the data is sent the computer sends the done command, which tells the microcontroller to exit the data transferal mode.
The checksum is implemented because with the baud rate of the communication running at 230,400 baud, there would be approximately a one percent error rate in the transferred data. Due to the large size of data (about 384 kilobytes) there was the potential for accuracy errors which would have corrupted our data analysis in the following stage of the project.
A basic MALTAB library is also written for our project which includes a series of a few basic scripts that implement the serial communication with the microcontroller. Scripts that were written include an update serial ports list, open serial port, and close serial port. Test scripts that were written include the test script to start the sampling process while playing the chirp function and the retrieve data from the microcontroller operation.
The reason a script is necessary to update the list of available serial ports is because the built-in functions in MATLAB are not able to do so. The serial libraries were written under the assumption that serial ports are soldered in place on the computer's motherboard and will therefore never change location. This assumption made by Mathworks in no longer true since most motherboards do not come with serial ports and therefore USB-Serial converters have been made to interface with USB ports, while still being able to use a communication protocol such as RS-232 which is very easy to implement. To implement this function, the script checks which operating system the computer is running using the isunix and ispc functions. If the operating system is UNIX-based (Linux or Mac) the script checks if a Linux kernel is being used by running the function system('uname'). The script then uses either command prompt or terminal (depending on the operating system) to check the available serial ports. The script is currently set up to only run with one serial port object so it grabs the string of the first serial port object it finds.
Results
The entire experimental setup was successful as the data corresponding to the HRTF was measured and transmitted to the computer using a custom MATLAB library that was written to communicate between the microcontroller and the microcontroller. The microcontroller's firmware was written to handle the various serial commands as well as sample and store the data relating to the microphone inputs. All of the hardware is functional as it would amplify, filter, and re-bias the microphone outputs so they could be sampled by the microcontroller's internal ADC.
Data Analysis
Four sets of data total were taken for analysis. Twenty data points were acquired for each individual in a particular state. These points were acquired for every twenty degrees from 0 up to 340 degrees, with two extra recordings at 90 and 270 degrees. Each subject in the experiment had two different states. For one subject, the data was obtained once with his hair down and once with his hair back behind the ears. For the other subject, the data was obtained once while the subject was wearing glasses and once without the glasses.
Software Design
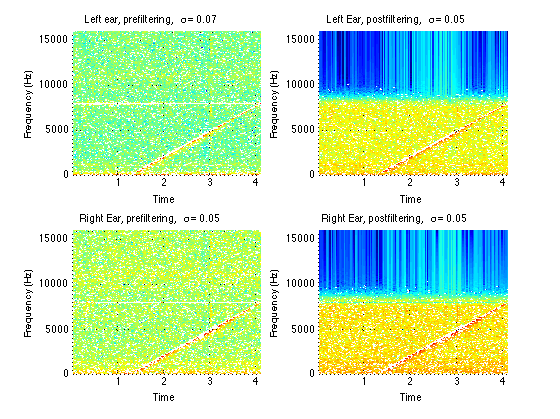
For data analysis, we use MATLAB to analyze the HRTFs for each subject. The data obtained from the data acquisition phase is first imported into MATLAB using the built in importdata() function.
After importing the audio data, to reduce the effects of backround noise in our testing environment, we filter it using a 50 Hz highpass, 10 kHz lowpass, and a series of notch filters designed to remove background noise from the room we tested in. Spectrograms of some of our acquired data, pre and post-filtering, are shown on the right. Our linear chirp function is the diagonal line increasing in frequency linearly over time.
To get a measure of the amount of energy in our measured signals at a given frequency, we used MATLAB to generate an estimate of the power spectral density (PSD) of the signal, as well as the variance (which is related).
For a given signal \(x\), the power spectral density \(S_{xx}(\omega)\) (equivalent to the amount of power in a signal at the frequency \(\omega\) is given by \[S_{xx}(\omega) = \lim_{T \to \infty}\frac{1}{2T}\mathbb{E}\left[|X(j\omega)|^2\right]\] where \(X(j\omega)\) is the fourier transform of \(x\). This equation describes the fact that the power spectral density is effectively a time average of the squared fourier transform of the signal (giving units of Volts squared per Hertz).
