Fluid Flow Simulation with Musical Stimulus
ECE 5760
A Project By Divya Gupta, Brendon Jackson, and Brian Ritchken
Demonstration Video
1. Introduction
We implemented a beautiful full-resolution fluid flow simulation based on the Lattice-Boltzmann structure which responds in real-time to musical stimulus. We achieved this using Verilog and C code compiled for an Altera-DE1 SoC. The C code runs on an ARM-based hard processor system (HPS), performing a Fast Fourier Transform (FFT) on audio input received from a microphone port. The resulting frequency information is sent via a Qsys bridge to an off-chip SDRAM so that it can be processed in real-time by a Lattice-Boltzmann solver running on the FPGA. Finally, this solver stores fluid flow information to a dual-ported SRAM, which is used as a VGA buffer to display the resulting solution on a 640x480 monitor.
2. Design
2.1 High Level Overview
Our project motivation came from a desire to combine our interests in musical and visual expression with a computationally intensive application that could be parallelized on an FPGA. We developed an interest in Lattice-Boltzmann methods from Bruce Land’s investigation of a software implementation in Matlab on the course website. Our system design was inspired heavily by the architecture for a hardware implementation of Lattice-Boltzmann methods presented by Nowicki and Claesen (2010).
We believe our design is novel and interesting since it combines a Lattice-Boltzmann solver with musical stimulus and implements a unique architecture utilizing buffer windows and off-chip memory in order to achieve 640x480 resolution. This project was for our personal enjoyment and learning; we do not intend to pursue any patents or commercial development associated with this work, and we do not believe our design infringes upon any existing patents or trademarks. In the development of this project, we comply by all applicable IEEE standards.
2.2 Mathematical Considerations
The structure of Lattice-Boltzmann solvers resembles a large rectangular grid of cells, or nodes. Each node models the fluid flow in various directions, and these flows propagate from one cell to its neighbors every time-step. At each node x and time t, eight distribution functions fi(x,t) describe the expected number of particles moving in one of eight directions. These directions correspond to the 8-connected neighbors, and are described by vectors ei. One final distribution function is used to indicate the number of particles which, at the given time step, remain stationary at each node. Lattice-Boltzmann solvers typically model the movement of fluid particles with two operations: propagation and collision. In the first stage, fluid particles propagate from one node to a nearby node, where they then collide with any particles in that node. The collisions alter the magnitudes of the distribution functions for the next time step, preserving both mass and momentum. These operations are encapsulated in the following formula, which yields the new distribution function fi(x,t) given the state at a previous time-step:
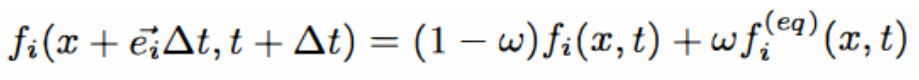
where ω is a relaxation parameter used to transition between the previous and current state, and fi(eq) represents the equilibrium distribution function which is reached after the collision has settled.
The simplified equilibrium distribution functions proposed in our reference paper[1] are as follows:
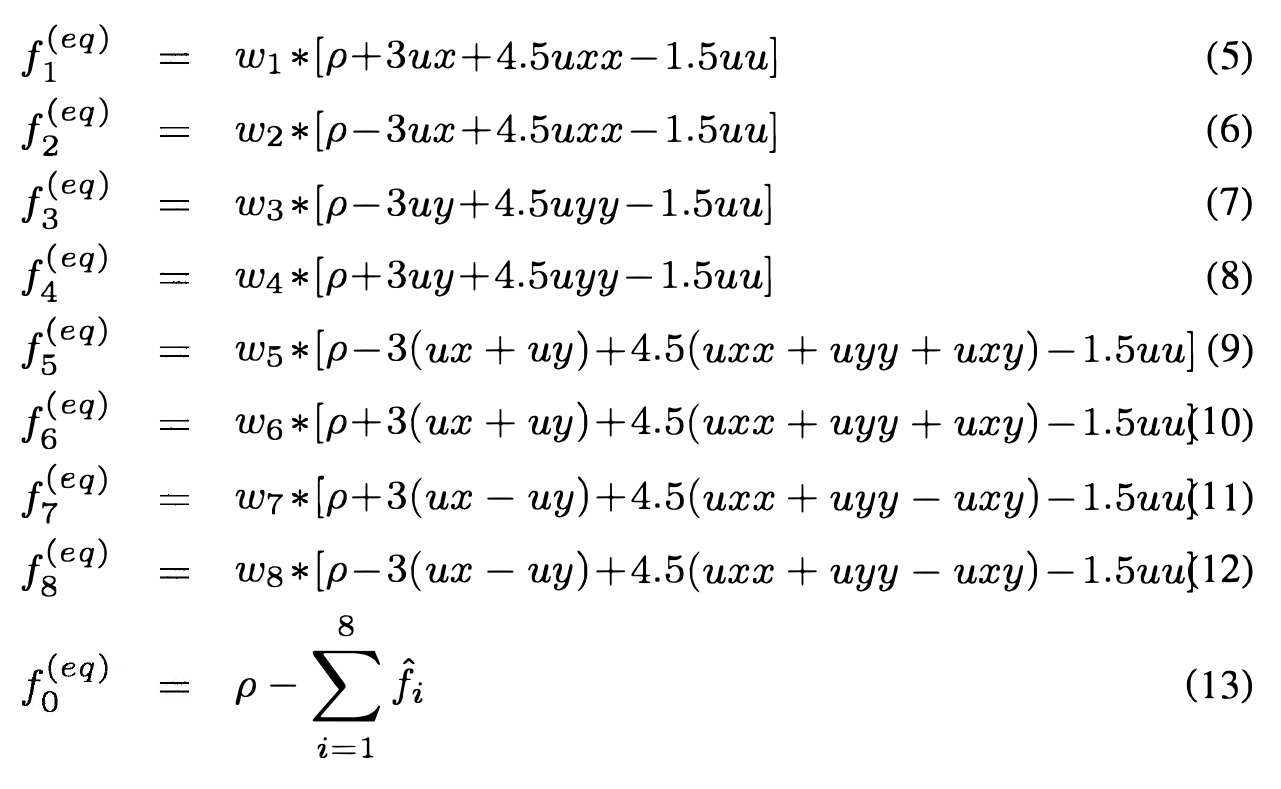
where:

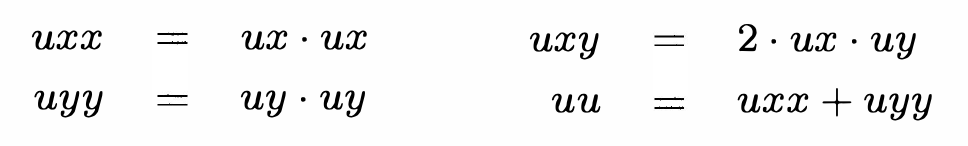
In order to implement these equations in hardware, we needed to decide on a number format. We elected for 16-bit fixed-point format with two integer bits and fourteen fractional bits, in order to accommodate the 16-bit off-chip memory available. We believe that this choice offers enough precision to maintain calculations, although in practice we noticed that after a long time, mass begins to dissipate as the fractional bits are truncated as the fluid particles flow.
To improve the stability of our design, we use signed 32 bits to maintain the intermediate results uxx, uyy, uxy, and uu. Unlike the fluid densities, these variables can take negative values, and it is critical that these variables do not overflow or underflow because they are used in the calculations of all of the fluid densities. Moreover, the value uu which corresponds to the sum of the squares of the fluid velocities is used to determine the color of the pixel drawn to the screen.
2.3 FPGA Design
2.3.1 Block Diagram
For this project, the FPGA fabric is responsible for updating the Lattice-Boltzmann solver in real-time and displaying the result on the VGA display. The overall block diagram is depicted below.
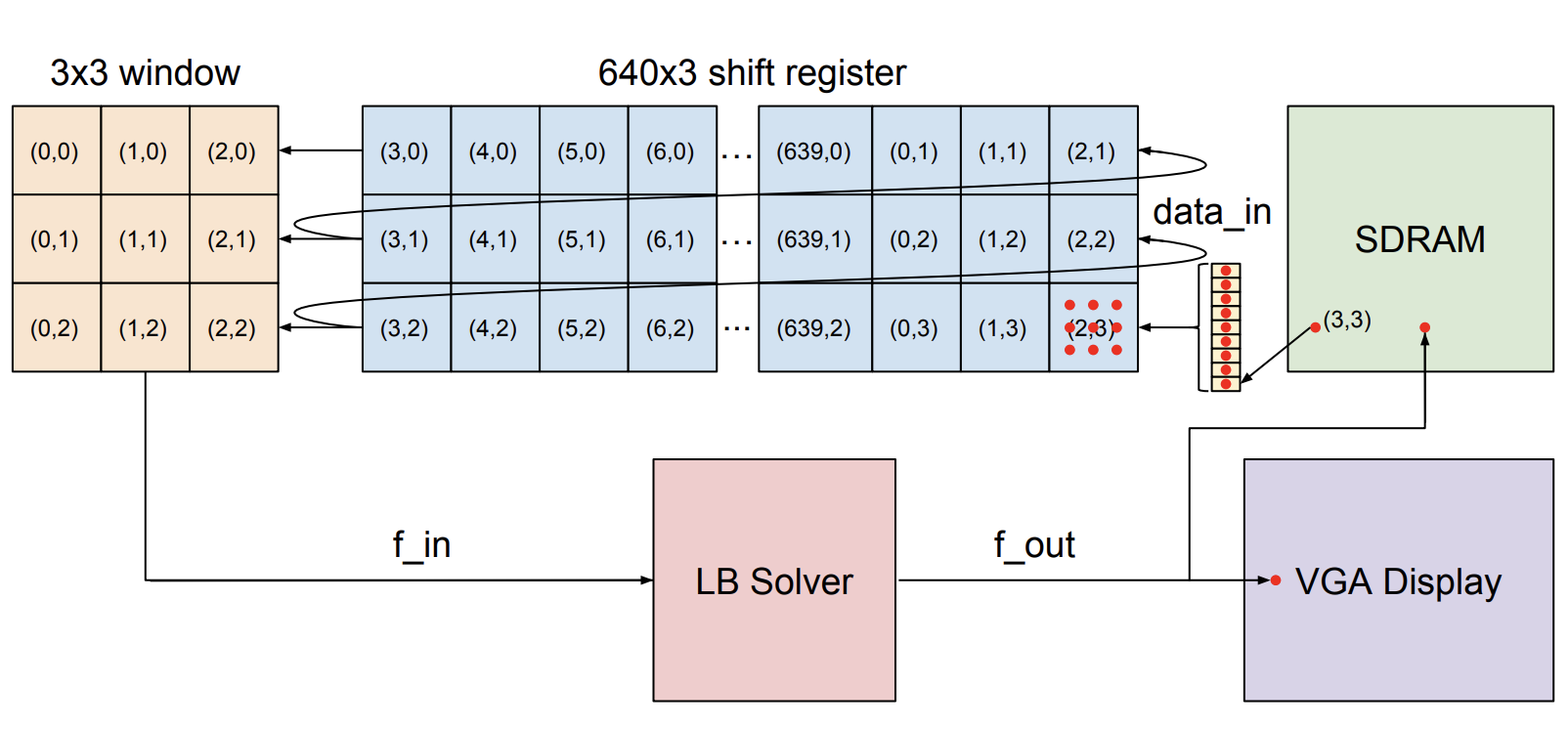
At a high level, the design on the FPGA comprises a single Lattice-Boltzmann solver, and an array of dataflow control mechanisms to provide the solver with necessary values as quickly as possible. Each pixel corresponds to one node in the simulation. Therefore, in order to compute the values for the next iteration at a single pixel, the solver needs a total of 9 values: one which describes the number of particles currently at that node, and one from each of the nodes’s eight neighbors which describes the number of particles that will stream into this pixel on this iteration.
