
Introduction
Conway's game of life is a 2D cellular automaton. This project implements Conway's game of life on an Altera Cyclone II FPGA using a DE2 development board, at full VGA resolution.
Overview
The main goal of this project was to implement Conway's game of life on a grid of 640x480 cells, running at 60Hz. This would be full VGA, and updated as fast as the monitor can display the grid. However, this poses the first and largest design hurdle: Updating that resolution at that rate requires over 18 million updates per second! This leaves just a few clock cycles per cell for updating. Given that each cell requires 9 values to calculate it's next value, even with extreme pipelining serial updating would not be possible (without over-clocking).
My design uses massive parallelization to achieve the required speeds, and is more than capable of faster. More on this in the next section.
Also, user interactivity was a major consideration, but ultimately didn't get implemented due to technical difficulties. The game of life is much more interesting if it is interactive.
High Level Design
Memory
Due to the speed requirements, I choose to use M4K blocks, as they are dual ported (both the VGA and my Hardware can read/write) and fast. They can also be made highly parallel using one block per parallel unit:
Parallelization
I split the grid up into columns, 8 cells wide. This resulted in columns of 8x480 cells. I picked 8 because it uses the M4K blocks efficiently (one per column), and the X grid location can be easily split into a column reference and location within the column (highest bits and lowest 3 bits, respectively).
Each column contains the logic to do calculations, and a state machine that will calculate a given row when triggered. I also have a larger control module that controls and synchronizes these columns. The control module is the only module the columns directly interact with.
The control module triggers all of the columns to calculate a row in parallel the moment the VGA module finishes rendering a row. This keeps the calculation and VGA in sync. The control Module allows the rate of calculation to be controlled. This is done by skipping frames, e.g. 60Hz (0 frames skipped), 30Hz (1 frame skipped per frame calculated), 20Hz (2 frames skipped), 15Hz (3 frames skipped), and so on. The number of frames to skip is chosen using SW[17:10]. There is a lot of time where the columns are not dong any calculation, so the system itself is capable of much faster speeds, if we were to decouple the calculation from the VGA scanning.
Here is an animation of how the grid is updated in parallel. As you can see, all columns finish updating the row with plenty of time to spare. I wouldn't be surprised if this system could handle much higher frequencies (200+Hz). The goal of synchronizing the updates to the VGA scan is to remove any flickering and distortion.
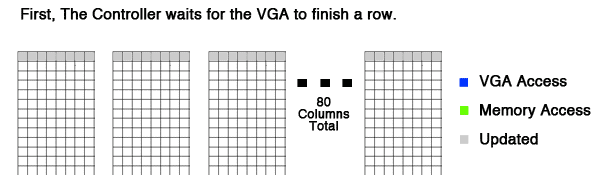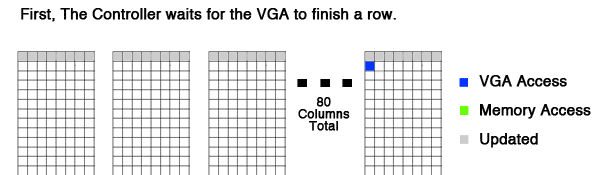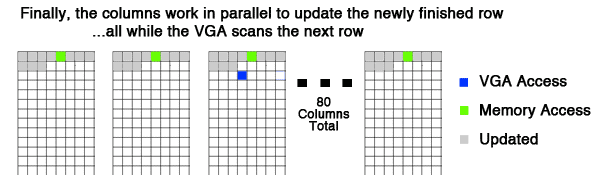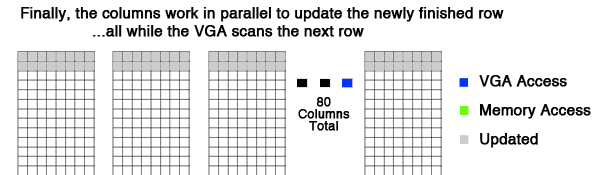
Figure 1: An animation to explain the basics of the parallelization scheme.