For a discrete time system like ours, where \(T\) is finite, we can gain an estimate of the PSD by, for instance, by breaking the signal up into \(N\) chunks, and then averaging (i.e., taking the expected value of) the magnitude-squared discrete fourier transforms for each chunk. This method of power spectral density estimation is called Bartlett's method. In MATLAB, the we used a variant of this called Welch's method, in which the chunks of the input signal overlap with one another.
To get a simplified, single number representation of the total amount of power in the signal for each ear, we simply took the variance of the signal. The variance for a time varying, zero mean signal \(x(t)\) is given by \[\sigma^2_x = \mathbb{E}\left[x(t)^2\right] = \lim_{T \to \infty}\frac{1}{2T}\int_{-T}^{T}x(t)^2dt\] By Parseval's theorem, this is equivalent to \[\sigma^2_x = \lim_{T \to \infty}\frac{1}{2T}\int_{-\infty}^{\infty}\left|X(j\omega)\right|^2d\omega = \int_{-\infty}^{\infty}S_{xx}(\omega)d\omega\] Thus, by taking the variance, we are effectively computing the integral of the power at all frequencies, giving us a measure of the total power of the signal.
To get information about the time difference of arrival (TDOA) of the signal between the microphones in each ear, we looked at the cross-correlation between the signals in the left and right ears, given by \[(x \star y) (n) = \sum_{m = -\infty}^{\infty}x(m)y(n+m)\] At the point where this function is maximized, the two signals \(x\) and \(y\) are most similar, and the corresponding index \(n\) describes the effective time difference between the two signals.
Our MATLAB implementation of these techniques consists of a set of script that import data, filter it, and calculate variance and TDOA for each angle. We also plotted colorized power spectral densities versus angle to gain insight into how the frequency content of the incoming signal is affected by the position of the head.
Results
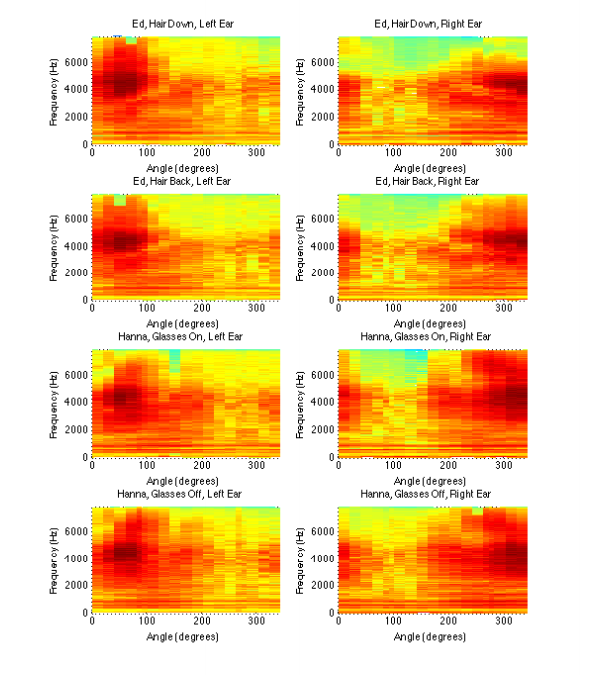
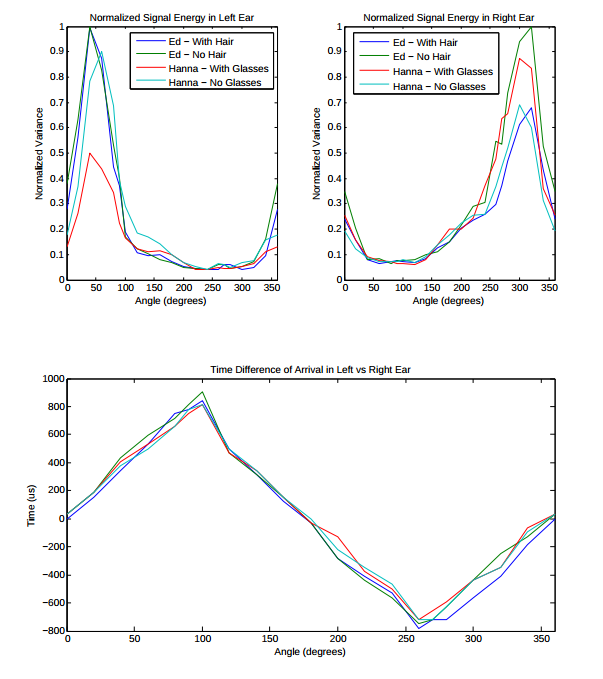
The post filtered data was taken and a set of plots were created to start forming approximations of the HRTF. The plots of interest were variance against angle, time difference between ears against angle, and power spectral density plots. The time difference between ears is necessary to understand how much of a delay occurs between the subject's ears and the variance plots give us relative power differences between the two ears. The power spectral density plots give us an idea if there is a frequency range which appears to be oppressed at various angles. Results of the plots can be seen below.