In order to provide these 9 values as seamlessly as possible, we combine two data structures: a shift register with three taps and tap distance of 640 and a 3x3 window module. These work together beautifully as we solve pixels across the screen from left to right, one row at a time from top to bottom. The shift register is necessary because it enables us to prevent duplicate reads from memory. Once the nine values which describe a node are loaded from memory and the first is used as a neighbor, the other eight values are going to need to be read relatively soon (seven of them will be read as a neighbor and one will be used for the center value for that pixel). Rather than having to read them again from memory, we load them into a shift register which spans three rows of the VGA display - just long enough so that all nine values can be read without having to access the SDRAM again.
While the shift register buffers data between rows, the window is responsible for buffering the nine values locally. Any time a node’s value is required, it will be required twice more immediately. The window module simply holds onto values for two additional cycles, so that by the time the data is shifted out of window, it is no longer needed for any calculations on the current row.
All put together, it works as follows. Data flows from the off-chip SDRAM into a buffer named data_in. This buffer has nine slots for the nine 16-bit values necessary for every node. As it fills up, it waits for nine corresponding reads from SDRAM to bring in data for the next node. Once the data_in buffer is filled, the entire node is clocked into the shift register. Both this shift register and the window are only clocked when all of the calculations for one pixel are finished. Therefore, values which are shifted into the shift register will not be used for at least 640 cycles, which is the time at which they reach the first tap. When a node reaches the first tap, it enters the right-most block of the window module and the right-most block of the shift register on the above row. For the next three iterations through the state machine (described below), one of the eight values for that node will be used from window. Then, the node will be pushed out of window, and will only be used when it reaches the next tap 637 cycles later.
Given the correct input to the solver, it is responsible for producing 10 values: the nine updated values which correspond to the current node, and the 8-bit color which is to be displayed on the screen. To interface with the VGA display, we re-used the setup from our previous labs: a dual-port SRAM with 8-bit color and sequential addressing.
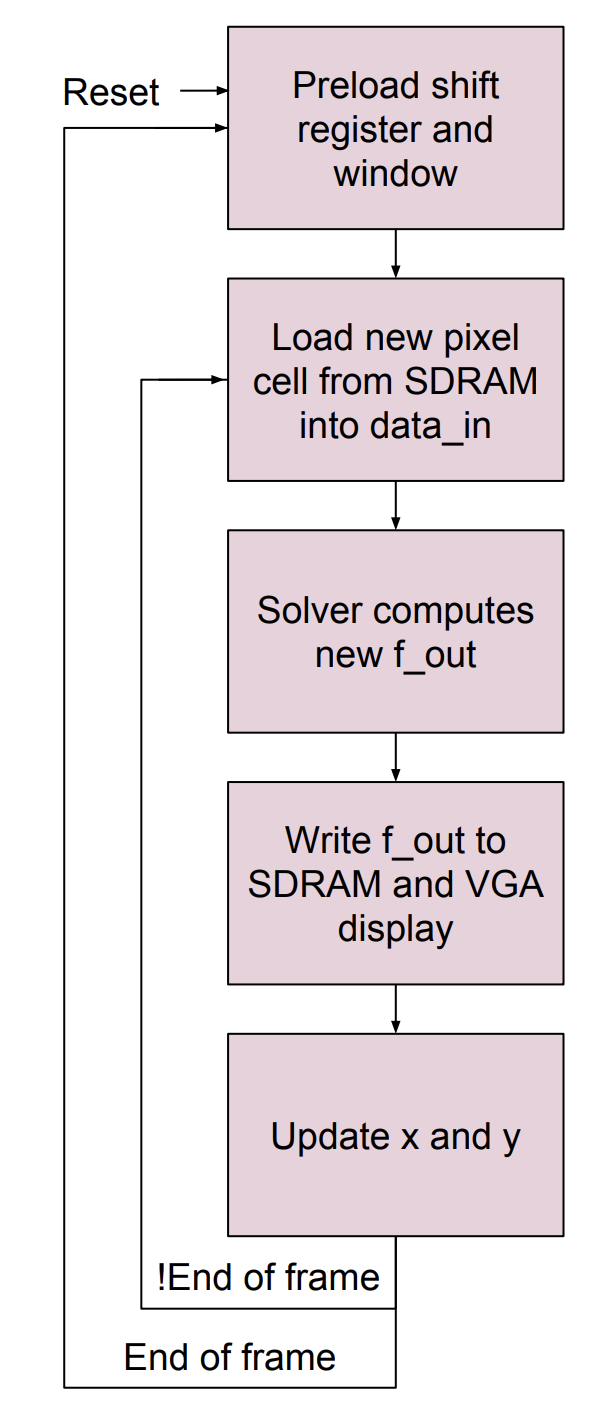
2.3.2 State Machine
A finite state machine (FSM) based controller directs the flow of data through the system. At the start of every frame, the state machine must fill up the shift register and window so that all data necessary to compute the first pixel of the frame can be fed into the Lattice-Boltzmann solver module. This entails loading the first three rows of pixels as well as the first three pixels of the fourth row into the shift register so that the window buffer is entirely filled. During the warm-up phase, a sequence of nine SDRAM reads loads the data_in register with values corresponding to next pixel to enter the shift register. Once all nine values have been read in, the pixel’s data is shifted into the shift register at the same time the data for the first value for the next pixel is being read into data_in. A snapshot of the system state at the end of this warm-up phase is depicted in the block diagram in the figure to the right.
Following this warm-up phase, the state machine progresses by moving one pixel at a time. First, the next pixel’s data is loaded into data_in but not yet pushed into the shift register. Meanwhile, the Lattice-Boltzmann solver is performing the computation on the pixel that has been fed in from window. We allow one additional cycle for this computation to finish, and then we write the result from the solver back to SDRAM as well as to the VGA display. Note that the pixel being computed and then stored is different from the one that is loaded from SDRAM into the data_in register in the same iteration of the state machine. Therefore, there are two sets of x and y coordinates to keep track of pixels on which we are operating. Once the write acknowledgment is received from the SDRAM, the state machine updates the x and y coordinates corresponding to both pixels. If the coordinates corresponding to which pixel is being read from SDRAM into data_in indicate the end of a frame, then the state machine returns to the first state to perform the warm-up phase. Otherwise, the state machine returns to the regular read state. The state machine is running at 50 MHz system clock.
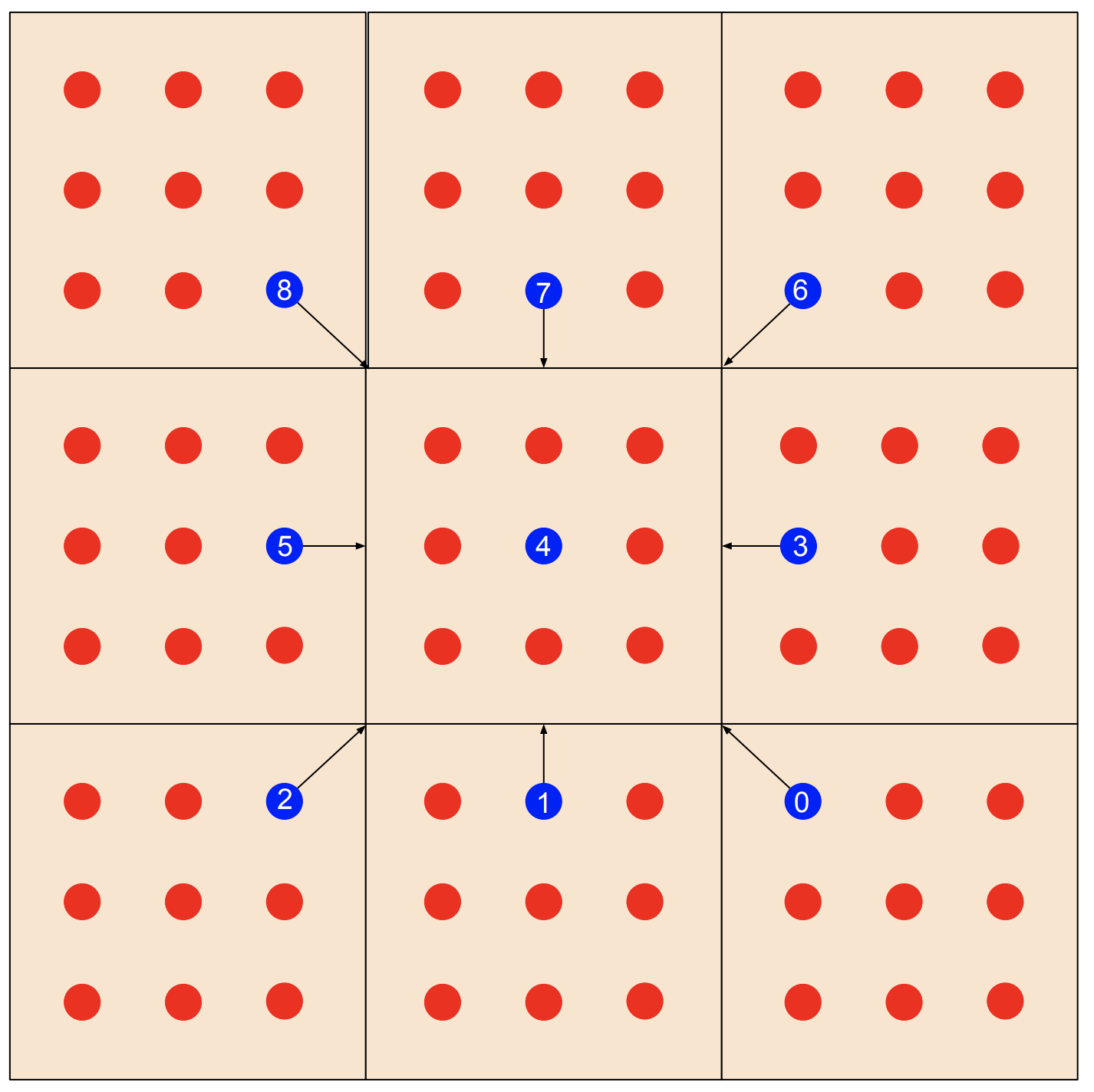
2.3.3 Solver Module
Section 2.2 covered the mathematical background of the Lattice-Boltzmann solver. In this section, we will discuss implementing the Lattice-Boltzmann solver in hardware. The input to the solver module is f_in, a 3x3 grid of pixels shown below which is output from the window buffer. The solver is operating on the pixel in the middle of the grid. The solver outputs f_out, which is the data corresponding to this pixel at the next time step that will be written back to SDRAM as well as the magnitude of the fluid velocity, which is mapped to the color that will be displayed on the VGA monitor. The solver computes fluid density, ⍴, by summing the particles propagated from each of the neighboring nodes as well as its own center stationary particles. These particles are represented by the blue dots in the figure below. It then computes the x and y components of the fluid velocity vector u by subtracting the sum of the propagating particles moving in the negative direction from the sum of propagating particles moving in the positive direction for both axes.
We implemented a signed multiplier module using 2.14 fixed-point format and instantiated it three times in the solver module to obtain the partial products uxx, uyy, and uxy, which are used to calculate f(eq). To avoid taking a square root, which would be a costly operation in hardware, we output the squared magnitude of the fluid velocity, uu = uxx + uyy, which is accordingly mapped to color on the VGA display, as discussed in the next section.
2.3.4 VGA Display
In order to maintain a high-bandwidth connection between the solver and the VGA display, we used the provided code on the course website which maintains a dual-port SRAM for the VGA buffer. Using this configuration, one port is connected through Qsys to the VGA controller and HPS, while the other is directly exported to the FPGA (described below). We kept the 8-bit color settings, and used the same sequential addressing scheme discussed in class to preserve memory.
The color of the pixel displayed on the screen for a given node is based on the value of uu, which is described above. The goal of our current color scheme is to promote the highest possible amount of diversity in colors.
2.3.5 SDRAM
Since we chose to implement full 640×480 display with 16-bit precision, we require a total of (640 × 480 pixels) × (9 values / pixel) × (16 bits / value) = 5.53 MB of storage. This amount of memory is not available on-chip, so we chose to store the entire working set in off-chip SDRAM, accessible through Qsys. The SDRAM chip on the DE1-SoC development board can store 64 MB of data, organized as 8M x 16 bits x 4 banks.