The above Animation is not completely accurate due to two missing details:
1. Memory is not read from calculated cells (as this will screw up the automata). Instead, the previous row is contained in a buffer of registers.
2. The animation does not account for memory pipelining.
Overall, Figure 1 is a great demonstration of the speed and logic behind the parallelization.
Interaction
The most intuitive control is using a mouse and cursor, and I insisted on implementing any interactivity using a mouse and cursor. However, Due to limited time and lack of up-to-date documentation, the Interactive aspect was removed from the project, but much of the interface has already been implemented. Even with this aspect removed, there remains interactivity by choosing one of four initial states. These are chosen using SW[2:0]: Fully Random (initializes the screen with random bits), Half Random (initializes half the screen with random bits), Middle Random (initializes the center of the screen with random bits), and Pre-set (a small pre-set pattern in the center of the screen). All of these states are shown in videos at the end of this document.
If external input was to be added, it would be though a NIOS II processor. The NIOS II would interact with the data though the controller. It first has to stop the controller by pulling the "run" input low, then wait for the "running" output to go low. This allows the controller to complete the current frame and stop gracefully. After the controller has stopped running, the NIOS can input data via "override_x", "override_y", "override_data", and "override_clk". These inputs control which column, row, and value to input (first three respectively), and the "override_clk" allows the NIOS to pulse the control module, notifying that data is ready.
A mouse would give input to the system via the NIOS. The mouse cursor is outputted from the NIOS to the VGA controller. The VGA controller handles the rendering of the cursor. Upon click, the NIOS will modify the data under the cursor using the method described above.
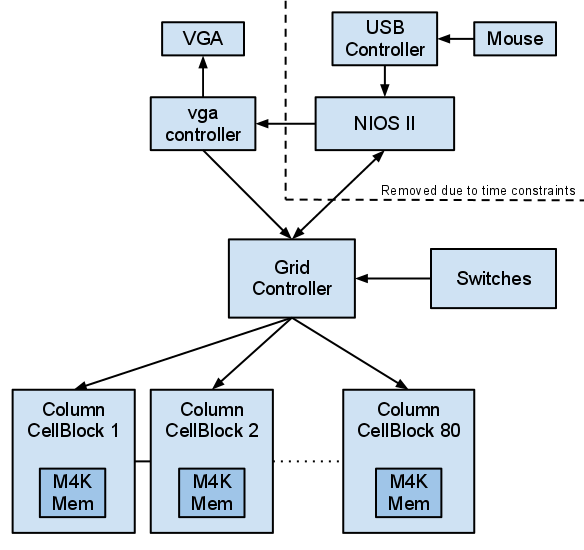
Figure 2: High Level Layout.
Hardware Design
As talked about in the high level design, I've created two new hardware components: Cell Blocks (columns) and a Grid Controller (column moderator).
Cell Blocks
Each cell block (column group) is capable of calculating a row mostly independently. I say mostly, because they are interconnected between each other - they need to communicate the boundary values.
This is done using a state machine with three major phases: Waiting for Sync, Initialization, and Main Loop.
note: "lower-left edge" and "lower_left" are two different things. "lower-left edge" is the lower-left value to be shared with this block's left neighbor. "lower_left" is the lower_left value relative to the current row and col location.
Waiting for Sync is when the cell block is waiting for the Grid Controller to trigger calculation of a row. This section contains one state:
wait_for_sync: waits for sync pulse, while clearing the bottom row (for consistency). Also sets row and resets col.
Initialization is after a row has started, but before calculation begins. During this phase boundary values are loaded and any variables are initialized.
start0: updates prev_row, pipelines middle-left edge
start1: sets upper-left and upper-right edges based on prev_row,
pipelines lower-left edge.
start2: pipelines middle-right edge.
save_middle_left: Saves value to it's proper locations, and pipelines lower-right edge.
save_lower_left: Saves value to it's proper location.
save_middle_right: Saves value to it's proper location.
save_lower_right: Saves value to it's proper location.
load_neighbors: Saves values from left neighbor to {upper,middle,lower}_left registers.
