
By Tiankan Li (tl245)
Ji Zheng (jz232)
Wednesday 4:30pm

Braille A to Z

BlindAid is
a portable tool that reads Braille and signals close objects. It is ideal for those unfortunate people who just
turned blind and have not mastered Braille reading and blind cane usage. It can
also be used as a learning instrument that helps the user decipher Braille
without constantly going to the Braille dictionary.
Rationale
After
browsing through the website on previous year’s projects, we believed that it
would be a noble act of applying the knowledge we learned from class to help
those who are in need, instead of just developing a toy that only satisfies our
technology savvy.
Since most
Braille we see on the street has standard size.
Instead of image sensing, we decided to use 6 push buttons in a 2x3
matrix. When the buttons are pressed
against the Braille, the buttons corresponding to the bumps on the Braille will
be pushed.
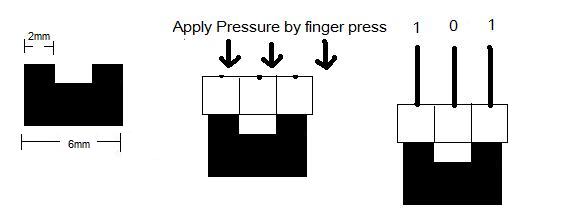
The push
button design not only makes our project more simple and elegant, it also makes
it more affordable to the blind people.
Since our
product is targeted to blind people who didn’t master the Braille reading, we
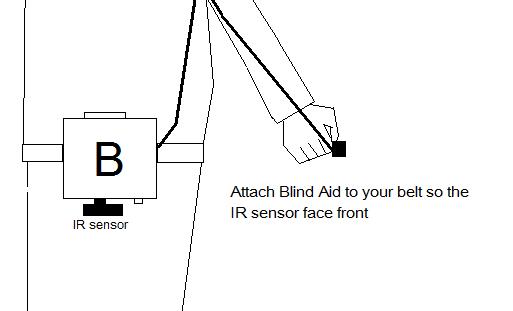
assumed they are new to the blind walking stick as well. Therefore, we attached
an IR sensor to detect whether there is any object close to the user, in hope
to reduce the chance of any unfortunate collisions.
the
horizontal and vertical spacing between dot centers within a Braille cell is
approximately 0.1 inches (2.5 mm); the blank space between dots on adjacent
cells is approximately 0.15 inches (3.75 mm) horizontally and 0.2 inches (5.0
mm) vertically.
Since it is
hard to recognize word by just hear its spelling. We implemented our BlindAid
such that when a full word is inputted, it will pronounce the word when “speak”
Button is pressed.
In order to
increase the range of words the reader is able to pronounce, we decided to use
allophones for speech generation instead of pre-recorded voices.
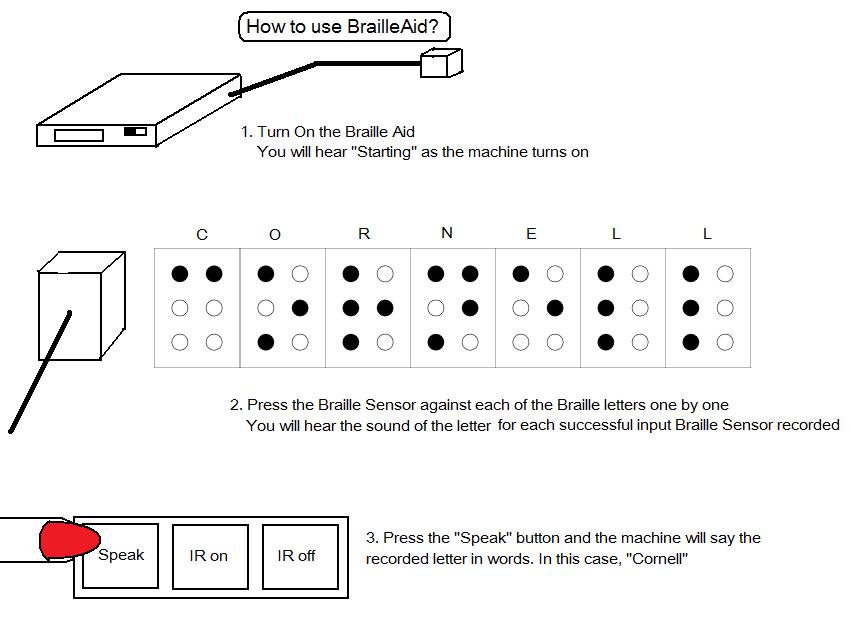
Instructions on Use