The Qsys tool can generate an SDRAM controller circuit which provides all signals needed to access the SDRAM and carefully manages the timing requirements. We added an external bus master to drive the SDRAM controller by reading or writing the following signals in the state machine: bus address, bus read data, bus write data, bus read enable, bus write enable, and bus ack. The mapping of a pixel’s data to its location in memory given its location on the VGA display is provided by the following bus addressing structure where x_vga is the column value from 0 to 639, y_vga is the row value from 0 to 439, and direction is a value from 0 to 9:
bus address = {2’b0, x_vga[9:0], y_vga[8:0], direction[3:0], 1’b0}
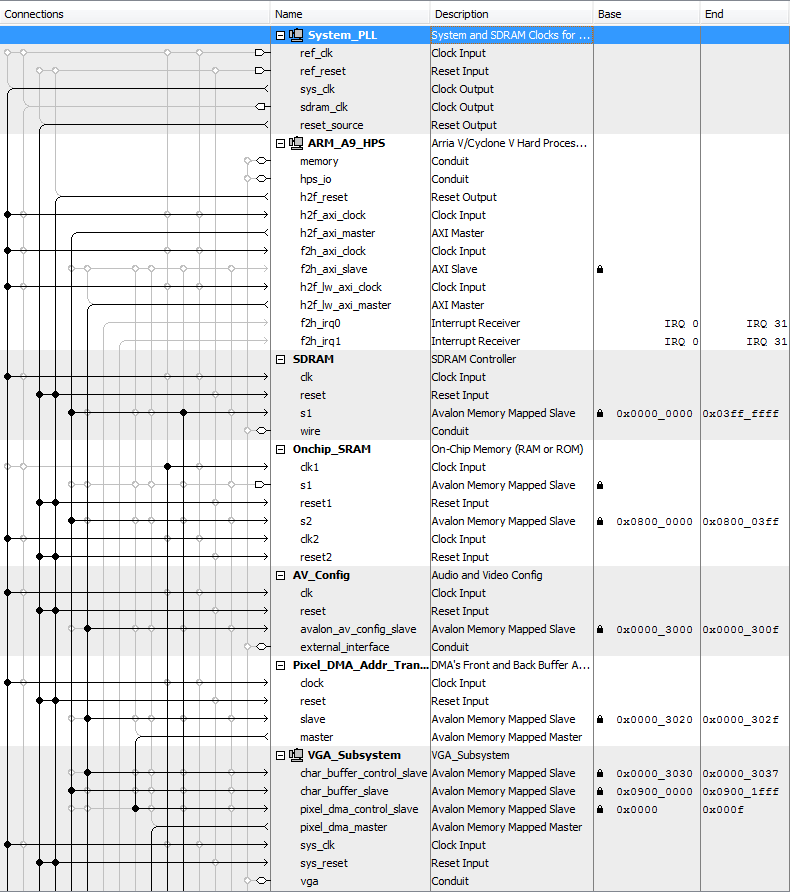
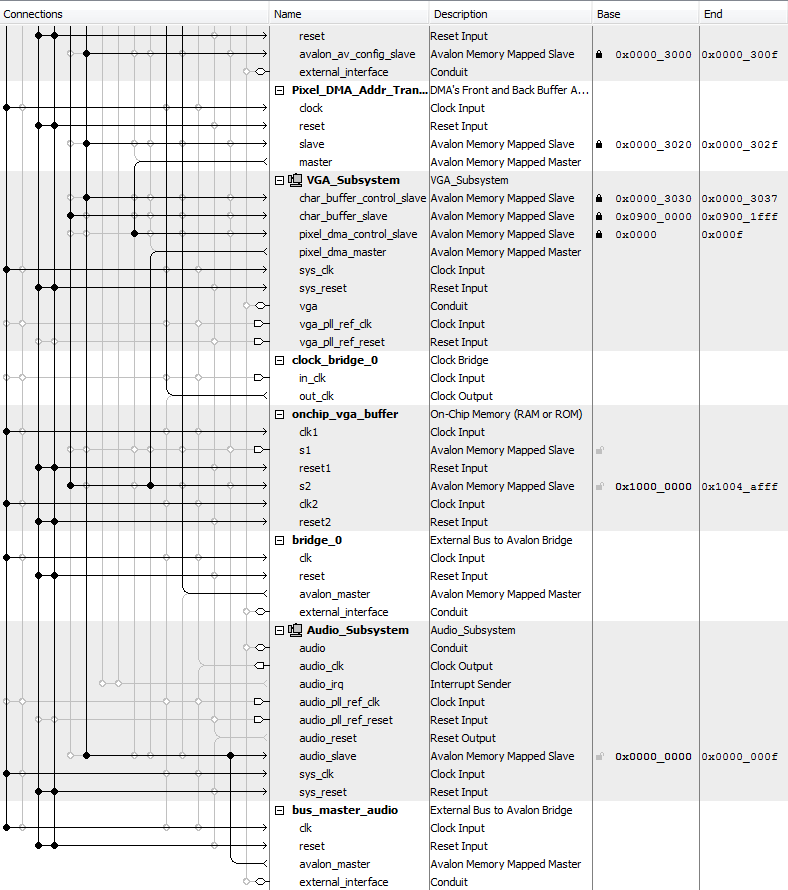
2.4 Qsys Setup
The Qsys layout for all component systems is shown below. The VGA subsystem setup is adapted from the “GPU with FAST display from SRAM” example on the course website. The system uses an on-chip, dual-port SRAM as a VGA buffer. One port, s2, is connected to the VGA controller and HPS through Qsys. The signals for the other SRAM port, s1, are exported to the FPGA fabric and directly controlled by the state machine. Since port s1 is clocked at the Qsys bus frequency of 100 MHz while the solver is running at 50 MHz, we needed a clock bridge for synchronization between the SRAM and solver.
The SDRAM controller is used to access off-chip SDRAM and is connected to both HPS and an external bus master on port s1. The base and end addresses of the SDRAM are 0x0000_0000 and 0x03FF_FFFF, respectively. Contention for the single port is handled through the Qsys, and our state machine includes computation states that do not read or write the SDRAM and allow HPS to access it. The bus master is an external bus to the Avalon bridge; its signals are exported to the FPGA fabric and are driven by the state machine.
The Audio subsystem setup is adapted from the “Audio output bus-master” example on the course website. The audio_slave port is driven by the HPS and is also hooked up to an external audio bus master. Since the audio bus master signals are never driven by the FPGA, there is no contention for the audio codec.
2.5 HPS Design
The primary purpose of the HPS in this project is to perform a fast fourier transform (FFT) on a sample of microphone input data, set certain lattice values in the SDRAM based on the FFT results, set the SDRAM to initial values, and dump the SDRAM data to a file for debugging. The FFT was adapted from Cornell ECE 4760’s sample FFT code found on Bruce Land’s Cornell website. The FFT uses 128 samples to output 64 real and 64 imaginary coefficients corresponding to the frequency components of the samples. From this, the magnitude of the pair of real and imaginary values was used to define the strength - or length - of the jets on the bottom of the screen. The jets are used to initialize the simulation and provide a source for the fluid densities.
To initialize the fluid densities, the SDRAM is utilized with an appropriate Qsys setup (see 2.4 Qsys). From this, we defined a short pointer for the SDRAM memory mapping. To set the density for an individual node, we have to consider how the Verilog perceives the mapping from x position, y position, and direction to address. The x position is defined as ten bits. The y position follows and is defined by nine bits. The direction is defined by two bits and follows after. The translations between x, y, and dir to a single memory address (and vice-versa) are shown below.
Address = (x & 0x3FF) << 13 + (y & 0x1FF) << 4 + (dir & 0x00F);
X = (address >> 13) & 0x3FF;
Y = (address >> 4) & 0x1FF;
Dir = address & 0x00F;
Armed with this mapping, we can easily set any lattice cell in SDRAM memory given the correct SDRAM base address.
The audio data, the audio bus, audio config, and audio masters are appropriately initialized in Qsys setup (see 2.4 Qsys). From the datasheet, we can define the starting address of audio information. The initial address contains control information regarding interrupts and FIFO clearing. The next address handles the amount of FIFO space available per each read / write, for both the left and right channel. The last two addresses handle left and right data read and writes. Each address represents a 32-bit space. Given this, we can easily define a routine that continually checks the FIFO space for any data available on read, then reads the data into a sample buffer. To achieve good FFT results, this sample buffer can be filled at variable sampling frequencies by setting up sample buffer filling every nth read. Due to the perceived complexities of FFT, and the desire to always read from the FIFO if it is filled, pthreads was used to separate the sampling and the FFT calculations.
For debugging and initialization purposes, an initial loop was designed to loop through every value of the lattice and extract data for dumping to a file or printing on the command line. The dumped information was formatted for human readability and ease of parsing. A setting and resetting function was defined as well to set all parts of the SDRAM or lattice to a specific value. This allowed for zeroing the entire memory and proved useful for debugging at specific locations.
3. Testing
In general, testing this project turned out to be quite tedious for a couple reasons. A large portion of our design relied on Altera’s shift register IP, which we could not simulate in ModelSim. This meant that we had to compile our design countless times on Quartus to debug issues with the shift register. Each compilation took upwards of 10 minutes, which led to a significant amount of time spent watching the progress bar. This problem was compounded by the fact that it needed to communicate with the SDRAM, which we had never previously used. A lot of our time was spent compiling and running very simple Verilog code which was designed to test that we had set the byte enables correctly, understood the timing of the acknowledgment, and correctly fit our algorithm to the organization of the memory. This last point proved especially insidious; it took us several tries to coordinate the HPS and Verilog code with the correct byte-alignment for the SDRAM’s 16-bit words.
Despite these issues, we tried to develop a comprehensive testing strategy for the project as a whole. We first used ModelSim to simulate the flow for a single node in isolation, ensuring that the initial energy provided to the system died out as a result of dispersion. After that was confirmed, we instantiated a cluster of nine nodes arranged in a 3×3 grid - enough to mirror the calculations that our solver would necessarily have to perform. This led to the creation of the window module, which was used to test that the solver properly diffused the fluid particles from one node to its surroundings.
Simultaneously, we began developing C code for the HPS. The HPS proved instrumental in debugging the SDRAM, since we could corroborate that reads from the FPGA could be read by the HPS, and vice-versa. We quickly developed scripts in C to initialize the entire SDRAM to zero, dump the contents of the memory to a file, and quickly set certain addresses which we used extensively for testing.
