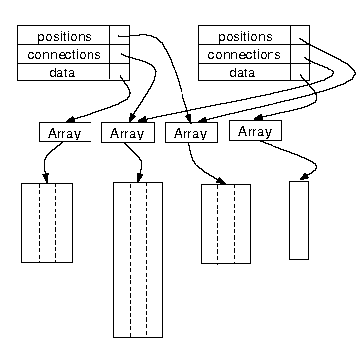
DX Data Model
As mentioned before, the DX data model is different to the file system but has the same
hierarchy. In addition to DX special data structure, we must use the library supported by Data
Explorer when create our own modules. The Data Explorer library is object oriented, that is,
Data Explorer objects are data structures in global memory that are passed by reference, and
whose contents are private to the implementation. Furthermore, different objects could share the
common components.(figure 1)
Some terminology of DX's data model must be introduced before describing the detail
implementation.
Object: An object is a data structure stored in memory that contains
an indication of the object's type, along with additional
type-dependent information.
Field: A field represents a mapping from some domain to some data space.
The information in a field is represented by some number of named
components.
Array: Array objects hold the actual data, positions, connections, and so on.
Attribute: store the relation among different objects.
Regular vs Irregular Array
Irregular Array:is the most general way to specify the contents of an array.
Regular Array:is a set of n-dimensional points lying on a line in n-space
with a constant n-dimensional delta between them, represents.
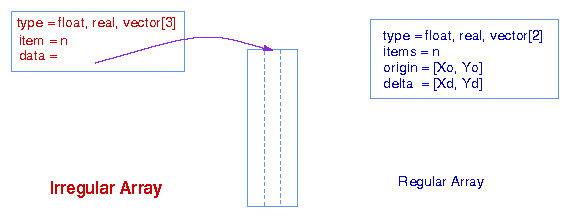
Figure 2. Irregular vs Regular Array
As above description, we could know the regular array do not really occupy memory as its
declaration. Therefore, before apply the compression procedure, we must check the array type of every
member in the input object and ignore the regular array. In addition to the type of array, we must
also get other information about the array, for example, data type, item number, rank, etc. There is
a main difference between array here and the file in file system - no EOF pointer. Hence, we must
get its size before compress it.
Furthermore, after compressed the array, we must store the description of original array because it
must be restored after the execution of decompression module. In addition to the size of array, the
attributes among the objects must keep unchanged. If one of those attributes is lost, the Data
Explorer could not find the references and relations between two objects and would cause fatal error.