
Introduction
For our final design project, we designed and built a prototype acoustic modem to serve as a physical transport layer for digital communications. It converts between a digital communications scheme (RS-232) and an acoustically coupled communications scheme of our own design. Our project consists of a pair of such modems to operate as transmit/receive pairs and supports duplex communications. Although our modem operates in air, it is a proof-of-concept experiment in encoding, decoding, and data transmission techniques that will be used in the following years by the CUAUV team to design a system capable of communicating over some distance underwater.

High Level Design
Rationale | Background Math | Design Tradeoffs | Intellectual Property and Standards
Rationale
We chose this product because of its relevance to a student project team we were both members of, CUAUV (Cornell University Autonomous Underwater Vehicle team). Usually, remote-controlled vehicles use radio frequency (RF) wireless communications to transmit data between the device and its operator. However, due to the nature of water, electromagnetic waves do not propagate well, with an effective range of about a foot, depending on frequency. This makes them unsuitable for communicating with AUVs. Acoustic data, however, can propagate very far underwater and acoustic underwater communications is currently an important area of research at Woods Hole Oceanographic Institute (WHOI). Inspired by their success and the existence of several commercial acoustic modems, our team has as a long term goal the creation of an acoustic modem that can be used to communicate with the vehicle while it is in the water without a tether. Our project serves as a prototype to help us develop our own algorithms and techniques for encoding and processing data acoustically.
Background Math
Because we used cheap audio-range speakers and microphones, our project was limiting to transmitting within the range of human hearing, ~20 Hz - 20 kHz. Therefore, we selected an encoding scheme that minimized per-byte bandwidth utilization while retaining simplicity, so that it was possible to implement decoding. The two most intuitive and basic digital encoding schemes are frequency-shift keying, where data is transmitted on a pair of frequencies, each representing a distinct digital value, and on-off keying, where the presence or absence of a single frequency is used to encode a digital value. We chose the second (OOK) because it requires half the acoustic bandwidth (uses only one frequency per channel, rather than two) to transmit a particular amount of data. We also chose to use an asynchronous design in order to avoid paying for the overhead of having an additional clock frequency, instead breaking the transmissions into a series of known-width pulses. Transmitted data is broken into chunks of 64 samples so as to conveniently fit into a power of two size buffer so that it can efficiently be implemented as a circular buffer. Each physical frame consists of a start bit (S1, a one bit), eight data bits, most-significant-bit first, and a stop bit (S2, a zero bit). At a sampling rate of 40 kHz (chosen to avoid aliasing across the entire 20 Hz-20 kHz range), 64 samples corresponds to a pulse width of 1.6 ms, which limits each frequency channel to transmitting 62.5 complete frames per second as a theoretical max.

Sample Transmission Frame
Next, as we are limited by the computational power of our Atemga644 microcontroller, and we would ideally transmit and receive from a single microcontroller, we designed a hybrid algorithm for detecting transmitted data using FIR filters to estimate the magnitude of specific frequency components over time. For each frequency of interest (which will be derived afterwards), we resample at that frequency, exploiting aliasing to obtain a DC component corresponding to the amplitude of the frequency. Because the cosine of zero is one, the magnitude of the DC component can be estimated with a simple sum of those samples. However, because the real frequency component may have a non-zero phase shift associated with it, at DC it will have an analogous "phase shift" which requires that a second resampler to be used with a 90-degree phase delay-this pair together can estimate the Fourier Transform evaluated at DC for phase and magnitude information.
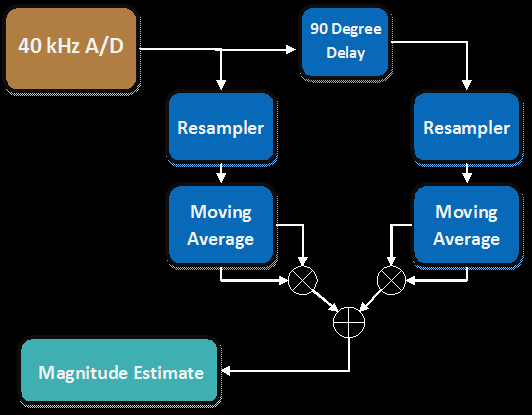
Magnitude Estimation Process Flowchart
However, it is important to consider the effects of aliasing on frequencies OTHER than the frequency of interest. Usually,
aliasing is a bad property to have in a digital system, as it can cause other frequencies to appear as the target frequency.
For instance, when sampling at 6 kHz, the possible aliases that are within our analog pass-band and appear as a DC signal are
true DC, 6 kHz, 12 kHz, and 18 kHz. Therefore, in selecting the frequencies for our transmission channels, if we choose 6
kHz as a transmit frequency, we cannot also use 12 or 18 kHz. Because the Fourier Transform estimator is implemented as a
moving average, it can also be interpreted as an FIR filter, which has a known frequency response. An N-term moving average
filter has a frequency response characterized by a maximum at DC and 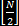 zeros evenly spaced around the unit circle. The
number of terms in the moving average filter for each frequency is chosen by having the length of the filter match the length
of each burst in time (1.6 ms). Because it is unlikely for these to match precisely, the filters are usually defined to extend
one sample longer than the burst. In general, therefore, with sampling frequency fs and target frequency f, the length of the
appropriate averaging filter is
zeros evenly spaced around the unit circle. The
number of terms in the moving average filter for each frequency is chosen by having the length of the filter match the length
of each burst in time (1.6 ms). Because it is unlikely for these to match precisely, the filters are usually defined to extend
one sample longer than the burst. In general, therefore, with sampling frequency fs and target frequency f, the length of the
appropriate averaging filter is 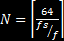 . For example, for 6 kHz, N is 10. Because the window is so short, it is important
to minimize the interference between frequency channels, which is most easily done by having each channel match with a zero
in the moving average for all of the other channels. Due to aliasing between the channels, a particular channel frequency may also
fall on the alias of a zero rather than the normal interpretation of the location of the zero.
. For example, for 6 kHz, N is 10. Because the window is so short, it is important
to minimize the interference between frequency channels, which is most easily done by having each channel match with a zero
in the moving average for all of the other channels. Due to aliasing between the channels, a particular channel frequency may also
fall on the alias of a zero rather than the normal interpretation of the location of the zero.