4. Results
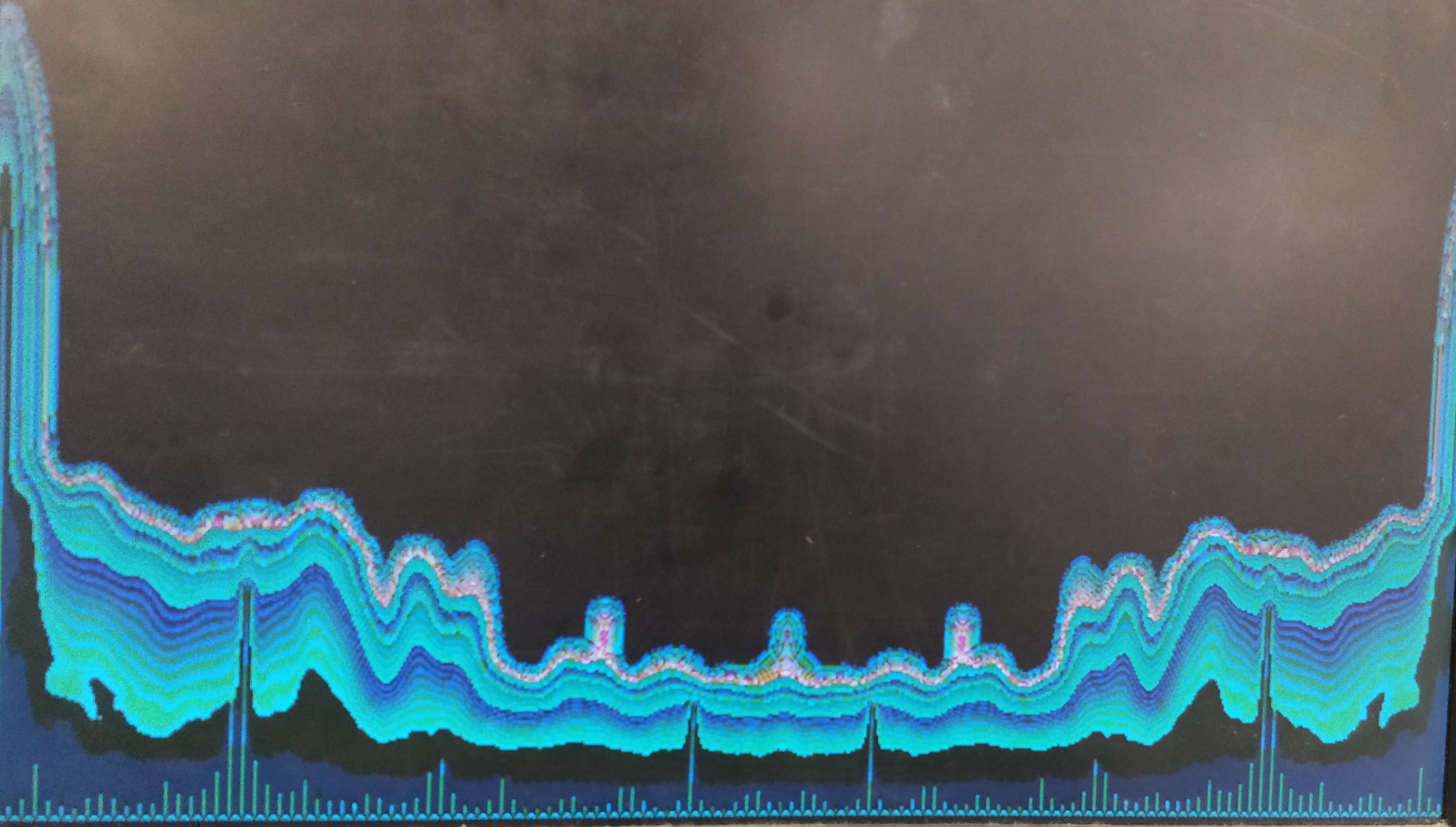
The figure above depicts a typical screenshot of our project in response to music. The complex FFT is visualized by a symmetric number of peaks at various frequencies, which undulate over time as the fluid densities diffuse.
While we set out to fully implement both diffusion, which governs the natural spread of fluids, and advection, which results from collisions based on fluid dynamics. Partially because of our prior testing, diffusion was easy for us to implement, and worked as expected. Advection, which requires the intermediate values uxx, uyy, uxy, and uu, proved significantly more challenging. We designed logic to encompass all of the necessary equations using minimal resources; however, every time we tested the solver with any non-zero initial condition, any nearby pixel would immediately reach a very high value for all nine of its distribution functions.
Our first guess is that we had failed to account for the fact that the intermediate results, corresponding to velocities of flowing particles, could take negative values. We then experimented with all kinds of signed arithmetic, adding specific logic to prevent any of the fluid densities from going negative. This still proved fruitless, even after altering the parameters to retain a larger or smaller amount of their stationary fluid densities. In the end, we were only able to successfully implement diffusion in the time available.
Our solver was able to attain a fairly constant frame rate of one frame per second. The bottleneck for the design was the memory bandwidth, since we need to perform a large number of 16-bit reads and writes for every new frame. This issue is exacerbated by the HPS, which also writes to the SDRAM in order to inject new information and fluid densities into the system. In fact, if the HPS code is stopped, the resulting frame rate increases dramatically, since the Verilog design then experiences no memory contention to read and write cells.
The figure below juxtaposes the pure 2-sided FFT (displayed directly from the HPS) with the corresponding flow field produced by our project given a simple input with two strong frequency components. There is a clear one-to-one correspondence between the FFT and the fluid flows which arise from the densities stored by the HPS. Interestingly, as the frequency of the input audio is tuned linearly in time, fluid densities appear intermittently as the peaks shift. This causes a noticeable pattern to appear on the screen as the densities disperse down into the valleys produced by the starting and ending points of the frequency shift.
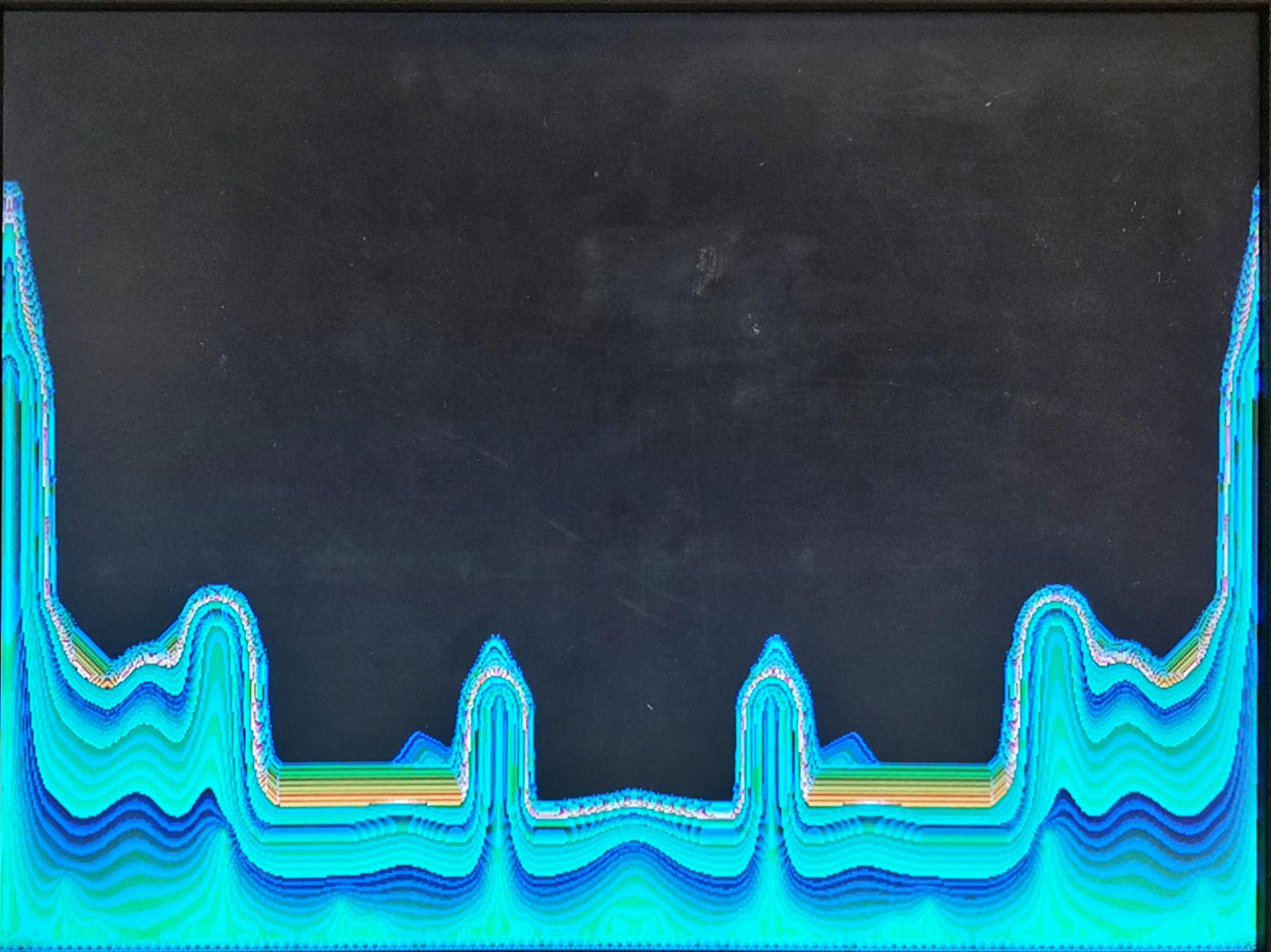
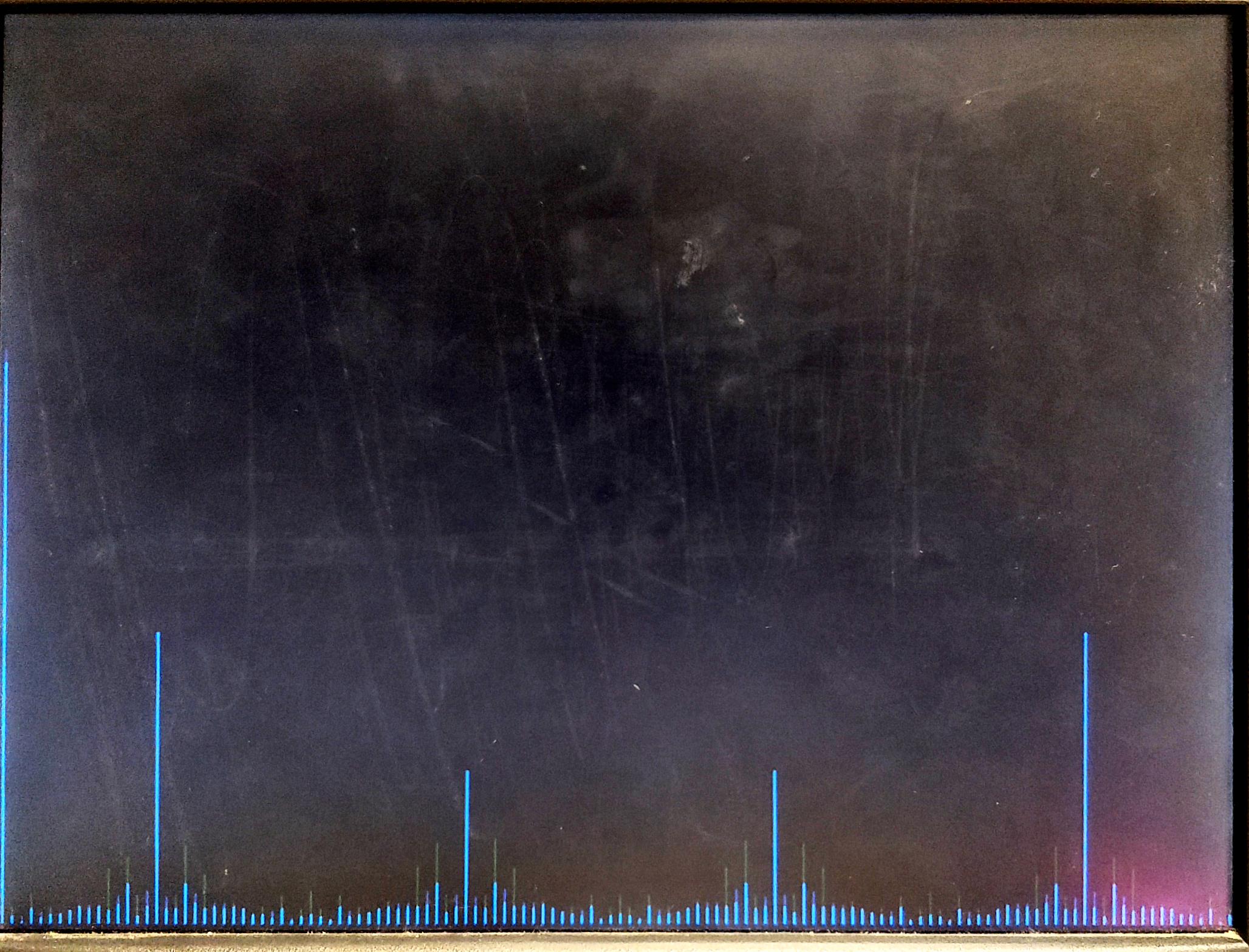
5. Conclusion
The overarching objective for this project was to create a visual expression of musical stimulus by simulating fluid flow on an FPGA. Although we ultimately did not fully implement Lattice-Boltzmann methods for fluid propagation and collisions, our design was able to successfully translate the frequency and volume of an audio input to different jet particle distributions and simulating their diffusion on a grid of cells.