To remove noise in the input data, we originally tried to use denoising techniques like Wiener filtering. However, when applying such filters, we found that they tended to produce audible, unusual replicas of the desired signal that were displaced in time and frequency. Although the original signal of interest still dominated after applying such filtering, we found we could still remove ample amounts of noise and interference by using simple, fixed filters.
From the plots with the normalized variance versus angle, a factor of ten signal energy difference can be seen comparing the angle at which the ear was closest to the speaker (90 degrees relative to the speaker for the left ear and 270 degrees for the right ear) to other angles at which the ear was farther away. The plot showing the time difference of arrival between the ears shows a difference of up to 800 microseconds at around 90 degrees and 270 degrees. From the PSD plots, darker colors represent higher power spectral density, and it can be seen that the highest values overall are in the middle of the frequency range, and for the left ear the values appear at around 50 degrees and for the right ear, around 300 degrees. From the results, the HRTF is analyzed by comparing the input and output frequencies, time delays, and angles.
Interpolation
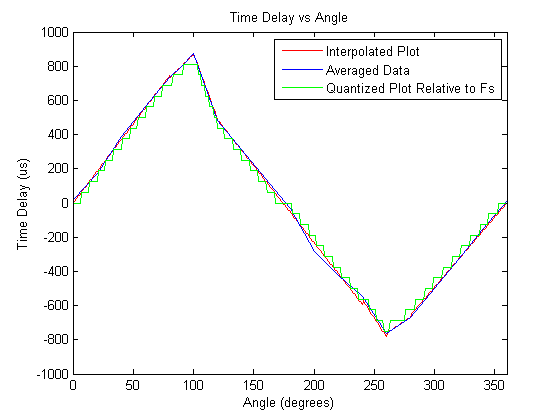
To create the approximations of the HRTF with regard to power and time-delay, the original plots were averaged and broken up into linear pieces where a simple curve fit was applied.
For interpolating the power plots, the first step that needed to be done was to take the square root of the power plot. This was done because the end system was using a microcontroller to control voltage outputs and the output power on the headphones equals the voltage over the load squared divided by the load resistance. Then all of the plots were average to each other and re-normalized so both the left and right ears had a maximum value of one.
The new normalized signal magnitude plots and the time delay plots were broken up into sections that appeared to be most linear and functions were found using the MATLAB GUI for curve fitting. These values were then quantized to generate a vector of 360 elements to store in a table in the microcontroller's flash memory. A plot showing the time delay is attached below.
These interpolation plots were used to create a MATLAB version of the HRTF to prove that the data could be used to create binaural sound before implementing it on the microcontroller.
System Implementation
System implementation involves the use of the previously analyzed and averaged HRTF and a designed class-D amplifier in order to produce spatialized sound to from a pair of headphones. The analyzed HRTF is implemented to alter an incoming audio signal to produce the spatialized sound at a certain angle which is determined by the users. The spatialized sound is amplified by the class D amplifier.

Hardware Design
The hardware for this part of the project is made up of the input audio amplifier, which amplifies and converts audio from the input source from stereo to mono, the MSP430 with a pair of digital to analog converters (DACs) which produce the HRTF modified version of the input signal, and an output amplifier used to drive a pair of headphones.
Audio Source Preamplfier
The audio source preamplifier circuitry takes in the left stereo and right stereo signals from the audio jack and combines them using a basic summing circuitry that is implemented with two resistors, both valued at 1 k\(\Omega\). The combined audio signals then pass through a high pass filter that has a cutoff frequency of about 10 Hz and re-biases the circuit to half the supply rail. The signal then pass to a non-inverting amplifier that also behaves as a high pass filter with a frequency of about 10 Hz. This second high pass filter is used to block the DC-gain of the amplifier. The gain on the amplifier is adjustable with a potentiometer to prevent the output from saturating and ruining the quality of our audio. The op-amp used in the circuit was the LM833P audio amplifier, which was selected for its low noise, high slew rate, and high-gain bandwidth product, which are important for streaming high quality music. The output of the amplifier feeds into a passive low pass filter which has a cutoff frequency of about 8 kHz, which acts as our anti-aliasing filter since our sampling frequency is 16 kHz. The output of the filtered signal is then buffered with the spare channel on the LM833P with a voltage follower. The signal is then sent to the microcontroller peripherals board.