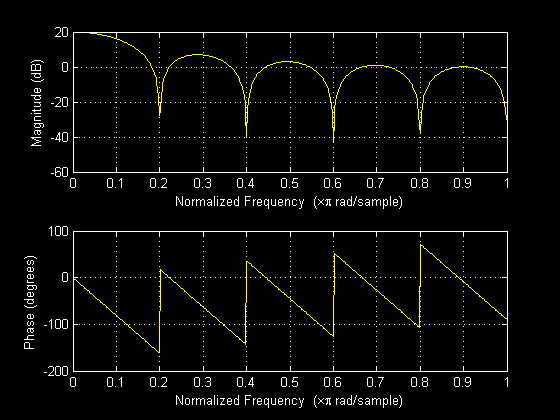
Sample Frequency Response for an 10-term Averager (used for 6 kHz)
Fortunately, it is possible to satisfy the requirement that each transmit frequency alias to a zero of all other transmit frequencies for at least four frequencies in the range 20 Hz-20 kHz. Table 1 lists the zeros for the frequencies we have chosen. Aliases of these zeros occur for each zero plus a multiple of the sampling frequency (4.8, 6, or 7.2 kHz).

Zeros of N-Term Averagers
Finally, because the dip around each zero in the averager's response is fairly narrow, it is important to avoid spectral leakage. Because the data we transmitted is organized into pulses, a window function is implicitly applied to the sine whose frequency we are attempting to transmit. In the case of a naive implementation using a simple rectangular window of uniform amplitude, this leads to significant sidelobes as described on Wikipedia. In an effort to reduce the possibility of spectral leakage, we chose to use a Hann window of equal length to our transmission burst. Other windows may have offered better mainlobe-to-sidelobe ratios, but we felt that the Hann window was sufficient for our purposes.
As is described in the software implementation section, difficulties arise when using the magnitude of the FIR filter outputs alone, which means that naive methods depending on absolute magnitude of a filter's output are insufficient. When processing a single sample from the start of a pulse, with any filter it will appear similar to an impulse, which will cause the output to increase regardless of what the filter's response is to the true frequency of the wave to which the sample belongs, and the output will not decrease appropriately until more samples from the wave are processed. The A/D converters are also limited in resolution (in this case, 8 bits) and all filtering/thresholding is performed in 8 or 16-bit integer arithmetic, because floating point requires too many cycles to emulate, and fixed point introduces complications with verifying that operations like multiply are correct. This places a lower bound on the quantization error that can occur, which leads to additional spectral leakage that can cause false positive bits in frequencies that are not actually present.
Design Tradeoffs
We made two large design trade-offs in this project: (1) we worked primarily with a single +5V supply (except for the +12 input which was also tied to our voltage reference), which limited the total power that we could pump into the output speaker; and (2) we worked with integer and fixed point arithmetic on an 8-bit microcontroller. (1) Using a higher voltage or a double-ended supply would have increased our transmit power (and therefore our range), but the primary point of the project was to develop the software, not to worry about the hardware. The microcontroller could conveniently produce a 0-5 V wave centered around 2.5 V, so we decided to use this to drive the microphone directly (through a simple class A amplifier). (2) Although the Atmega was a requirement for use with the project, designing digital signal processing algorithms for implementation using only fixed point or integer arithmetic requires sacrifices in terms of accuracy which bears a significant cost in terms of data transmission speed and accuracy as our maximum SNR decreases due to resolution. We were also limited by the speed of the microcontroller and the frequency range supported by our microphone and speakers, which meant that we had to sacrifice the higher transmit speeds that would have been possible with ultrasonic frequencies rather than audible ones.
Intellectual Property and Standards
Our project should be free of intellectual property conflicts because we made a conscious effort not to learn about how commercial systems that complete a similar task are implemented. Instead we designed all of our signal processing algorithms, the circuits, and our software based on things that we learned from classes taken at Cornell. Our encoding scheme, OOK, is the only component of our project to have its own Wikipedia page, but we consider it to be a technique in the public domain because of how intuitively obvious it is.
The only standard to which our project conforms is RS-232, which it uses for serial communications with a computer. The RS-232 compliant hardware is included in the Atmega644 UART and so was already prepackaged and ready for use.
Implementation
Hardware | Software: Transmit Receive Client-Side | Trial And Error
Hardware
The hardware for the acoustic modem is relatively simple. It can be broken into four sections: power management circuitry (1), Microcontroller circuitry (2), speaker driving circuitry (3), and microphone processing circuitry (4).

Actual Implemented Circuit Segmented by Functional Region
Power Management - The power managment circuitry consists of an LM34T05 Linear Regulator, which accepts an input voltage of about 9-12 V and produces +5 V. It is capable of driving up to 1 Amp of current without dropping below +5 V, which is necessary to support the class A amplifier implementation used to drive the speaker.
Microcontroller - The microcontroller circuitry is all housed on the custom PC board provided by Bruce Land. The schematic implemented on this custom PC board is reproduced in our schematic listing for completeness.
Speaker Driving Circuitry - An AD7801 D/A Converter is connected to PORT C of the Atmega644. It is driven in parallel with digital samples to be converted to an analog signal. The output of the DAC goes through a 2nd order passive low-pass filter with cutoff at 19.9 kHz to attenuate the high frequencies created by the edges on the DAC output. Next the analog signal is fed through an inverting amplifier with a potentiometer as the feedback loop, allowing us to modify the gain. This is important because the low resolution of the DAC makes it beneficial to synthesize a wave of as large amplitude as possible, but the actual speaker-driving amplifier is not rail-to-rail, so the signal itself must be less than 2.5 V in amplitude. Luckily, analog signals have infinite precision, so information is not lost (although SNR decreases a little bit) by applying less-than-unity gain through this operational amplifier. The output of the DAC is centered around a virtual ground of +2.5 V supplied by the MAX6325 reference, and this virtual ground is maintained up through the speaker driving circuitry.