5.1 Potential Improvements
While we believe our implementation is fairly close to the maximum speed achievable while using a 50 MHz clock and the off-chip SDRAM, there are a couple improvements that we could make given additional time. First, the HPS could transmit data directly to the FPGA fabric, avoiding the contention for the SDRAM’s write port. The same data could then be added by Verilog code as it was processed by the solver, which could improve our overall speed.
Furthermore, we could make use of more of the on-chip memory to cache as many nodes as possible. By interleaving off-chip memory requests with on-chip cached values, we could achieve better performance while simultaneously relieving memory contention.
We have a single superfluous state reserved for calculation. When we designed the state machine, we left a single clock cycle of latency in the case that the solver would require an additional cycle for computation. After extensive testing, we realized that this state was no longer necessary, but kept it in as it properly initialized the next state. We could optimize our state machine to remove this single state, gaining another sliver of performance gain.
Lastly, we could improve the visualization of the project in other ways. We could adopt other color schemes, or make them programmable based on the switches, or some other feature of the audio input. One other idea is to have a reconfigurable number of cells, so that it would be possible to attain any desired frame rate by interpolating between a smaller number of nodes.
5.2 Intellectual Property Considerations
Our design instantiated an Altera ATLSHIFT_TAPS IP Core (see reference paper[2]) since the size of our shift register (640 × 3 pixels) × (9 values / pixel) × (16 bits / value) = 34.6 KB) necessitated the use of M10K memory blocks. The shift register was configured with three taps, a tap distance of 640, and data width of 144 bits.
6. Work Distribution

Brian Ritchen
bjr96@cornell.edu
Divya Gupta
dg542@cornell.edu
Brendon Jackson
btj28@cornell.edu
Overall system architecture was designed by all group members. Brian and Divya focused on implementation of the solver on the FPGA fabric, including the state machine, shift register, and Lattice-Boltzmann module, and writing to the VGA monitor. Brendon set up the Audio subsystem and wrote the HPS C code to initialize, write, and dump out values from the SDRAM, and perform the FFT.
7. References
1. Claesen, L., Nowicki, D. “SoC Architecture for Real-Time Interactive Painting based on Lattice-Boltzmann”. IEEE 2010 International Conference on Electronics, Circuits, and Systems, December 2010.
2. Altera Corporation. “RAM-Based Shift Register (ALTSHIFT_TAPS) IP Core User Guide”. https://www.altera.com/content/dam/altera-www/global/en_US/pdfs/literature/ug/ug_shift_register_ram_based.pdf
8. Appendix
The group approves this report for inclusion on the course website.
The group approves the video for inclusion on the course youtube channel.
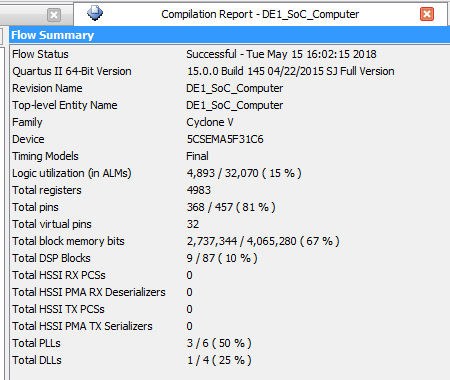
8.1 Compilation Report
8.2 Verilog
Download Code
//`include "vc/queues.v"
//`include "vc/arbiters.v"
//`include "vc/muxes.v"
//`include "vc/regs.v"
module DE1_SoC_Computer (
////////////////////////////////////
// FPGA Pins
////////////////////////////////////
// Clock pins
CLOCK_50,
CLOCK2_50,
CLOCK3_50,
CLOCK4_50,
// ADC
ADC_CS_N,
ADC_DIN,
ADC_DOUT,
ADC_SCLK,
// Audio
AUD_ADCDAT,
AUD_ADCLRCK,
AUD_BCLK,
AUD_DACDAT,
AUD_DACLRCK,
AUD_XCK,
// SDRAM
DRAM_ADDR,
DRAM_BA,
DRAM_CAS_N,
DRAM_CKE,
DRAM_CLK,
DRAM_CS_N,
DRAM_DQ,
DRAM_LDQM,
DRAM_RAS_N,
DRAM_UDQM,
DRAM_WE_N,
// I2C Bus for Configuration of the Audio and Video-In Chips
FPGA_I2C_SCLK,
FPGA_I2C_SDAT,
// 40-Pin Headers
GPIO_0,
GPIO_1,
// Seven Segment Displays
HEX0,
HEX1,
HEX2,
HEX3,
HEX4,
HEX5,
// IR
IRDA_RXD,
IRDA_TXD,
// Pushbuttons
KEY,
// LEDs
LEDR,
// PS2 Ports
PS2_CLK,
PS2_DAT,
PS2_CLK2,
PS2_DAT2,
// Slider Switches
SW,
// Video-In
TD_CLK27,
TD_DATA,
TD_HS,
TD_RESET_N,
TD_VS,
// VGA
VGA_B,
VGA_BLANK_N,
VGA_CLK,
VGA_G,
VGA_HS,
VGA_R,
VGA_SYNC_N,
VGA_VS,
////////////////////////////////////
// HPS Pins
////////////////////////////////////
// DDR3 SDRAM
HPS_DDR3_ADDR,
HPS_DDR3_BA,
HPS_DDR3_CAS_N,
HPS_DDR3_CKE,
HPS_DDR3_CK_N,
HPS_DDR3_CK_P,
HPS_DDR3_CS_N,
HPS_DDR3_DM,
HPS_DDR3_DQ,
HPS_DDR3_DQS_N,
HPS_DDR3_DQS_P,
HPS_DDR3_ODT,
HPS_DDR3_RAS_N,
HPS_DDR3_RESET_N,
HPS_DDR3_RZQ,
HPS_DDR3_WE_N,
// Ethernet
HPS_ENET_GTX_CLK,
HPS_ENET_INT_N,
HPS_ENET_MDC,
HPS_ENET_MDIO,
HPS_ENET_RX_CLK,
HPS_ENET_RX_DATA,
HPS_ENET_RX_DV,
HPS_ENET_TX_DATA,
HPS_ENET_TX_EN,
// Flash
HPS_FLASH_DATA,
HPS_FLASH_DCLK,
HPS_FLASH_NCSO,
// Accelerometer
HPS_GSENSOR_INT,
// General Purpose I/O
HPS_GPIO,
// I2C
HPS_I2C_CONTROL,
HPS_I2C1_SCLK,
HPS_I2C1_SDAT,
HPS_I2C2_SCLK,
HPS_I2C2_SDAT,
// Pushbutton
HPS_KEY,
// LED
HPS_LED,
// SD Card
HPS_SD_CLK,
HPS_SD_CMD,
HPS_SD_DATA,
// SPI
HPS_SPIM_CLK,
HPS_SPIM_MISO,
HPS_SPIM_MOSI,
HPS_SPIM_SS,
// UART
HPS_UART_RX,
HPS_UART_TX,
// USB
HPS_CONV_USB_N,
HPS_USB_CLKOUT,
HPS_USB_DATA,
HPS_USB_DIR,
HPS_USB_NXT,
HPS_USB_STP
);
//=======================================================
// PARAMETER declarations
//=======================================================
//=======================================================
// PORT declarations
//=======================================================
////////////////////////////////////
// FPGA Pins
////////////////////////////////////
// Clock pins
input CLOCK_50;
input CLOCK2_50;
input CLOCK3_50;
input CLOCK4_50;
// ADC
inout ADC_CS_N;
output ADC_DIN;
input ADC_DOUT;
output ADC_SCLK;
// Audio
input AUD_ADCDAT;
inout AUD_ADCLRCK;
inout AUD_BCLK;
output AUD_DACDAT;
inout AUD_DACLRCK;
output AUD_XCK;
// SDRAM
output [12: 0] DRAM_ADDR; //12:0
output [1:0] DRAM_BA; //1:0
output DRAM_CAS_N;
output DRAM_CKE;
output DRAM_CLK;
output DRAM_CS_N;
inout [15: 0] DRAM_DQ; //15:0
output DRAM_LDQM;
output DRAM_RAS_N;
output DRAM_UDQM;
output DRAM_WE_N;
// I2C Bus for Configuration of the Audio and Video-In Chips
output FPGA_I2C_SCLK;
inout FPGA_I2C_SDAT;
// 40-pin headers
inout [35: 0] GPIO_0;
inout [35: 0] GPIO_1;
// Seven Segment Displays
output [ 6: 0] HEX0;
output [ 6: 0] HEX1;
output [ 6: 0] HEX2;
output [ 6: 0] HEX3;
output [ 6: 0] HEX4;
output [ 6: 0] HEX5;
// IR
input IRDA_RXD;
output IRDA_TXD;
// Pushbuttons
input [ 3: 0] KEY;
// LEDs
output [ 9: 0] LEDR;
// PS2 Ports
inout PS2_CLK;
inout PS2_DAT;
inout PS2_CLK2;
inout PS2_DAT2;
// Slider Switches
input [ 9: 0] SW;
// Video-In
input TD_CLK27;
input [ 7: 0] TD_DATA;
input TD_HS;
output TD_RESET_N;
input TD_VS;
// VGA
output [ 7: 0] VGA_B;
output VGA_BLANK_N;
output VGA_CLK;
output [ 7: 0] VGA_G;
output VGA_HS;
output [ 7: 0] VGA_R;
output VGA_SYNC_N;
output VGA_VS;
////////////////////////////////////
// HPS Pins
////////////////////////////////////
// DDR3 SDRAM
output [14: 0] HPS_DDR3_ADDR;
output [ 2: 0] HPS_DDR3_BA;
output HPS_DDR3_CAS_N;
output HPS_DDR3_CKE;
output HPS_DDR3_CK_N;
output HPS_DDR3_CK_P;
output HPS_DDR3_CS_N;
output [ 3: 0] HPS_DDR3_DM;
inout [31: 0] HPS_DDR3_DQ;
inout [ 3: 0] HPS_DDR3_DQS_N;
inout [ 3: 0] HPS_DDR3_DQS_P;
output HPS_DDR3_ODT;
output HPS_DDR3_RAS_N;
output HPS_DDR3_RESET_N;
input HPS_DDR3_RZQ;
output HPS_DDR3_WE_N;
// Ethernet
output HPS_ENET_GTX_CLK;
inout HPS_ENET_INT_N;
output HPS_ENET_MDC;
inout HPS_ENET_MDIO;
input HPS_ENET_RX_CLK;
input [ 3: 0] HPS_ENET_RX_DATA;
input HPS_ENET_RX_DV;
output [ 3: 0] HPS_ENET_TX_DATA;
output HPS_ENET_TX_EN;
// Flash
inout [ 3: 0] HPS_FLASH_DATA;
output HPS_FLASH_DCLK;
output HPS_FLASH_NCSO;