Headphone Amplifier
To drive a pair of headphones based on the waveforms produced by the MSP430 (or in our case the DACs it controls) an audio amplifier is needed. The reason for this is because speakers tend to have a low impedance (on the scale of 10s of Ohms and lower). Headphones are not identical to speakers, as they tend to have a higher impedance, however they can also have very low impedances on the same order of speakers. Because of this a speaker amplifier is designed to have a low output impedance (to prevent power losses that occur from the resistive divider created by the amplifier and the load). The headphones used for implementing the binaural sound synthesis was the Razer Tiamat 2.2 headset which has an impedance of 32\(\Omega\).
The amplifier we decided to use was a custom-designed class D amplifier. An amplifier operating in the class D regime first modulates the incoming waveform in a way such that it essentially becomes binary (i.e., it switches between the supply rail and ground) while still containing the frequency content of the original signal. This waveform is then buffered by a set of switches, filtered (to remove higher frequency content added by switching), and then applied to a speaker.
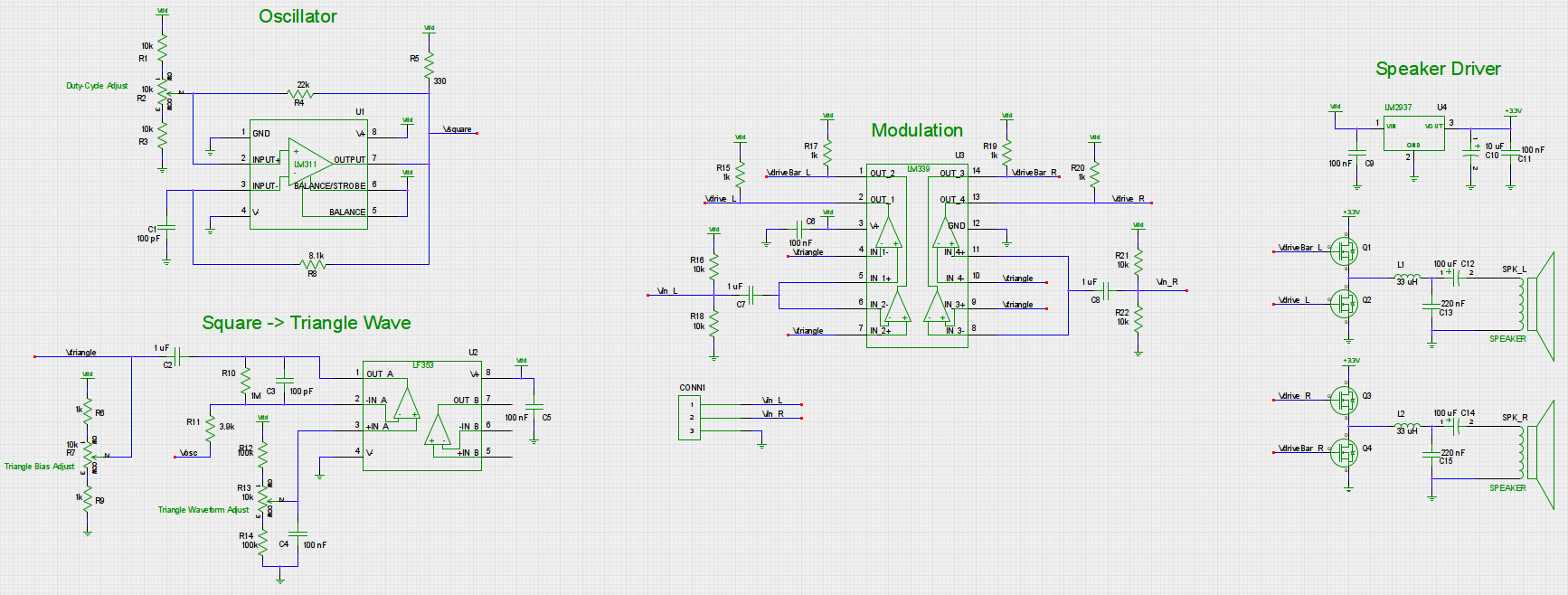
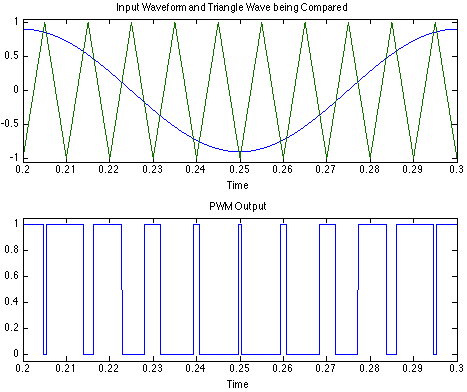
To generate a modulated version of the input signal, we used an analog pulse width modulator circuit, which generated a binary representation of the input signal by continuously comparing it to a high frequency triangle wave. Thus, the duty cycle of the effectively set by the voltage level of the input signal (an example of this is shown at the right).