The speaker is driven with the operational amplifier's output buffered by a common-drain JFET stage followed by a common-collector BJT stage, biased by an active load implemented as an N-channel MOSFET current mirror. The reference current is implemented using a BJT connected by a potentiometer to VCC, allowing us to modify the load current after the circuit has been built, which helps adjust the parameters to account for variations in the discrete transistors used. Originally the op-amp drove the BJT CC stage directly, but when delivering high power near the positive rail, a strange type of instability occurred resulting in the synthesis of several waves in the MHz range. Adding the second voltage buffer to the op-amp output fixes the problem and delivers the wave to the speaker without significant distortion.
Microphone Processing Circuitry - The microphone used is an electret condenser type with a built-in voltage buffer JFET. Following the recommended schematic on the datasheet, the output (and also positive supply) is decoupled through a capacitor, and a very high gain inverting operational amplifier is used to rebias the signal to a virtual ground of +2.5 V. A first order anti-aliasing filter with a cutoff of 19.9 kHz is used, although the microphone itself has a cutoff of 20 kHz, making additional anti-aliasing redundant (but not necessarily unnecessary). The filter output goes directly into PORTA.0 of the microcontroller, the high impedance input for the first A/D channel. In order to attempt to filter out human speech, most music, and most common disturbances that do not directly fall into our target pass band, the microphone processing circuitry implements a band pass filter. It is a narrow, active filter and therefore has a transfer function that is not easily describable in terms of traditional Bode poles and zeros (the pass band is not flat, the rolloff does not match that of a Butterworth filter). Its frequency response is also affected by the microphone, which is not modeled, so a closed form expression is unavailable. However, an approximation based on an ideal voltage source for the microphone was calculated using a SPICE circuit simulator.
Approximate Transfer Function of Microphone Circuit
Software
Transmit
Software Transmit Sequence
The software transmit system is centered around the serial Rx code in the main loop and the waveform lookup in the ISR. The serial Rx code in the main loop is simple: if a serial byte exists in the serial receive buffer, the byte is placed in one of the output channels, scheduled in a round-robin fashion. These channels each have a state-machine status associated with it. When there is no data on a channel, its status is IDLE. Once the serial Rx code places a byte in a channel (only placing the data in an IDLE channel), it sets the status to START_BIT, indicating to the ISR that the channel is ready to transmit the start bit.
The main ISR runs off of timer 1 at 40 kHz (500 cycles @ 20MHz clock); timer 1 also runs a secondary ISR 20 cycles beforehand to put the CPU to sleep in order to ensure consistent timing for the main ISR. The ISR executes the waveform lookup and generation immediately after entry in order to avoid any variable-length instructions that could cause inconsistent timing.Why frequency tables?Previously in class, we generated sinusoids through Direct Digital Synthesis (DDS) through the PWM port. For this project, we significantly simplified our output scheme by utilizing a custom sine table which we placed in the AVR's flash memory. Since there are a limited number of transmit frequencies, we can use Matlab to precompute 64 samples for every possible combination of frequencies. A lookup into flash memory, while slower than RAM access, is much faster than full DDS. The only disadvantage with this scheme is that we must recompute the table every time we wish to change the transmit frequencies or relative amplitudes. To determine which waveform to use, the ISR examines the states of all the channels once every 64 iterations. The states indicate whether the state is IDLE, ready to trasmit the START_BIT (represented by 1S in the figure above), transmitting the Nth bit of the channel (starting with the MSB at 0), or trasmitting the STOP_BIT (represented by 0S in the figure above). The ISR combines the appropriate bit of each channel into a 3-bit number with the MSB indicating the presence of 7.2 kHz, the middle bit indicating the presence of 6.0 kHz and the LSB indicating the presence of 4.8 kHz. This 3-bit number can now be used as an offset into our precomputed 2D frequency table (see sidebar). The first dimension of this table is the 3-bit number which indicates the combination of frequencies we wish to generate. The second dimension is a 64-element array corresponding to the 64 samples in the waveform, with each value directly correlating with a voltage range between 0V - 5V. We manually scaled the amplitudes of the waveforms at generation time to compensate for the differences in the response magnitude of the microphone filter. After determining the correct waveform, the ISR increments the status of all the channels and spends the next 64 iterations outputting the appropriate samples to our DAC on PORT C. The DAC is easy to use: we simply drive the write-enable pin low, load our output onto the DAC's input pins, and drive the write-enabled pin high. The DAC takes care of the rest.
Receive
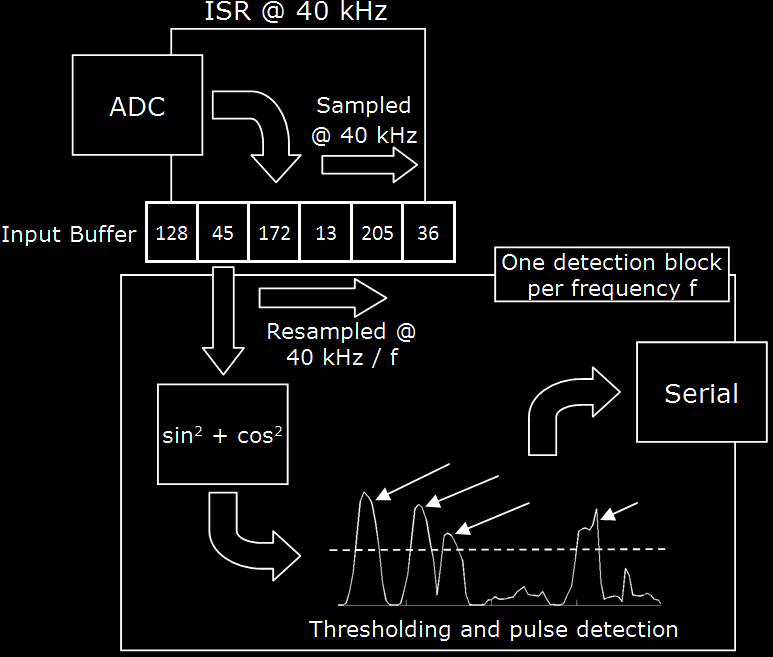
Software Receive Sequence
To receive signals, the main ISR mentioned above plays a minimal role. Every time the ISR is executed (40kHz), it uses the on-board ADC to sample to voltage from the input circuitry and convert it to a signed int8_t by subtracting an offset of 128. This sample is placed into a 64-byte global circular input buffer.