// Accelerometer
inout HPS_GSENSOR_INT;
// General Purpose I/O
inout [ 1: 0] HPS_GPIO;
// I2C
inout HPS_I2C_CONTROL;
inout HPS_I2C1_SCLK;
inout HPS_I2C1_SDAT;
inout HPS_I2C2_SCLK;
inout HPS_I2C2_SDAT;
// Pushbutton
inout HPS_KEY;
// LED
inout HPS_LED;
// SD Card
output HPS_SD_CLK;
inout HPS_SD_CMD;
inout [ 3: 0] HPS_SD_DATA;
// SPI
output HPS_SPIM_CLK;
input HPS_SPIM_MISO;
output HPS_SPIM_MOSI;
inout HPS_SPIM_SS;
// UART
input HPS_UART_RX;
output HPS_UART_TX;
// USB
inout HPS_CONV_USB_N;
input HPS_USB_CLKOUT;
inout [ 7: 0] HPS_USB_DATA;
input HPS_USB_DIR;
input HPS_USB_NXT;
output HPS_USB_STP;
//=======================================================
// REG/WIRE declarations
//=======================================================
wire [23: 0] hex3_hex0;
//wire [15: 0] hex5_hex4;
//assign HEX0 = ~hex3_hex0[ 6: 0]; // hex3_hex0[ 6: 0];
//assign HEX1 = ~hex3_hex0[14: 8];
//assign HEX2 = ~hex3_hex0[22:16];
//assign HEX3 = ~hex3_hex0[30:24];
HexDigit Digit0(HEX0, hex3_hex0[3:0]);
HexDigit Digit1(HEX1, hex3_hex0[7:4]);
HexDigit Digit2(HEX2, hex3_hex0[11:8]);
HexDigit Digit3(HEX3, hex3_hex0[15:12]);
HexDigit Digit4(HEX4, hex3_hex0[19:16]);
HexDigit Digit5(HEX5, hex3_hex0[23:20]);
assign hex3_hex0 = uu[23:0];
wire [31:0] sram_readdata ;
reg [31:0] data_buffer, sram_writedata ;
reg [7:0] sram_address;
reg sram_write ;
wire sram_clken = 1'b1;
wire sram_chipselect = 1'b1;
reg [7:0] vga_sram_writedata ;
reg [31:0] vga_sram_address;
reg vga_sram_write ;
wire vga_sram_clken = 1'b1;
wire vga_sram_chipselect = 1'b1;
logic [2:0][2:0][8:0][15:0] f_in;
logic [8:0][15:0] f_out;
logic signed [31:0] uu;
logic [431:0] window_in;
logic [143:0] data_in;
logic shift_clken;
//======================================================
// Instantiations
//======================================================
node noder(
.clk(clk),
.reset(reset),
.f_in(f_in),
.uu(uu),
.f_trunc(f_out)
);
window winner(
.clk(CLOCK_50),
.clken(shift_clken),
.in(window_in),
.win(f_in)
);
shifter2 twister(
.clock(CLOCK_50),
.clken(shift_clken),
.shiftin(data_in),
.shiftout(),
.taps(window_in)
);
logic [25:0] bus_addr;
logic [15:0] bus_read_data;
logic [15:0] bus_write_data;
logic bus_read;
logic bus_write;
logic bus_ack;
logic [9:0] x_sd, x_vga;
logic [8:0] y_sd, y_vga;
logic [3:0] state;
logic [3:0] dir;
logic test;
always_comb begin
//Initializion for shift register
if (state == 4'd2 && dir == 4'd0 && bus_ack) begin
shift_clken = 1;
end
//Next pixel
else if (state == 4'd7 && bus_ack && !(x_sd >= 10'd639 && y_sd >= 9'd479) ) begin
shift_clken = 1;
end
else begin
shift_clken = 0;
end
end
logic [15:0] read_data;
always_ff @(posedge CLOCK_50) begin
if (~KEY[0]) begin
state <= 0;
dir <= 0;
x_sd <= 0;
x_vga <= 0;
y_sd <= 0;
y_vga <= 0;
vga_sram_address <= 0;
vga_sram_write <= 0;
vga_sram_writedata <= 0;
data_in <= 0;
bus_read <= 0;
bus_write <= 0;
bus_addr <= 0;
read_data <= 0;
test <= 0;
end
else if (state == 4'd0 && ~KEY[1]) begin
bus_write <= 1;
bus_addr <= {2'b0, 10'd320, 9'd240, 4'd4, 1'b0};
bus_write_data <= 16'b0101010101010101;
state <= 4'd1;
end
else if (state == 4'd1 && bus_ack == 1) begin
bus_read <= 1;
bus_write <= 0;
bus_addr <= 0;
state <= 4'd2;
dir <= 4'd0;
end
//======================================================
// Preload 3 rows into the shifter
//======================================================
else if ((state == 4'd2) && bus_ack == 1) begin
//Always set bus_addr and read
if (dir == 4'd8) begin
if (x_sd == 10'd639) begin
bus_addr <= {2'b0, x_sd, y_sd+1, 4'b0, 1'b0};
end else begin
bus_addr <= {2'b0, x_sd+1, y_sd, 4'b0, 1'b0};
end
end else begin
bus_addr <= {2'b0, x_sd, y_sd, (dir + 4'b1), 1'b0 };
end
bus_read <= 1;
bus_write <= 0;
data_in[(16*dir + 15) -: 16] <= bus_read_data;
//Termination condition
if ((x_sd >= 10'd2) && (y_sd >= 9'd3) && (dir == 4'd8)) begin
state <= 4'd3;
dir <= 0;
x_sd <= x_sd + 10'd1;
x_vga <= 10'd2;
y_vga <= 9'd1;
end
//end of row
else if ((x_sd >= 10'd639) && (dir >= 4'd8)) begin
x_sd <= 0;
y_sd <= y_sd + 9'b1;
dir <= 0;
end
//end of block
else if (dir >= 4'd8) begin
x_sd <= x_sd + 10'd1;
dir <= 0;
end
//standard case
else begin
dir <= dir + 4'd1;
end
end
//======================================================
// Read block from memory (9 elements)
//======================================================
else if ((state == 4'd3) && bus_ack) begin
test <= 1;
bus_write <= 0;
if (dir >= 4'd8) begin
dir <= 0;
state <= 4'd5;
bus_read <= 0;
end else begin
dir <= dir + 4'd1;
bus_read <= 1;
end
bus_addr <= {2'b0, x_sd, y_sd, (dir + 4'b1), 1'b0};
data_in[(16*dir + 15) -: 16] <= bus_read_data; //e.g. when dir = 1, store to [15:0]
end
//======================================================
// Compute
//======================================================
else if (state == 4'd5) begin
state <= 4'd6;
dir <= 0;
bus_addr <= 0;
bus_read <= 1; //to provide bus_ack for state 6
end
//======================================================
// Write the block to memory (9 elements)
//======================================================
else if ((state == 4'd6) && bus_ack) begin
bus_read <= 0;
bus_write <= 1;
if (dir >= 4'd8) begin
dir <= 0;
state <= 4'd7;
end else begin
dir <= dir + 1;
end
bus_write_data <= f_out[dir]; //{16{SW[0]}};
bus_addr <= {2'b0, x_vga, y_vga, dir, 1'b0};
//Draw this pixel
vga_sram_address <= 32'h10000000 + {22'b0, x_vga} + ({22'b0, y_vga}*640);
vga_sram_write <= 1'b1;
if (uu > 32'h1000_0000) begin
vga_sram_writedata <= uu[31:24];
end else if (uu > 32'h0100_0000) begin
vga_sram_writedata <= uu[29:22];
end else if (uu > 32'h0010_0000) begin
vga_sram_writedata <= uu[25:18];
end else if (uu > 32'h0001_0000) begin
vga_sram_writedata <= uu[21:14];
end else if (uu > 32'h0000_1000) begin
vga_sram_writedata <= uu[17:10];
end else if (uu > 32'h0000_0400) begin
vga_sram_writedata <= uu[13:6];
end else if (uu > 32'h0000_0100) begin
vga_sram_writedata <= uu[11:4];
end else begin
vga_sram_writedata <= uu[7:0];
end
end
//======================================================
// Update X and Y
//======================================================
else if ((state == 4'd7) && bus_ack) begin
dir <= 0;
bus_read <= 1;
bus_write <= 0;
//end of frame
if (x_sd >= 10'd639 && y_sd >= 9'd479) begin
x_vga <= 10'd1;
y_vga <= 9'd1;
x_sd <= 0;
y_sd <= 0;
state <= 4'd2;
bus_addr <= 0;
//end of row
end else if (x_sd >= 10'd639) begin
x_sd <= 0;
y_sd <= y_sd + 9'b1;
x_vga <= x_vga + 10'd1;
state <= 4'd3;
bus_addr <= {2'b0, x_sd, y_sd+1, 4'b0, 1'b0 };
//end of row
end else if (x_vga >= 10'd639) begin
x_vga <= 10'd0; //comment
y_vga <= y_vga + 9'b1;
x_sd <= x_sd + 10'd1;
state <= 4'd3;
bus_addr <= {2'b0, x_sd+1, y_sd, 4'b0, 1'b0 };
//normal
end else begin
x_sd <= x_sd + 10'd1;
x_vga <= x_vga + 10'd1;
state <= 4'd3;
bus_addr <= {2'b0, x_sd+1, y_sd, 4'b0, 1'b0 };
end
end
end
assign LEDR[9:0] = {uu[31:24], 2'b00};//{dir[3:0], /*x[0]*/ test, bus_ack, state[3:0]};
//=======================================================
// Structural coding
//=======================================================
// From Qsys
Computer_System The_System (
////////////////////////////////////
// FPGA Side
////////////////////////////////////
// Global signals
.system_pll_ref_clk_clk (CLOCK_50),
.system_pll_ref_reset_reset (1'b0),
// SRAM shared block with HPS
.onchip_sram_s1_address (sram_address),
.onchip_sram_s1_clken (sram_clken),
.onchip_sram_s1_chipselect (sram_chipselect),
.onchip_sram_s1_write (sram_write),
.onchip_sram_s1_readdata (sram_readdata),
.onchip_sram_s1_writedata (sram_writedata),
.onchip_sram_s1_byteenable (4'b1111),