In order to generate a triangle wave used for modulation, we used a square-wave relaxation oscillator operating at around 730 kHz, followed by an op-amp integrator. For our square wave oscillator, we used a comparator chip (the LM311) instead of an op-amp for faster operation (to avoid slewing). This was less of an issue for the integrator circuit, since it does not need to produce the steep square-wave edges, so instead we used an LF353 operational amplifier.
Since the quality of the generated triangle wave directly affects the amount of distortion in the output signal, we included three trimming potentiometers in the oscillator circuit to adjust the duty cycle of the square wave, the reference voltage used for the integrator, and the triangle wave bias voltage. These were tuned using an oscilloscope to produce the best waveform possible
The generated triangle wave is then compared with AC-coupled versions of the stereo input signal using an LM339 comparator, to generate non-inverted and inverted versions of the PWM waves for the left and right channels.
The PWM outputs of the comparators is used to drive a set of four MOSFET switches. In order to limit the volume of the output stage, we used an LM2937 Linear Regulator to generate a +3.3V output power rail (versus the +6V rail for the rest of the circuit). This was also convenient in that we did not need to perform any level shifting in order to drive the high-side FETs, since the maximum source voltage is +3.3V and the gate voltage was driven up to +6V.
The output of the FETs is then filtered with an LC lowpass filter (with a cutoff frequency of ~59 kHz) to remove switching noise, and applied to headphone speakers through a large DC-blocking capacitor. The resistance of the speaker itself is used to dampen any potential ringing in the LC filter (for an 8 \(\Omega\) speaker load, this corresponds to a Q (quality factor) of ~0.65, or slightly less than critically damped).
Software Design
For the system implementation portion of our project, we use C code running on the MSP430 to implement amplitude changes, time delays, and simple low-pass filtering intended to mimic the HRTF.
Once the MSP430 recieves the start command (signifying that it should start processing incoming audio), it changes the timer interrupt frequency to 16 kHz and starts sampling data from one of the internal ADCs. Only one channel is necessary for this part because the audio from the input source is converted to mono by the input audio amplifier.
When the MSP430 enters the timer interrupt handler it first gets the result of the previous conversion and adds it to a sample buffer. To generate relative time delays between the sounds going to both ears, samples to be sent to the DAC are then taken from this buffer at indexes that are offset from one another according to the angle the system is trying to emulate. After that, the sample for each ear is scaled according to what the relative amplitude should be. The samples are then put through a simple, two tap FIR averaging filter (with coefficients [0.5, 0.5]) selectively depending on the angle. Finally, the ADC conversion to get the next sample is initiated, and the processed samples are written to the DAC.
To store what the time delays between what the two outputs should be, we use a 360 element long array, where the index is the angle we are emulating. This array contains offsets (in number of samples) that can be positive or negative. Data for the left ear output channel is taken at the midpoint of the input buffer, and data for the right ear channel is taken from the midpoint plus the delay value.
Similarly, to perform the appropriate amplitude scaling, we use a 360 element long array containing amplitude values corresponding to angles from 0 to 359 degrees. These amplitudes are multplied by the time delayed versions of the input samples for the left and right outputs. Since the amplitudes are obviously different for each ear, but are symmetric, we used a single array of amplitude data that we indexed normally for one ear, but then reverse-indexed for the other (i.e., we used the index (360 - angle) % 360).
Finally, if the angle to be emulated fell within the region where the head acts as somewhat of a lowpass filter, we applied the simple averaging filter to produce the output sample.