DebuggingWithout a JTAG debugger, it is difficult to see what the AVR is doing. To debug our detection code, we wrote a debug mode that was enabled at compile time through #define macros. While in this mode, the baud rate would be boosted and the AVR would dump raw samples from the ADC out over serial when it detected a start bit. At the same time, we wrote a Matlab script that opened a serial port, transmitted a character, and then listened for the data dump. We could then import this raw data into a Matlab version of our algorithm to test its efficacy.In the main loop, we run a detection block for every frequency of interest. Each frequency of interest has a struct with the appropriate detection parameters; these parameters are generated at runtime based on the frequencies hard-coded into the program. Each detection block runs once for every iteration of the main loop. Each detection block uses the latest input data collected by the ISR. The detection block for frequency f resamples the data (i.e. advances in the input buffer at a different rate) with a frequency of 40 kHz / f. These resampling pointers are stored in a 6:10 fixed-point variable to prevent error accumulation. Four resampled data points are added to the accumulators for four different components offset in phase from each other by 45º. Using four components instead of one prevents phase differences during the resampling process from affecting the data. These four accumulators each store the sum of the past n resamples for their respective phase offset, where n is the number of resamples in one 'frame' (a frame is 64 samples at 40 kHz, the length of one bit). Every time we add a new resample, the oldest one is deleted to maintain our resampling window. From these four accumulators, we calculate the sums of squares of the two accumulators with a phase offset of 90º, i.e. (phase offset 0º)2 + (phase offset 90º)2 and (phase offset 45º)2 + (phase offset 135º)2. These two sums of squares are then averaged to produce our final magnitude.
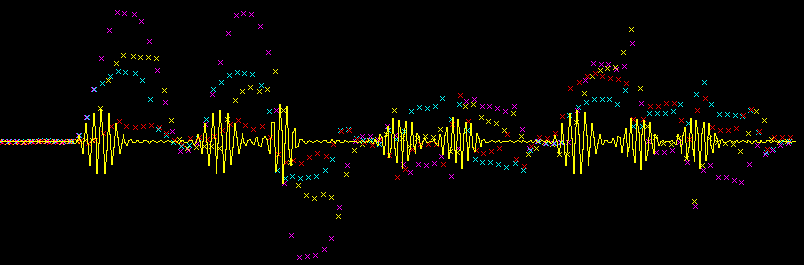
Sample raw data collected by the receive code
The character 'a' was transmitted at 6.0 kHz and the character 'f' was transmitted at 8.4 kHz
The yellow signal line is a dump of raw data collected by the ADC
The x's of a single color represent the value of an accumulator when resampled at 6.0 kHz
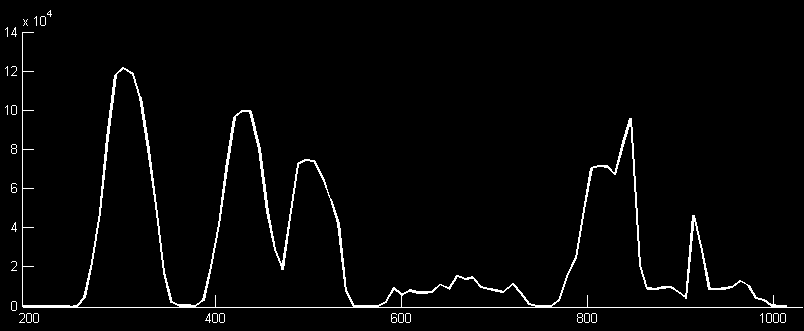
The corresponding final magnitude for the raw data above, resampled at 6.0 kHz
Here, the character 'a' (0b01100010) with the preceding start bit can be seen
As seen above, the final magnitude is representative of the bitpattern received. To detect the peaks, we first apply a manually-tuned per-frequency threshold to the magnitude curve. We tried to choose a threshold that included multiple samples from the peaks of interest above it while keeping noise from other frequencies below it. To begin detection, we search for a start bit. The stop and start bits guarantee that there will be a 0-to-1 transition no matter how dense the data is being sent. To find the start bit, we wait for the magnitude to cross above the threshold. If the magnitude stays above the threshold for a preset time (about 40 samples) or drops below the threshold after a certain time, we move to a start state and prepare to detect subsequent bits. We also align a frame pointer to the end of the start bit so we can track where a frame begins and ends and therefore where to place a bit once we detect it. We are able to do this because the frames are of know size (64 samples). Suppose we set a threshold of 60000 for the sample magnitude above:
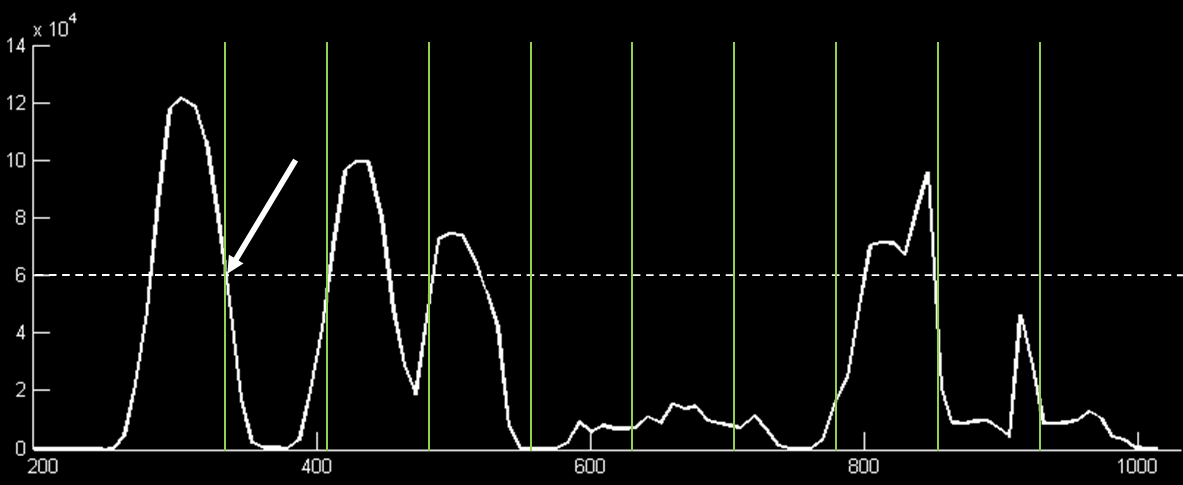
The final magnitude above, after thresholding and detecting the start bit
The dashed line represents the threshold
The arrow points to the time when the start bit was detected
The green lines represent the predicted frame divisions after having seen the start bit
Once we are in the start state, we perform similar detection on subsequent bits. Once the magnitude crosses the threshold, we wait until magnitude falls below the threshold again. If the endpoint happens too soon after the startpoint, the peak is probably a false positive (e.g. a narrow peak that briefly crossed above the threshold) so we reject it. Once we have the start and end points of the peak, we average their positions in time to find the center of the peak. The last step is to find which frame the center of the peak goes into; this is accomplished by a simple division by 64. We can also detect a peak that spans multiple frames; this can occur if the magnitude does not drop below the threshold between frames. If the peak spans more than one frame, we mark all the frames it spans as detected. At this point, we can OR a bit at the position of the frame(s) with the output character to build up our output. The start state ends when we have passed the last frame; at this point, we reset all of our variables and begin looking for the next start bit.