Hardware Tradeoff
When
expanding the memory size for the larger dictionary, the time it takes to load
entries from the dictionary onto the chip also increases proportionally.
Fortunately, once the data is written on to eeprom, it remains there so the
data from the dictionary only has to be written there once.
Software Tradeoff
One of the
issues was speed vs. coverage. We wanted
our Braille reader to be able to handle as many words as possible but the
search time increases as the dictionary size increases, because of our linear
search method. We felt coverage was the
most important aspect of our project, which was one reason we decided to expand
from the 32K flash memory to the 2MB eeprom memory.
Relationship of design to IEEE, ISO,
ANSI, DIN, and other standard
Our project
conforms to all IEEE standards to the extent of our knowledge.
Existing patents, copyright, and
trademarks
Our project
does not violate any existing patents, copyright and trademarks. The designs are all our original designs and
any code or data used were open to the public for research purposes and are
referenced in the appendix. The
“BlindAid” image above was made by us using Photoshop.
Main Components

Protoboard –
This is the skeleton of the BlindAid. It holds the Mega32 and supports links to
other components.
SpeakJet
–This is the messenger between the microcontroller and the user. Whenever a button is pushed or a Braille is
read, the SpeakJet will generate a robotic voice and deliver a message to the
user to make sure the user is updated with his/her surrounding.
Mega32 – The
heart of BlindAid. This microcontroller receives data from Braille sensor and
generates the sound output at amazing speed. (16Mhz) It also controllers
different parameters of the BlindAid such as Volume.
Headphone –
In ear design, so clear sound can be transferred to the user without too much
lost from noise.
IR Sensor – The user’s guard dog. It generates a warning message to the user when the user gets too close to a wall in front of him/her.

Braille Sensor – A combination of 6 NKK buttons. This is like user’s eye. It converts Braille to Binary data. (B2B) So the MegaL32 can process the data.

Memory – We
are using a 24AA1025. Each of them is a 1MB eeprom that is used to store words
and their corresponding allophones.