As we are processing audio, the angle which the system emulates can be set using the UART interface by simply sending any decimal number between 0 and 360. Additionally, by sending the sweep, the system increments the angle by 15 degrees every half second or so, making the output sound like it is traveling around the users head. This mode can be exited by setting the angle to any constant value.
The stop command can be used to exit the audio processing mode. A summary of all UART commands most relevant to this portion of the project is given below.
| Command | Purpose |
| <Decimal#> | Set the emulated angle to the given number |
| start | Start processing audio |
| stop | Stop processing audio |
| swirl | Begin periodically changing the emulated angle |
| testdac | Executes a DAC test, sweeping the output linearly from zero to the maximum output voltage |
Results
The HRTF obtained from the previous section was successfully implemented, and music played into the device could be spatialized to particular angles on the azimuth relative to the subject's head. The output signal of the device was noticibly degraded due to noise and because of the low sampling frequency, which caused much of the high frequency content of the music played to be omitted.
A sound clip of our system processing music in real time is included above (or can be found here if your browser does not support it). The clip begins with the angle set initially to zero, then 90 degrees, 180 degrees, 270 degrees, and finally back to 0. Then, the angle is swept in 15 degree increments automatically by the system. There are a few noticable discontinuities and clicks, which are mostly a result of the approximations we made implementing the system on a microcontroller with limited computational resources. Much of the highest frequency content is also missing, given our limited sampling frequency. However, the music is still very much recognizable, and the intended effect is produced. We have found that the effect is maximized when listening with over-the-ear headphones (i.e., not earbuds), and may be hard to notice if not using headphones at all.
Conclusions

Our system was able to successfully analyze individual HRTFs for different subjects, although the noisy data made it difficult to make comparisons between individual HRTFs and give reasons for these variations. The system was also able to produce binaural sound by streaming an audio input, converting the data into mono sound, sampling the audio data, performing the HRTF on the microcontroller, and playing the sound on a pair of headphones.
Future Improvements
Overall the project was successful, but there was room for improvement in different subsections of the project. One main issue with the data analysis is that the environment was fairly noisy since we did not have easy access to an anechoic chamber. Although our test set up was done in a large open room, there was a lot of background noise produced by fans and other equipment that was running in the room. This lead to a lot of background noise that was picked up by the microphones. Furthermore, taking more data points would have helped improve the accuracy of our results.
Another issue in the data acquisition hardware was that we did not have a high order anti-aliasing filter. This lead to the region of interest of the FFT of the data being corrupted at high frequency sounds. This would have needed to be implemented in hardware because there was not enough time for the microcontroller to maintain a high sampling frequency and perform digital filtering.
Furthermore, the method of obtaining the HRTF with the experimental set up could have been improved. The microphones being placed in the subjects ears could have been made more comfortable, and the microphones could have been smaller which would have allowed the microphones to be placed deeper in the subject's ears to get a more accurate representation of what our ears detect.
During the data analysis section when the MATALB version of the HRTF was being created, we could have used the built in functions in MATLAB for performing a cubic spline interpolation. The reasons we did not perform this was because the original design for implementing the HRTF in the microcontroller was to use mathematical formulas. Therefore to reduce the processing load, linear functions were being created with using bit-shifts when possible to limit using the hardware multiplier to save clock cycles. However, after working on the firmware implementation for this, we realized that it was best to use the copious amount of flash memory to store look up tables relating to the HRTFs.
On the HRTF synthesis component of the project the final output filtering for the amplifier circuitry should be redesigned. With the headphones used for the experiment the quality factor of the circuit was about 2.5, which means the system is slightly under damped and that there is ringing occurring at the cutoff frequency of the filter. Although this did not cause noticeable distortion on the audio output (since the cutoff frequency is around 59 kHz which is beyond the human hearing upper limit and below the switching frequency of the class D amplifier) it would have been better to design the filter to be over damped.
On the firmware implementation of the HRTF there appeared to have been a transient glitch which caused a clicking sound in the headphones to occur every time the angle changed. This was most likely caused by changes in the angle causing different multiplication factors to give a DC-offset to the output signals. The small DC-component change would appear as a transient component which would give a clicking sound. Some sort of smoothing operation could be performed in either software (remove discontinuities) or hardware (capacitive shunt) if there was more time to thoroughly diagnose the problem.