Client-Side
Finally, an additional client program was written to make use of the acoustic modem to transmit data. Based on the OSI Model, the acoustic data modem resides in the Physical layer. Therefore, in order to perform communications at a higher level, a small C++ class was written to implement the transport layer in order to provide quality of service for data transmission over acoustic modem. Using the serial interface provided by Window, formatted data is transmitted through the acoustic modem and received on the other end. Our client program organizes data to be transmitted into packets 6-bytes in length: one byte of header information, four bytes of payload information, and one byte of checksum, which was implemented as an 8-bit CRC. The choice of CRC was based on the way in which errors occurred: single bit errors were much less common than dropped bytes, shifted bytes, etc., so a more robust checksum was chosen to reduce the possibility of an error sneaking through. The transport layer functionality is very simple: a specific bit pattern (0x0A) represents the start of a packet. When the client receives a packet, it computes the CRC of the packet and compares it with what was received. If the checksums do not match, a request retransmission packet is send (header 0x0F, no data, no checksum). If the checksums do match, however, the packet is delivered as received to the calling program, and a successful reception packet is sent (header 0x3E, no data, no checksum). In the event that the transmitting station does not receive anything in response to a transmitted packet, it will attempt to resend the packet up to 10 times before giving up and passing a failure message to the calling program. Checksum invalid and success responses are not acknowledged by the transmitting station. It is understood that if either packet type is not received by the transmitting station within a response timeout period, a retransmission will occur anyway. The client software can be configured to reject the second of two packets with the same CRC as failed acknowledgement, or it can accept both, depending on the appropriateness for an application (for instance, when transmitting binary data, two packets in order may match, but when transmitting text-only communications, two packets in order are very unlikely to match). This transport program was used to implement a simple chat program where two users may communicate via acoustic modem.
Trial And Error
The majority of the trial and error in this project related to tuning the frequency detection algorithm. It is based on static thresholds that are related to the absolute amplitude of each signal. The parameter tuning was done by picking a threshold based on a MATLAB simulation (often using real data obtained using one of our many debug modes), and then pumping a lot of data through the modem and observing the error rates in detection. Our final threshold values were chosen to have very small error rates (no errors within 500+ characters of continuous transmit at approximately 30 bytes/second), although when transmitting closer to the theoretical throughput of the modem, more errors become apparent. Most circuit components were chosen based on the result of SPICE simulations of the circuits in question, but a few result-based substitutions on part values were made, most likely due to differences caused by unmodeled parts of the system (the actual speaker and microphone, which do not operate as pure resistive loads and perfect voltage sources, respectively).
Previous generations of our detection algorithm placed much more emphesis on the alignment of the frame boundaries. Our algorithm used to only check if the magnitude crossed the threshold at the frame boundary, clearing all the accumulators immediately afterwards. A small alignment error (e.g. detecting the start bit late or early) could cause us to miss or shift bits. The current algorithm avoids such strict requirements because there is a range into which the peaks can fall. We completed at least three distinct implementations, including two implementations that were able to detect and decode data on a single frequency with no errors, one of which is the final implementation that we submit because it was better able to support multiple frequencies.
Results
Software Execution | Accuracy | Safety Enforcement | Interference and Accessibility
Software Execution
Due to our avoidance of DDS, we have a copious number of cycles in between waveform synthesis. The synthesis/sampling ISR is called every 500 cycles and takes a few dozen cycles at most. Therefore, only ~10% of our cycles is spent on synthesizing our output and capturing input on the ADC; the rest of the time can be spent on decoding the input. We have not observed any performance deviations as a result of insufficient clock cycles. Because our processing algorithms resample the input buffer and do not look at samples that are not used by a particular frequency, we are able to aggregate all of the CPU time so that we are not limited to 500 cycles per sample but rather that we must process all that we wish from a particular set of 64 samples within 32000 cycles. This aggregate form of processing allows us to avoid certain checks on each sample by iterating through the samples that we are interested in explicitly, rather than checking each sample to see if it should be processed. We have noticed no symptoms of buffer overflows and therefore conclude that our current level of processing fits within the allocated time.
Accuracy
Accuracy can be broken into two categories: accuracy in timing, synthesis of waves, and sampling data; and accuracy of transmission results. For synthesis and timing, we have verified that our project is very accurate, producing the pulses that we desire for the appropriate durations at the appropriate frequencies. We have also verified that it is very accurate in its encoding scheme, consistently producing the same pulse train for the same input data. Both of these features are basic stepping stones that needed to be in place in order to even have a passing chance of successfully transmitting data with any kind of quality of transmission.

Two 1.6 ms Pulses During Transmission at two Frequencies Simultaneously
We have verified that the ISR runs at a consistent rate. By measuring the frequency of synthesized waveforms on the scope, we were able to convince ourselves that the ISR runs at the appropriate speed. The data stored in flash memory only holds relevant in terms of normalized frequency, so if the sampling frequency were to change, the actual frequency measured on the scope would be different from our original intention.