Main Loop is when the row is being calculated. This section is looped over per pixel in the row, until the row is complete.
load_phase0: checks to see if it's the final column, if it is it loads right neighbor values
and skips to calculate,
else, it sets upper_right from prev_row and pipelines middle_right from mem.
load_phase1: Pipelines lower_right from mem.
load_phase1b: Delay for proper pipelining.
load_phase2: saves middle_right
load_phase3: saves lower_right
calculate: does the logic, and saves the result to the results vector
save_phase: commits the recent result to memory, and checks to see if we're done
returns to wait_for_sync if we are done.
shift_phase: Increments col, and shifts values to the left. returns to load_phase0
The cell blocks also contain a single M4K block - just enough memory to contain an 8x480 array of bits. These M4K blocks are fully dual ported, to allow the VGA to simultaneously read cells as rows are calculated. However, the Dual-ported design is too slow for the VGA controller, so a buffer system has been implemented. This system is a simple state machine that prefetches the next row, so when the VGA requests the data, it'll already be loaded into logic elements.
Grid Controller
This is the main controller for all of the Cell blocks. It also contains a state machine. This controller handles the logic of overrides, if we were to implement an external data modifier. Note that a "frame" refers to one full screen scan by the VGA.
States:
not_running: check irun and override inputs, and reacts accordingly
apply_override: state while applying an override value
wait_for_frame_start: waits for VGA_y == 'd0; also monitors irun
frame_start: Checks # of frames skipped, and decides to skip or init.
frame_start_skip: waits for VGA_y != 'd0, then goes back to wait_for_frame_start
frame_start_init: does initialization for a new frame.
wait_for_row_complete: Waits for VGA_y to finish a row to calculate it.
execute_row: Runs Cellblocks on newly completed row (raise sync to high)
execute_row2: lower sync to low; if VGA_y is currently 'd0 (frame complete), return to wait_for_frame_start instead of wait_for_row_complete.
Design Challenges
Parallelization
My first implementation was serial, and I quickly realized I had to make a choice: Reduce the size/update rate, or redesign the system to parallelize the work. I opted for the second, challenging myself and keeping the original ideas intact. This increased the workload, so other frivolous things, such as loading a predesigned pattern, was removed.
Input
Interaction with the computer was removed, due to time limits. The original design was to use a mouse, and I insisted on using a mouse. I put a lot of time into trying to get it to work, and couldn't get it working. I tried PS/2, USB, and Serial (RS-232) mice, all of which lacked documentation, or if the documentation did exist it was severely out of date. Although I couldn't get the mouse working, the rest of the system is already prepared for it.
DE2 Board
For an extra challenge, I did not use the DE2-115 board we had available, and I wanted to see if I could make this computationally intensive task work with the limited resources of a DE2 board. It posed a challenge in many aspects (Number of logic elements, M4K blocks available, etc.), but all of the challenges posed by the DE2 board were overcome.
Clock
For simplicity, everything in the system is clocked off of the VGA clock. This means that there is only one clock cycle per pixel. Again, this limitation was overcome using Parallelization. Clocking higher was considered, but disregarded when it was realized that parallelization would need to be implemented regardless.
Conclusions
With the limitations imposed by an FPGA, such as a slow clock rate and limited memory, this project has shown that it is possible to calculate Conway's game of life at full VGA resolution at 60Hz using a highly parallel implementation. This parallelization scheme is also capable of much higher update rates.
Media
Code
The full Quartus II project can be downloaded here.
Note: the VGA_640x480_m4k_DLA.v file is the one that contains all of this project's code.
Screenshots

click to enlarge