// sram to video
.onchip_vga_buffer_s1_address (vga_sram_address),
.onchip_vga_buffer_s1_clken (vga_sram_clken),
.onchip_vga_buffer_s1_chipselect (vga_sram_chipselect),
.onchip_vga_buffer_s1_write (vga_sram_write),
.onchip_vga_buffer_s1_readdata (), // never read from vga here
.onchip_vga_buffer_s1_writedata (vga_sram_writedata),
// AV Config
.av_config_SCLK (FPGA_I2C_SCLK),
.av_config_SDAT (FPGA_I2C_SDAT),
.audio_pll_ref_clk_clk (CLOCK3_50),
.audio_pll_ref_reset_reset (1'b0),
.audio_clk_clk (AUD_XCK),
.audio_ADCDAT (AUD_ADCDAT),
.audio_ADCLRCK (AUD_ADCLRCK),
.audio_BCLK (AUD_BCLK),
.audio_DACDAT (AUD_DACDAT),
.audio_DACLRCK (AUD_DACLRCK),
.bus_master_audio_external_interface_address (bus_addr_audio),
.bus_master_audio_external_interface_byte_enable (bus_byte_enable_audio),
.bus_master_audio_external_interface_read (bus_read_audio),
.bus_master_audio_external_interface_write (bus_write_audio),
.bus_master_audio_external_interface_write_data (bus_write_data_audio),
.bus_master_audio_external_interface_acknowledge (bus_ack_audio),
.bus_master_audio_external_interface_read_data (bus_read_data_audio),
// 50 MHz clock bridge
.clock_bridge_0_in_clk_clk (CLOCK_50), //(CLOCK_50),
// VGA Subsystem
.vga_pll_ref_clk_clk (CLOCK2_50),
.vga_pll_ref_reset_reset (1'b0),
.vga_CLK (VGA_CLK),
.vga_BLANK (VGA_BLANK_N),
.vga_SYNC (VGA_SYNC_N),
.vga_HS (VGA_HS),
.vga_VS (VGA_VS),
.vga_R (VGA_R),
.vga_G (VGA_G),
.vga_B (VGA_B),
// SDRAM
.sdram_clk_clk (DRAM_CLK),
.sdram_addr (DRAM_ADDR),
.sdram_ba (DRAM_BA),
.sdram_cas_n (DRAM_CAS_N),
.sdram_cke (DRAM_CKE),
.sdram_cs_n (DRAM_CS_N),
.sdram_dq (DRAM_DQ),
.sdram_dqm ({DRAM_UDQM,DRAM_LDQM}),
.sdram_ras_n (DRAM_RAS_N),
.sdram_we_n (DRAM_WE_N),
// bus master for sram to video
.sdram_bridge_address (bus_addr),
.sdram_bridge_byte_enable (4'b1111),
.sdram_bridge_read (bus_read),
.sdram_bridge_write (bus_write),
.sdram_bridge_write_data (bus_write_data),
.sdram_bridge_acknowledge (bus_ack),
.sdram_bridge_read_data (bus_read_data),
////////////////////////////////////
// HPS Side
////////////////////////////////////
// DDR3 SDRAM
.memory_mem_a (HPS_DDR3_ADDR),
.memory_mem_ba (HPS_DDR3_BA),
.memory_mem_ck (HPS_DDR3_CK_P),
.memory_mem_ck_n (HPS_DDR3_CK_N),
.memory_mem_cke (HPS_DDR3_CKE),
.memory_mem_cs_n (HPS_DDR3_CS_N),
.memory_mem_ras_n (HPS_DDR3_RAS_N),
.memory_mem_cas_n (HPS_DDR3_CAS_N),
.memory_mem_we_n (HPS_DDR3_WE_N),
.memory_mem_reset_n (HPS_DDR3_RESET_N),
.memory_mem_dq (HPS_DDR3_DQ),
.memory_mem_dqs (HPS_DDR3_DQS_P),
.memory_mem_dqs_n (HPS_DDR3_DQS_N),
.memory_mem_odt (HPS_DDR3_ODT),
.memory_mem_dm (HPS_DDR3_DM),
.memory_oct_rzqin (HPS_DDR3_RZQ),
// Ethernet
.hps_io_hps_io_gpio_inst_GPIO35 (HPS_ENET_INT_N),
.hps_io_hps_io_emac1_inst_TX_CLK (HPS_ENET_GTX_CLK),
.hps_io_hps_io_emac1_inst_TXD0 (HPS_ENET_TX_DATA[0]),
.hps_io_hps_io_emac1_inst_TXD1 (HPS_ENET_TX_DATA[1]),
.hps_io_hps_io_emac1_inst_TXD2 (HPS_ENET_TX_DATA[2]),
.hps_io_hps_io_emac1_inst_TXD3 (HPS_ENET_TX_DATA[3]),
.hps_io_hps_io_emac1_inst_RXD0 (HPS_ENET_RX_DATA[0]),
.hps_io_hps_io_emac1_inst_MDIO (HPS_ENET_MDIO),
.hps_io_hps_io_emac1_inst_MDC (HPS_ENET_MDC),
.hps_io_hps_io_emac1_inst_RX_CTL (HPS_ENET_RX_DV),
.hps_io_hps_io_emac1_inst_TX_CTL (HPS_ENET_TX_EN),
.hps_io_hps_io_emac1_inst_RX_CLK (HPS_ENET_RX_CLK),
.hps_io_hps_io_emac1_inst_RXD1 (HPS_ENET_RX_DATA[1]),
.hps_io_hps_io_emac1_inst_RXD2 (HPS_ENET_RX_DATA[2]),
.hps_io_hps_io_emac1_inst_RXD3 (HPS_ENET_RX_DATA[3]),
// Flash
.hps_io_hps_io_qspi_inst_IO0 (HPS_FLASH_DATA[0]),
.hps_io_hps_io_qspi_inst_IO1 (HPS_FLASH_DATA[1]),
.hps_io_hps_io_qspi_inst_IO2 (HPS_FLASH_DATA[2]),
.hps_io_hps_io_qspi_inst_IO3 (HPS_FLASH_DATA[3]),
.hps_io_hps_io_qspi_inst_SS0 (HPS_FLASH_NCSO),
.hps_io_hps_io_qspi_inst_CLK (HPS_FLASH_DCLK),
// Accelerometer
.hps_io_hps_io_gpio_inst_GPIO61 (HPS_GSENSOR_INT),
//.adc_sclk (ADC_SCLK),
//.adc_cs_n (ADC_CS_N),
//.adc_dout (ADC_DOUT),
//.adc_din (ADC_DIN),
// General Purpose I/O
.hps_io_hps_io_gpio_inst_GPIO40 (HPS_GPIO[0]),
.hps_io_hps_io_gpio_inst_GPIO41 (HPS_GPIO[1]),
// I2C
.hps_io_hps_io_gpio_inst_GPIO48 (HPS_I2C_CONTROL),
.hps_io_hps_io_i2c0_inst_SDA (HPS_I2C1_SDAT),
.hps_io_hps_io_i2c0_inst_SCL (HPS_I2C1_SCLK),
.hps_io_hps_io_i2c1_inst_SDA (HPS_I2C2_SDAT),
.hps_io_hps_io_i2c1_inst_SCL (HPS_I2C2_SCLK),
// Pushbutton
.hps_io_hps_io_gpio_inst_GPIO54 (HPS_KEY),
// LED
.hps_io_hps_io_gpio_inst_GPIO53 (HPS_LED),
// SD Card
.hps_io_hps_io_sdio_inst_CMD (HPS_SD_CMD),
.hps_io_hps_io_sdio_inst_D0 (HPS_SD_DATA[0]),
.hps_io_hps_io_sdio_inst_D1 (HPS_SD_DATA[1]),
.hps_io_hps_io_sdio_inst_CLK (HPS_SD_CLK),
.hps_io_hps_io_sdio_inst_D2 (HPS_SD_DATA[2]),
.hps_io_hps_io_sdio_inst_D3 (HPS_SD_DATA[3]),
// SPI
.hps_io_hps_io_spim1_inst_CLK (HPS_SPIM_CLK),
.hps_io_hps_io_spim1_inst_MOSI (HPS_SPIM_MOSI),
.hps_io_hps_io_spim1_inst_MISO (HPS_SPIM_MISO),
.hps_io_hps_io_spim1_inst_SS0 (HPS_SPIM_SS),
// UART
.hps_io_hps_io_uart0_inst_RX (HPS_UART_RX),
.hps_io_hps_io_uart0_inst_TX (HPS_UART_TX),
// USB
.hps_io_hps_io_gpio_inst_GPIO09 (HPS_CONV_USB_N),
.hps_io_hps_io_usb1_inst_D0 (HPS_USB_DATA[0]),
.hps_io_hps_io_usb1_inst_D1 (HPS_USB_DATA[1]),
.hps_io_hps_io_usb1_inst_D2 (HPS_USB_DATA[2]),
.hps_io_hps_io_usb1_inst_D3 (HPS_USB_DATA[3]),
.hps_io_hps_io_usb1_inst_D4 (HPS_USB_DATA[4]),
.hps_io_hps_io_usb1_inst_D5 (HPS_USB_DATA[5]),
.hps_io_hps_io_usb1_inst_D6 (HPS_USB_DATA[6]),
.hps_io_hps_io_usb1_inst_D7 (HPS_USB_DATA[7]),
.hps_io_hps_io_usb1_inst_CLK (HPS_USB_CLKOUT),
.hps_io_hps_io_usb1_inst_STP (HPS_USB_STP),
.hps_io_hps_io_usb1_inst_DIR (HPS_USB_DIR),
.hps_io_hps_io_usb1_inst_NXT (HPS_USB_NXT)
);
endmodule // end top level`
//////////////////////////////////////////////////
//// Solver module!!!!!!!!!!!!!!!!!!! ////////////
//////////////////////////////////////////////////
module node (clk, reset, f_in, f_trunc, uu);
input clk, reset;
input [2:0][2:0][8:0][15:0] f_in;
output [8:0][15:0] f_trunc;
logic signed [8:0][31:0] f_out;
output signed [31:0] uu;
logic signed [1:0][15:0] u;
logic signed [31:0] uxx, uyy;
logic signed [31:0] uxy;
logic signed [31:0] p;
assign p = f_in[0][0][8] + f_in[1][0][7] + f_in[2][0][6] + f_in[0][1][5] + f_in[1][1][4] + f_in[2][1][3] + f_in[0][2][2] + f_in[1][2][1] + f_in[2][2][0];
assign f_out[1] = p >>> 3;
assign f_out[3] = p >>> 3;
assign f_out[5] = p >>> 3;
assign f_out[7] = p >>> 3;
assign f_out[2] = p >>> 5;
assign f_out[0] = p >>> 5;
assign f_out[6] = p >>> 5;
assign f_out[8] = p >>> 5;
assign f_out[4] = (p >>> 2) + (p >>> 3);
genvar k;
generate
for (k = 0; k < 9; k = k + 1) begin : okay
assign f_trunc[k] = f_out[k][15:0];
end
endgenerate
assign u[0] = f_in[0][2][2] + f_in[0][1][5] + f_in[0][0][8] - f_in[2][2][0] - f_in[2][1][3] - f_in[2][0][6];
assign u[1] = f_in[2][2][0] + f_in[1][2][1] + f_in[0][2][2] - f_in[2][0][6] - f_in[1][0][7] - f_in[0][0][8];
assign uu = f_out[4];
endmodule
module window (clk, clken, in, win);
input clk;
input clken;
input [431:0] in;
logic [2:0][8:0][15:0] b;
logic [2:0][8:0][15:0] c;
output logic [2:0][2:0][8:0][15:0] win;
logic [2:0][8:0][15:0] in_formatted;
assign in_formatted[2] = in[143:0];
assign in_formatted[1] = in[287:144];
assign in_formatted[0] = in[431:288];
always_ff@(posedge clk) begin
if (clken) begin
b <= in_formatted;
c <= b;
end
end
assign win[0] = c;
assign win[1] = b;
assign win[2] = in_formatted;
endmodule
/// end /////////////////////////////////////////////////////////////////////
8.2 HPS.c
///////////////////////////////////////
/// HPS.c
/// Coded by Brendon Jackson, Divya
/// Gupta, and Brian Ritchken
/// Developed for Cornell ECE5760
/// 640x480 version!