When transmitting with our client program, we are able to make several measurements of data throughput: absolute throughput in terms of number of bytes transmitted, including all protocol overhead and retransmissions; and we are able to measure the number of bytes of actual good data transmitted. In both directions, our actual data transmission is approximately 25-28 bytes/second of correct data as measured by transmitting a 1 KB data set. The throughput of real data, wrapped in protocol and retransmissions, however, is much lower, at between 12 and 20 bytes/second, because the protocol has approximately 33% overhead on each transmitted frame. The actual data transmission speed is significantly lower than the theoretical maximum of 62.5 bytes/second but not unexpected because of the way in which the client program transmits data to the serial buffer. The Atmega644 currently does no serial buffering, so the client program must carefully not overflow the Atmega's buffer, which requires us to throttle the bandwidth in order to ensure there are no serial conflicts.
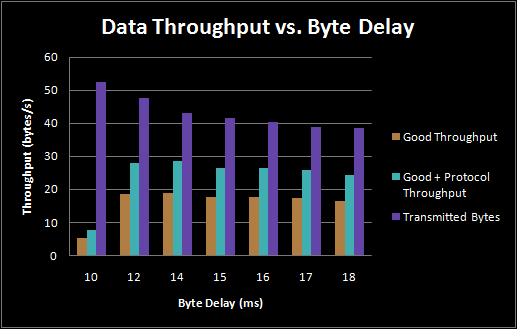
Delay between bytes in a Packet vs. Data Throughput
The optimal delay is therefore in the 14-17 ms/byte range. 16 ms is the precise amount of time it takes to transmit one byte, so it is possible that 14 ms creates enough overlapping packets (transmitting on two frequencies simultaneously) to benefit from the doubled capacity, but not so many as to suffer from the lower bit success rate that accompanies the overlap. Above 16ms there is a maximal speed possible limited by the natural error rate in the acoustic modem channel, and additional delays between bytes do not help.
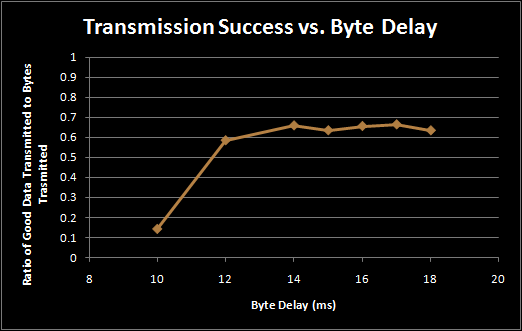
Delay between bytes in a Packet vs. Packet Success Rate
Safety Enforcement
There are only two potential safety problems associated with our project. One is the volume of sound produced by the speaker, which could potentially harm a human if it is too loud. However, our speakers are physically limited to 83 dB at maximum rated power output (3 W), and we drive the speakers at approximately 1/2 W, which should make our actual sound intensity level much lower than 83 dB. This is well below the threshold of pain for human hearing and therefore not a safety hazard, although the sound can become annoying if repeated continuously in an enclosed space. The other safety hazard is the temperature of several components on the board. The linear regular must dissipate nearly 2 W continuosly in order to supply half an amp of current at 5 V, with a 9 V input. This causes it to heat up significantly, and it could cause a burn if a person were to touch the heatsink for more than a brief instant. Similarly, all four transistors in the speaker driving circuit are also extemely hot. The speaker circuitry dissipates a total of approximately 2.5 W, including the power used to drive the speaker itself. Because we do not have a box there is no way to prevent the user from touching one of the hot components, but the speaker mounts and the large output capacitor make it difficult to grab hold of these transistors.
Interference and Accessibility
Our project does not emit electromagnetic radiation of any sort, meaning it will not interfere with most other projects. If it is used near another project that relies on sound for its operation, it may experience some interference, but we restrict the output of our project to a very specific set of frequencies. Therefore, if the other project does not use 4.8 kHz, 6 kHz, or 7.2 kHz, it should not experience any kind of interference due to the operation of our acoustic modem. Our project itself is largely ignorant of other projects. Most human speech and loud music has no effect on its performance, but certain high energy bursts of sound, such as clapping, slamming doors, or screetching charis across the floor can cause the modem to trigger incorrectly once or twice.
Our project is very easy to use. It requires only a serial terminal be open and connected to the device, or it can be used from within an application as an internal data transportation mechanism. It can use existing accessibility mechanisms built into an operating system, such as an onscreen keyboard or a text-to-speech reader, because they are adapted for use with general software that can produce or consume text. The only difficulty in using our project is that it is sensitive to the distance between the two endpoints, which can require some careful calibration when it is first set up.
Conclusion
Analysis of Results | Standards Conformity | IP Considerations | Ethical Considerations | Legal Considerations
Analysis of Results

Speaker Input and Microphone Output Waveforms
An examination of our results reveals that our transmit and single-frequency receive work reliably. As seen in the image above, the waveforms genrated by the output have the correct shape and timing. The microphone receives the correct signal as well, slightly phase-shifted due to the air gap between sender and receiver. Manual transmission of ASCII data over a serial terminal has demonstrated that our error rate is very low (on the order of one bit in 500 bytes) when we only send and receive on one frequency at a time. When we send and receive on two frequencies at the same time, our error rate jumps to one bit per ~10 bytes. When transmitting on all three frequencies, we can transmit the correct byte sequence once in every ~4 attempts. Clearly, overlapping frequencies interfere with detection; detecting on one frequency while another is present can lead to false positives. Attempting to counteract these false positives with a higher threshold can lead to false negatives or shift errors due to missed start-bits. We mitigated some of these shortcomings by implementing our own transport layer to increase accuracy at the expense of throughput. For single frequencies at a time, these problems do not exist and we can reliably tune a threshold that accepts ~99% of all ASCII bytes. For some reason, when the most significant bit is set, our ability to detect the packet decreases significantly (thus errors in the CRC bytes may be reducing our good data throughput when using the client program to guarantee basic QoS, rather than actual data errors), but for the ASCII set of 0-127, we very rarely make mistakes in transmission.
One of the fundamental causes of these problems is the static threshold. These thresholds provide no flexibility in which amplitudes are accepted or rejected; tuning the threshold and then changing the distance between send and receive units can and probably will cause the system to sharply decrease in accuracy. An adaptive thresholding system, while not trivial to implement, would help solve some of these issues. Another way to improve our results is to oversample the data more heavily. With a ratio of 7200 to 40000, there are not many samples per cycle, but if the sampling frequency were tripled then there would be many additional samples. This would enable us to look at additional phase shifts (essentially expand the bank of FIR filters that are averaged to estimate the DC component magnitude), which would significantly improve our ability to reject incorrect frequencies. Using a higher resolution A/D converter or creating an adaptive gain system that maximizes the "volume" of the input signal would also help by allowing us to use larger data types.