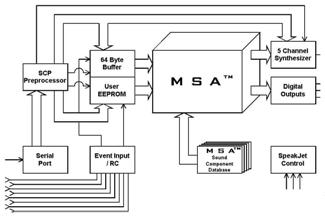
Design
We picked SpeakJet for our project because initially, we attempted to avoid the usage of external memory. Since SpeakJet contains all the allophones required for pronunciation, we don’t have to stack the onboard eeprom with coefficients for allophone generation. We planned to use onboard memory for storing data required for speech generation.
The SpeakJet chip can be setup up in two ways. One for Demo/Test Mode and one for serial control.
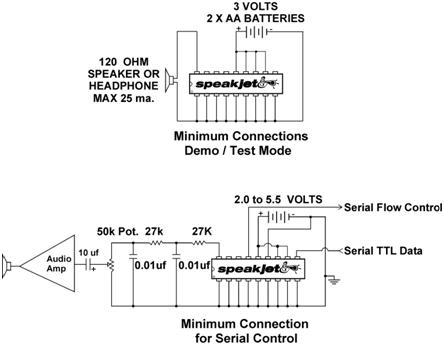
In demo
mode, the chip outputs random phonemes, both biological and robotic. We initially setup the chip to run Demo Mode
in order to test it out. Afterwards, we
connected the chip to the serial interface.
We found that the lowpass filter indicated were unnecessary because the
signal was clean and the lowpass filter only reduced the volume. Serial Data is the main method of
communicating with the SpeakJet. The
serial configuration to communicate with it is 8 bits, No-Parity and the
default factory baud rate is 9600.
These are the same settings used to communicate with the STK500
board. The Serial Data is used to send
commands to the MSA unit
As the project progressed, we
realized that in order to make a quality speech generation system, a vast
library of words and their pronunciation is needed. The onboard flash memory is
only 32kB. Assuming each word takes 8
bytes and its corresponding allophone takes 16 bytes, we can fit only about
1330 word. This is definitely not enough for speech generation. So we decided
to use a 2MB eeprom. With that, we can store about 22182 words, which should
cover most of the word we use in daily speech and some uncommon words.
By the time
we bought the 1mbit eeprom, we already had SpeakJet setup and functioning. For
the sake of time and simplicity, we decided to keep the usage of SpeakJet
instead of storing allophone in the external eeprom and use that for speech
generation.
Each eeprom
is 1mbit. It is made of two blocks of
2^16 bytes. The 24AA1025
eeprom uses Twin Wire Interface(TWI) for data transmission. As its name implies, it uses only two
bi-directional bus lines, one for clock (SCL) and one for data (SDA)
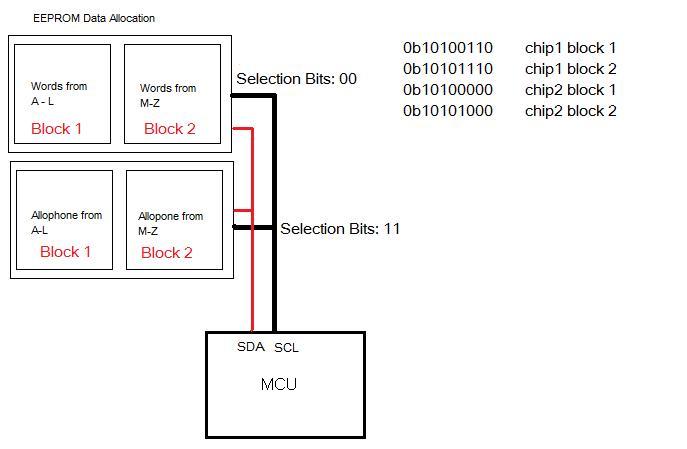
We used a
2000K Ohm resistor on each of those wires for pull-up purposes.
Read
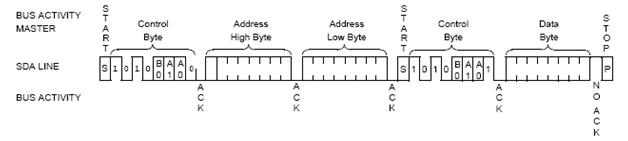
Write
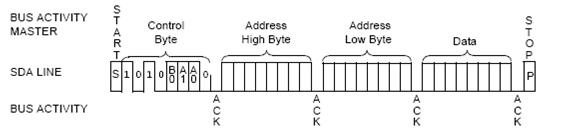
TWI requires
frequent MCU/EEPROM communication. Every
time a signal is send from MCU to EEPROM, an acknowledge signal from EEPROM
back to MCU is required.
Writing to EEPROM
takes a long time for writing. Luckily, we will never have to write to EEPROM
once the dictionary is established. Therefore the long writing time doesn’t
affect our project.
We borrowed
most of our TWI code from AVR library. AVR came with a neat TWI library called
“i2c.h”, which we used for byte write and byte read.
We decided
to use 2 separate power sources because the IR sensor drains a lot of currents
from the power source. Thus creates a lot of noises for the SpeakJet and
worsens the sound output.
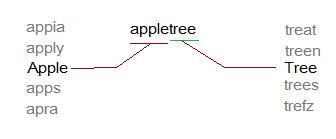
In order to
pronounce the words that are not in our library, our MCU will divide the input
word into existing words. It would break the unknown word down by finding the
longest existing word from our library that matches with the prefix of the
unknown word.
For example:
Input Word: “appletree”
The Braille reader will pronounce: “apple” + “tree”
For data
storage, we put all words in a single character array with “*” between words to
indicate where words start and stop. We picked this design over double
character array because double character array requires same length for each
word. So the shortest word “a” will have
to take the same amount of space as the longest word in our dictionary.
However, the single array made binary search impossible. We have to use linear
search.
In order to
save time with searching, we arranged the words in our dictionary in
alphabetical order and recorded the position for each of the 26 letters in the
alphabet. So instead of traverse through the entire library for searching, it
will only search words that match the first letter.
For timing
purposes, we enabled timer0 of the clock with a pre-scalar of 64 and a
cmp-match of 250 to create 1ms intervals.
To aid us in
developing our speech, we used the Phrase-A-Lator software provided on the
Magnevation website. The software
allowed us to test out the sounds, phrases and different control functions for
the SpeakJet. The software allowed us to
adjust the volume, pitch, speed, and bend.
It was also used in helping us verify that the output control signals
that we were using were correct by comparing the output signals from our
program to that of the Phrase-A-Lator.
The software was easy to use. To
use the software, an audio amplifier must be connected to PortD.1, and the chip
to RXD port of the RS232. After
selecting the correct serial port connected to the STK500, the program was
ready to go.
The site
also provides a small dictionary of approximately 1,200 words with their
corresponding allophones and control signals for the SpeakJet. Initially, we planned to use this dictionary
because it was quite accurate and fit snuggly into our Atmel32 chip, using only
about 48% of the 32K flash memory provided.
We later realized that this dictionary was insufficient because it
lacked many of the common words in the English language.
After some
research, we discovered the CMU dictionary provided by Carnegie Mellon
University for research purposes. The
dictionary contains over 125,000 North American English words with their
transcriptions. The dictionary uses 39
phonemes in its transcriptions.
|
Phoneme Example Translation |
|
|
------- ------- ----------- |
|
|
AA odd AA D
AE at AE T
AH hut HH AH T
AO ought AO T
AW cow K
AW
AY hide HH AY D
B be B IY
CH cheese CH IY Z
D dee D IY
DH thee DH IY
EH Ed EH D
ER hurt HH ER T
EY ate EY T
F fee F IY
G green G R IY N
HH he HH IY
IH it IH
T
IY eat IY T
JH gee JH IY
K key K IY
L lee L IY
M me M IY
N knee N IY
NG ping P IH NG
OW oat OW T
OY toy T OY
P pee P IY
R read R IY D
S sea S IY
SH she SH IY
T tea T IY
TH theta TH EY T AH
UH hood HH UH D
UW two T UW
V vee V IY
W we W IY
Y yield Y IY L D
Z zee Z IY
ZH seizure S IY ZH ER |