/// MANDLEBROT SET USER INTERFACE
/// compile with
/// gcc mouse.c -o m1_test -lm -lpthread
///////////////////////////////////////
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define TRUE 1
#define FALSE 0
#include "address_map_arm_brl4.h"
#define HW_REGS_BASE 0xff200000
#define HW_REGS_SPAN 0x00005000
#define HW_REGS_MASK ( HW_REGS_SPAN - 1 )
#define RESET_PIO_BASE 0x00
#define X_INIT_PIO_BASE 0x10
#define Y_INIT_PIO_BASE 0x20
#define X_INCR_PIO_BASE 0x30
#define Y_INCR_PIO_BASE 0x40
#define R_EDGE_PIO_BASE 0x50
#define DONE_PIO_BASE 0x60
#define SDRAM_LATTICE_BASE (SDRAM_BASE)
#define SDRAM_LATTICE_SPAN 0x800000
#define SPANNN 0xE84800
pthread_mutex_t sample_lock= PTHREAD_MUTEX_INITIALIZER;
/* function prototypes */
void VGA_text (int, int, char *);
void VGA_text_clear ();
void dump_point(unsigned int, FILE *);
void dump_value(unsigned int, unsigned int, FILE *);
void FFTfix(int[], int[], int);
void FFTfix_samp();
void * fft_routine();
void * kevin_spacey();
// the light weight buss base
void *h2p_lw_virtual_base;
// RAM FPGA command buffer
volatile unsigned int * sram_ptr = NULL ;
void *sram_virtual_base;
// pixel buffer
volatile unsigned int * vga_pixel_ptr = NULL ;
void *vga_pixel_virtual_base;
// character buffer
volatile unsigned int * vga_char_ptr = NULL ;
void *vga_char_virtual_base;
// lattice buffer
volatile unsigned short *sdram_lattice = NULL;
void *sdram_lattice_virtual_base;
volatile unsigned short *bottom_row = NULL;
// Communication to FPGA through Qsys
volatile unsigned int *h2p_lw_reset_addr = NULL;
volatile unsigned int *audio_base_ptr = NULL;
volatile unsigned int *audio_fifo_data_ptr = NULL;
volatile unsigned int *audio_left_data_ptr = NULL;
volatile unsigned int *audio_right_data_ptr = NULL;
#define set_point_xy(x,y,dir,val) ( *(sdram_lattice + (((((x & 0x03FF) << 9) | (y & 0x01FF))<<4) | (dir & 0x000F))) = val & 0xFFFF )
#define set_point(x, val) (*(sdram_lattice + x) = val & 0xFFFF)
#define dump_newline(fout) (fputc('\n', fout))
#define OFF 0
// /dev/mem file id
int fd_mem;
//Some bools for states and such
char l_start_pt = 0;
char l_end_pt = 0;
char l_new_box = 0;
char fpga_working = 0;
#define VGA_PIXEL(x,y,color) do{\
char *pixel_ptr ;\
pixel_ptr = (char *)vga_pixel_ptr + ((y)*640) + (x) ;\
*(char *)pixel_ptr = (color);\
} while(0)
#define SWAP(X,Y) do{int temp=X; X=Y; Y=temp;}while(0)
#define int2fix(a) (((int)(a))<<8)
#define float2fix(a) ((int)((a)*256.0))
#define fix2float(a) ((float)(a)/256.0)
#define multfix(a,b) ((int)(((( signed long long)(a))*(( signed long long)(b)))>>8))
#define N_WAVE 128 /* size of FFT */
#define LOG2_N_WAVE 7 /* log2(N_WAVE) */
int Sinewave[N_WAVE]; // a table of sines for the FFT
unsigned char i_fft;
int fr[N_WAVE], fi[N_WAVE]; // sin[N_WAVE], cos[N_WAVE];
int sample[N_WAVE];
int raw;
int index_raw = 0;
int amp[N_WAVE];
int index_samp = 0;
// TIMING STUFF
struct timeval t1, t2;
double elapsedTime;
struct timespec delay_time;
char time_string[50];
char rflag = 0, dflag = 0, fflag = 0, Zflag = 0, lflag = 0, Fflag = 0;
int sample_size = 0;
int main(int argc, char **argv)
{
gettimeofday(&t1, NULL);
delay_time.tv_nsec = 1000;
delay_time.tv_sec = 0;
int c;
while ((c = getopt (argc, argv, "rldfZF")) != -1)
switch (c)
{
case 'r':
rflag = 1;
break;
case 'l':
lflag = 1;
break;
case 'd':
dflag = 1;
break;
case 'f':
fflag = 1;
break;
case 'Z':
Zflag = 1;
break;
case 'F':
Fflag = 1;
break;
case '?':
if (isprint (optopt))
fprintf (stderr, "Unknown option `-%c'.\n", optopt);
else
fprintf (stderr,
"Unknown option character `\\x%x'.\n",
optopt);
return 1;
default:
abort ();
}
if( ( fd_mem = open( "/dev/mem", ( O_RDWR | O_SYNC ) ) ) == -1 ) {
printf( "ERROR: could not open \"/dev/mem\"...\n" );
}
h2p_lw_virtual_base = mmap( NULL, HW_REGS_SPAN, ( PROT_READ | PROT_WRITE ), MAP_SHARED, fd_mem, HW_REGS_BASE );
if( h2p_lw_virtual_base == MAP_FAILED ) {
printf( "ERROR: mmap1() failed...\n" );
close( fd_mem );
}
audio_base_ptr = (unsigned int *)(h2p_lw_virtual_base + AUDIO_BASE);
audio_fifo_data_ptr = audio_base_ptr + 1;
audio_left_data_ptr = audio_base_ptr + 2;
audio_right_data_ptr = audio_base_ptr + 3;
h2p_lw_reset_addr = (unsigned int *)(h2p_lw_virtual_base + (( RESET_PIO_BASE ) & ( HW_REGS_MASK ) ));
/*vga_char_virtual_base = mmap( NULL, FPGA_CHAR_SPAN, ( PROT_READ | PROT_WRITE ), MAP_SHARED, fd_mem, FPGA_CHAR_BASE );
if( vga_char_virtual_base == MAP_FAILED ) {
printf( "ERROR: mmap2() failed...\n" );
close( fd_mem );
return(1);
}
vga_char_ptr = (unsigned int *)(vga_char_virtual_base);
*/
/*
vga_pixel_virtual_base = mmap( NULL, FPGA_ONCHIP_SPAN, ( PROT_READ | PROT_WRITE ), MAP_SHARED, fd_mem, SDRAM_BASE); //SDRAM_BASE
if( vga_pixel_virtual_base == MAP_FAILED ) {
printf( "ERROR: mmap3() failed...\n" );
close( fd_mem );
return(1);
}
vga_pixel_ptr =(unsigned int *)(vga_pixel_virtual_base);
*/
sdram_lattice_virtual_base = mmap( NULL, 0xE84800*sizeof(short), (PROT_READ | PROT_WRITE), MAP_SHARED, fd_mem, SDRAM_LATTICE_BASE);
if( sdram_lattice == MAP_FAILED) {
printf( "ERRROR: mmap4() failed...\n" );
close( fd_mem );
}
sdram_lattice = (unsigned short *)(sdram_lattice_virtual_base);
//bottom_row = (unsigned short *)(sdram_lattice + BOTTOM_ROW);
/* sram_virtual_base = mmap( NULL, FPGA_ONCHIP_SPAN, ( PROT_READ | PROT_WRITE ), MAP_SHARED, fd_mem, FPGA_ONCHIP_BASE); //fp
if( sram_virtual_base == MAP_FAILED ) {
printf( "ERROR: mmap3() failed...\n" );
close( fd_mem );
return(1);
}
sram_ptr =(unsigned int *)(sram_virtual_base);
*/
if (Fflag){
for (i_fft=0; i_fft= N_WAVE){
for (q = 0; q < N_WAVE; q++)
fi[q] = 0;
pthread_mutex_lock(&sample_lock);
FFTfix_samp();
index_samp = 0;
pthread_mutex_unlock(&sample_lock);
for(q=0;q < N_WAVE; q++){
float s = fix2float(sample[q]);
float i = fix2float(fi[q]);
amp[q] = float2fix(sqrt(s*s + i*i));
//printf("%d = %f , %f\n", q, fix2float(amp[q]), fix2float(fi[q]));
}
}
for(q=0; q>14)*600 && w<480; w++){
for(d = 4; d < 5; d++){
set_point_xy((q*5) + 3, 479 - w, d, 0x000F);
}
}
for(w=480; w<480;w++){
for(d = 0; d < 9; d++){
set_point_xy((q*5) + 3, 479 - w, d, 0x0000);
}
}
}
}
}
void * kevin_spacey(){
unsigned int i = 0;
FILE *fout_sdram;
FILE *fout_lattice;
if(dflag)
fout_sdram = fopen("SDRAM_DUMP.txt","wb");
if(lflag)
fout_lattice = fopen("LATTICE_DUMP.txt","wb");
unsigned int x = 0;
unsigned int y = 0;
unsigned int dir = 0;
unsigned int poop1 = 0;
unsigned int poop2 = 0;
int done = 5;
do{
for (i= 0; i < SPANNN; i ++){
x = (i >> 13 + OFF) & 0x003FF;
y = (i >> 4 + OFF) & 0x001FF;
dir = (i >> 0 + OFF) & 0x0000F;
poop1 = i & ((1<> 23 + OFF) & ((1<<(32 - (23 + OFF))) - 1);
if (poop1 == 0 && poop2 == 0 && (x < 640 && y < 480) && (dir < 16)){
if (x == 100 && y == 120 && !Zflag)
set_point(i, 0x0001);
if (x == 100 && y == 100 && dir == 5 && !Zflag)
set_point(i, 0x0001);
if (rflag)
set_point(i, 0x0000);
if (lflag){
if (dir == 0)
dump_value(x, y, fout_lattice);
dump_point(i, fout_lattice);
}
if (Zflag)
set_point(i, 0x0000);
}
if(x > 640 && y > 480 && !dflag)
break;
if (dflag){
if (i%31 == 0)
dump_newline(fout_sdram);
dump_point(i, fout_sdram);
}
}
done--;
}while((Zflag | rflag) && (done > 0));
printf("CLEANED\n");
if(dflag)
fclose(fout_sdram);
if(lflag)
fclose(fout_lattice);
while(1){
if ( (*(audio_fifo_data_ptr) & 0x000000FF) > 50 && (*(audio_fifo_data_ptr)>>8 & 0x0000FF00) > 50 & index_raw < N_WAVE){
//RIGHT
raw = (*(audio_left_data_ptr)>>1 + *(audio_right_data_ptr)>>1);
sample_size++;
if (sample_size >= 12 && index_samp < N_WAVE){
sample_size = 0;
pthread_mutex_lock(&sample_lock);
sample[index_samp] = raw ;
index_samp++;
pthread_mutex_unlock(&sample_lock);
//printf("%d\t", raw);
}
}
}
} // end main
void dump_point(unsigned int ind, FILE *fout){
unsigned int c = *(sdram_lattice + ind);
char buff[8];
sprintf(buff, "%04X ", c);
fputs(buff, fout);
}
void dump_value(unsigned int x, unsigned int y, FILE *fout){
char buff[15];
sprintf(buff, "\n%03d , %03d = ", x, y);
fputs(buff, fout);
}
//0x0
//x -> 10bits
//y -> 9bits
//dir -> 4bits
void FFTfix(int fr[], int fi[], int m)
//Adapted from code by:
//Tom Roberts 11/8/89 and Malcolm Slaney 12/15/94 malcolm@interval.com
//fr[n],fi[n] are real,imaginary arrays, INPUT AND RESULT.
//size of data = 2**m
// This routine does foward transform only
{
int mr,nn,i,j,L,k,istep, n;
int qr,qi,tr,ti,wr,wi;
mr = 0;
n = 1<>= 1; while(mr+L > nn);
mr = (mr & (L-1)) + L;
if(mr <= m) continue;
tr = fr[m];
fr[m] = fr[mr];
fr[mr] = tr;
//ti = fi[m]; //for real inputs, don't need this
//fi[m] = fi[mr];
//fi[mr] = ti;
}
L = 1;
k = LOG2_N_WAVE-1;
while(L < n)
{
istep = L << 1;
for(m=0; m>= 1;
wi >>= 1;
for(i=m; i> 1;
qi = fi[i] >> 1;
fr[j] = qr - tr;
fi[j] = qi - ti;
fr[i] = qr + tr;
fi[i] = qi + ti;
}
}
--k;
L = istep;
}
}
void FFTfix_samp()
//Adapted from code by:
//Tom Roberts 11/8/89 and Malcolm Slaney 12/15/94 malcolm@interval.com
//fr[n],fi[n] are real,imaginary arrays, INPUT AND RESULT.
//size of data = 2**m
// This routine does foward transform only
{
int mr,nn,i,j,L,k,istep, n;
int qr,qi,tr,ti,wr,wi;
int m = LOG2_N_WAVE;
mr = 0;
n = 1<>= 1; while(mr+L > nn);
mr = (mr & (L-1)) + L;
if(mr <= m) continue;
tr = sample[m];
sample[m] = sample[mr];
sample[mr] = tr;
//ti = fi[LOG2_N_WAVE]; //for real inputs, don't need this
//fi[LOG2_N_WAVE] = fi[mr];
//fi[mr] = ti;
}
L = 1;
k = LOG2_N_WAVE-1;
while(L < n)
{
istep = L << 1;
for(m=0; m>= 1;
wi >>= 1;
for(i=m; i> 1;
qi = fi[i] >> 1;
sample[j] = qr - tr;
fi[j] = qi - ti;
sample[i] = qr + tr;
fi[i] = qi + ti;
}
}
--k;
L = istep;
}
}
/****************************************************************************************
* Subroutine to send a string of text to the VGA monitor
****************************************************************************************/
void VGA_text(int x, int y, char * text_ptr)
{
volatile char * character_buffer = (char *) vga_char_ptr ; // VGA character buffer
int offset;
/* assume that the text string fits on one line */
offset = (y << 7) + x;
while ( *(text_ptr) )
{
// write to the character buffer
*(character_buffer + offset) = *(text_ptr);
++text_ptr;
++offset;
}
}
/****************************************************************************************
* Subroutine to clear text to the VGA monitor
****************************************************************************************/
void VGA_text_clear()
{
volatile char * character_buffer = (char *) vga_char_ptr ; // VGA character buffer
int offset, x, y;
for (x=0; x<79; x++){
for (y=0; y<59; y++){
/* assume that the text string fits on one line */
offset = (y << 7) + x;
// write to the character buffer
*(character_buffer + offset) = ' ';
}
}
}
/// /// /////////////////////////////////////
/// end /////////////////////////////////////