Standards Conformity
There are no standards for acoustic modems to conform to that we are aware of, and a survey of manufacturers' websites confirms that they do not list any standards to which they conform. If such standards exist outside our knowledge, it is probably not very important to follow them, as one of the largest manufacturers (Teledyne Benthos) does not list any conforming acoustic modem standards.
IP Considerations
All of the intellectual property relating to the AVR implementation should belong to the two of us, as we consciously did not consult reference implementations of acoustic modems provided by commercial manufacturers (if such references exist). We did not sign any non-disclosure agreements to obtain sample parts. The only sources of information that we used were either example circuits in the public domain (Wikipedia, etc.), the datasheets provided by part manufacturers, or resources provided on the ECE 476 website (code from our projects earlier in the semester). In implementing the client side software, we used an 8-bit CRC implementation obtained from the Quake4 SDK (link unavailable).
We are open to the idea of the reuse of our processing techniques and any publishing opportunities that may arise. Our code and everything that we have a right to distribute (in the event that we have infringed upon a patent or copyright unknowingly) is released under the terms of the GNU GPL, v3.
Ethical Considerations
During the completion of our project, we made an effort to comply with the IEEE code of ethics. We accepted responsibility for the safety of use of our product, disclosing the potential ways in which it could harm a person. We discussed all of the details relating to the only outstanding safety hazard (the temperature of the transistors used). We avoided conflicts of interest by picking a project that is unrelated to previous commercial endeavors that we have been involved with, including previous and foreseeable future internships. We consider our involvement with CUAUV to not be a conflict of interest because the project is being completed specifically in conjunction with CUAUV and for the purpose of inreasing its knowledge base as a team. We were honest and reasonable in our claims of accuracy and results by comparing the results that our implementation was measured to have to the theoretical results that we calculated. We did not accept any bribes (nor were we offered any). We sought assistance, when appropriate, from people more knowledgeable than ourselves, and we answered questions for other groups and offered advice on tasks we had already completed, suggesting things that we had learned through experimentation. We did not discriminate against any people for any reason, and we did not injure anyone for any reason, through action or inaction.
Legal Considerations
There should be no legal considerations with the operation of our acoustic modem. The speakers used are incapable of producing sound above 83 dB when driven at full power (3 W). With our drive power (<1/2 W), we expect to be comfortably below the maximum output. There are no FCC guidelines concerning the use of sound as a data transmission medium, and the overlap between our frequency range and that of human speech likely means that it cannot be regulated. The city of Ithaca's noise regulation ordinance is unclear at best on what types of absolute sounds may be produced, but as our acoustic modem does not interfere with nearby human speech and is most applicable in an industrial environment, its operation should not be in violation of any noise ordinances unless very explicitly and purposely used to annoy a particular person.
Appendix
Source Code | Schematics | Parts List | Task Division | Acknowledgements | References
Source Code
The most recent version of our source code is available under the GNU GPL v3. It can be obtained from our Google Code project via Subversion:
svn checkout http://ece4760-acoustic-modem.googlecode.com/svn/trunk/ ece4760-acoustic-modem-read-only
The repository can be browsed online at http://code.google.com/p/ece4760-acoustic-modem/source/browse/.
An archival copy of the source is also available here.
Schematics
Click on the schematic for a much larger version where all of the details can be seen.
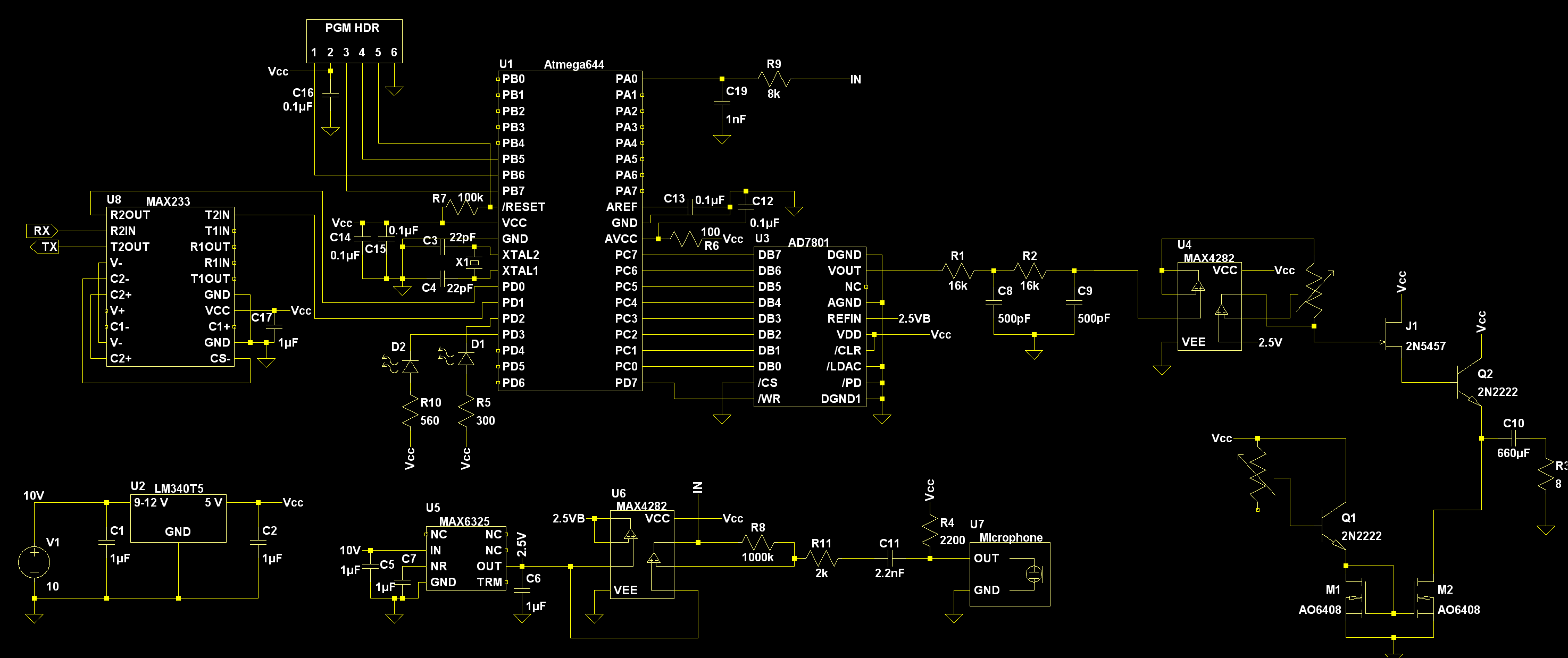
Complete System Schematic
Parts List
Parts listed are per board. Two such boards were constructed to complete a transmit/receive pair.