Although the aim for this project was to implement a low cost system to perform the data acquisition and HRTF synthesis, it could have also been implemented on a more power processor such as an FPGA or ARM processor. This would allow for much higher sampling frequencies to get more accurate data as well as applying more on embedded filters before retrieving the data. The HRTF synthesis would be able to be implemented with mathematical functions, instead of lookup tables, to get more angle precision.
Intellectual Property Considerations
All of the intellectual property regarding the implementation of the experimental setup and the binaural sound synthesis belong to us because we did no actively search for patents or current implementations for the design. We did not sign any non-disclosure agreements to obtain any of the parts that were sampled for the completion of this project. Code from the public domain or open source projects was also not directly used for this project (We did use open source programs like make and msp430-gcc for the purposes of generating our own software).
Furthermore, we are open to the idea that other research/project groups can use our design as a building block to make further improvements to the design to fit their application needs.
Ethical Considerations
Throughout the entire process of developing our project, we strived to maintain the highest degree of ethical integrity, as dictated by the IEEE code of ethics. We kept safety for ourselves and for others in mind at all times, by especially trying to minimize as much as possible any hazards related to our hardware (like exposed wires or sharp edges). Before any testing was performed with any of the sub-systems connected to our test microphones, we made sure that it was operating safely. We also tested the headphone amplifier with and without speakers extensively before actually using it with a person wearing headphones, to ensure that no potential hearing damage could occur from excessive volume or other unwanted signals.
While constructing our project, we took appropriate precautions while dealing with potentially hazardous tools like soldering irons and files by wearing safety glasses and ensuring the materials being worked on were securely held in place.
We have attempted to give due credit to all those helped in the construction and design elements of our project, and we are releasing the entirety of the source code for our project under the GNU GPL with the hopes that it might be of use to anyone else attempting to construct a similar system.
Legal Considerations
Our project does not use or produce wireless communication so we are not in violation of any FCC legal regulations. Our system is not intended for medical use. Therefore, we are not in violation of any medical device regulations.
Appendix
Commented Code Listing
A full copy of our repository code can be found here. All of the MSP430 code is contained in the firmware directory, and all of the MATLAB code we used for data acquisition and analysis is contained in the matlab directory.
Schematics
Audio Preamplifier

MSP430 Breakout
Speaker Amplifier
Task Distribution
| Patrick | Ed | Hanna | All | |
| Mic. Pre-Amplifier Board Design | X | X | ||
| Mic. Pre-Amplifier Board Build | X | |||
| Microcontroller Breakout Board Design | X | X | ||
| Microcontroller Breakout Board Build | X | |||
| Audio Pre-Amplifier Board Design | X | |||
| Audio Pre-Amplifier Board Build | X | |||
| Class-D Amplifier Board Design | X | |||
| Class-D Amplifier Board Build | X | |||
| Mechanical Assembly | X | X | ||
| System Wiring | X | |||
| MATLAB Scripts | X | X | ||
| MSP430 Software | X | |||
| Website Design | X |
References Used
Budnikov,D.,Chikalov, I.,Egorychev, S.(2005) US Patent No. 0069143 A1
Chen, P., Lau, H. (2006) US Patent No. 71167881 B1
Pec, M., Bujacz, M., Strumillo, P.(2007) Personalized Head Related Transfer Function Measurment and Verification Through Sound Localization Resolution.15th European Signal Processing Conference.Poznan, Poland. 2326-2330
Wenzel, E., Arrua, M., Kistler, D., Wightman, F. (1993) Localization using nonindividualized head-related transfer functions.Journal of the Acoustical Society of America. 94.1:111-123
Datasheets
- MSP430G2553
- MSP-EXP430G2 LaunchPad Experimenter Board
- TLV5616C Digital-to-Analog Converter
- 23A1024 Serial SRAM
- LF353 Operational Amplifier
- WM-64C Microphone Cartridge
- MCP6001 Operational Amplifier
- LM2937 Voltage Regulator
- MAX3233E RS-232 Transceiver
- LM339 Voltage Comparator
- LM311 Comparator
- FQN1N50C N-Channel MOSFET
Vendor Sites
Acknowledgements
We would like to thank Bruce Land for his guidance on the ideas behind this project. We would also like to thank the developers of the gEDA, msp430-gcc, and mspdebug projects, whose free software we utilized extensively, and Bitbucket for their free git repository hosting services.