| Name | Part # | Vendor | Unit Price | Quantity |
|---|---|---|---|---|
| Microcontroller | Atmega644 | Atmel | $8.00 | 1 |
| RS-232 Level Shifter | MAX233 | Maxim IC | Free1 | 1 |
| 8-Bit Parallel D/A Converter | AD7801 | Analog Devices | Free2 | 1 |
| Single/Dual Rail-to-Rail Operational Amplifier | MAX4281/MAX4282 | Maxim IC | Free2 | 23 |
| +2.5 V Reference | MAX6325 | Maxim IC | Free2 | 1 |
| 3 Watt, 8-Ohm Speaker | 668-1125-ND | Digi-Key | $5.03 | 1 |
| Omnidirectional Electret Microphone | 359-1029-ND | Digi-Key | $1.50 | 1 |
| Custom PC Board | N/A | Bruce Land | $4.00 | 1 |
| Solder Board | N/A | 476 Lab | $2.50 | 2 |
| DIP Socket | N/A | 476 Lab | $0.50 | 3 |
| SOIC Carrier Board | N/A | 476 Lab | $1.00 | 3 |
| DB-9 Connector | N/A | 476 Lab | $1.00 | 1 |
| .1" Male Header Pins | N/A | 476 Lab | $0.05 | 85 |
| N-Channel MOSFET | IRFZ34E | International Rectifier | Free4 | 2 |
| NPN BJT | 2N2222 | ST Microelectronics | Free4 | 2 |
| N-Channel JFET | 2N5457 | Fairchild Semiconductor | Free4 | 2 |
| 10k Potentiometer | Any | 476 Lab | Free4 | 2 |
| 1 uF Capacitor | Any | 476 Lab | Free4 | 7 |
| 0.1 uF Capacitor | Any | 476 Lab | Free4 | 6 |
| 22 pF Capacitor | Any | 476 Lab | Free4 | 2 |
| 1 nF Capacitor | Any | 476 Lab | Free4 | 35 |
| 2.2 nF Capacitor | Any | 476 Lab | Free4 | 1 |
| 500 pF Capacitor | Any | CUAUV Lab | Free4 | 35 |
| 20 MHz Crystal | Any | 476 Lab | Free4 | 1 |
| 680 uF Capacitor | Any Electrolytic | CUAUV Lab | Free4 | 1 |
| 8 kOhm Resistor | Any | CUAUV Lab | Free4 | 35 |
| 16 kOhm Resistor | Any | CUAUV Lab | Free4 | 35 |
| 2.2 kOhm Resistor | Any | 476 Lab | Free4 | 1 |
| 1 MOhm Resistor | Any | 476 Lab | Free4 | 1 |
| 2 kOhm Resistor | Any | 476 Lab | Free4 | 1 |
| 10 kOhm Resistor | Any | 476 Lab | Free4 | 1 |
| 560 Ohm Resistor | Any | CUAUV Lab | Free4 | 1 |
| 300 Ohm Resistor | Any | 476 Lab | Free4 | 1 |
| 100 Ohm Resistor | Any | 476 Lab | Free4 | 1 |
| Red LED | Any | 476 Lab | Free4 | 1 |
| Green LED | Any | CUAUV Lab | Free4 | 1 |
| Power Supply (shared) | N/A | 476 Lab | $5.00 | 1/2 |
| Total (per board) | $35.78 | 60 | ||
| Total (altogether) | $71.56 | 121 |
- 1 - Donated by the CUAUV team, which has a stockpile of them but no longer uses the part in active designs.
- 2 - Obtained via free sample from the manufacturer, no NDA required.
- 3 - Three operational amplifiers in total are required. Two 4282s or a 4282 and a 4281 are sufficient to implement the circuit.
- 4 - These parts were already available in either the CUAUV Lab or the 476 Lab for free
- 5 - There was variation in these parts between the two boards. One board used the 16k/500pF combination and the other used 8k/1nF for its low pass filters
Task Division
Greg Malysa

- Hardware Design
- Hardware Implementation
- DSP Algorithm Design
- MATLAB Implementation
- Software Debugging
- Report
- Website
Arseney Romanenko

- Software Implementation
- DSP Algorithm Design
- C Conversion of MATLAB Implementation
- Software Debugging
- Report
- Website
Acknowledgements
We would like to thank Bruce Land and the 476 TAs for keeping long lab hours and helping us with our problems. We would also like to thank the CUAUV team for allowing us the use of team resources to complete our project. We would also like to thank Analog Devices, Maxim IC, and Atmel for donating parts (either to us or to 476 as a class) that made our project possible.
We would like to acknowledge Saurav Bhatia, with whom we consulted a few times about ideas we had for DSP algorithms. We would like to acknowledge Kirill Kalinichev and Emily Lee, from whose project we took the website template to modify. Also, we would like to acknowledge Kevin Fuhr and Chris Peratrovich who fabricated the mounting blocks for our speaker from leftover scraps of ABS stock.
References
Datasheets
- Atmel Atmega644
- AD7801 - 8-bit Parallel DAC
- MAX4281/MAX4282 - Single/Dual Rail-to-Rail Operational Amplifier
- MAX6235 - +2.5 V Reference
Vendor Sites
Other Online Resources
- Description of several window functions and their spectral properties
- Teledyne Benthos
- OSI Model
- GNU GPL v3