point operations. Most applications will not be this compact, and therefore not as fast.
Cornell University ECE4760
Arithmetic
Pi Pico RP2350
Floating and fixed point systems.
Floating arithmetic on the 2040 was quite slow, but on the 2350 floatingis comparable to fixed point.
This is because there is direct hardware support for single precision floating point, as well as a Pi-specific double precision coprocessor for each core. While faster than software, the double precision is slower than single precision. Applications built with the SDK use the hardware floating point (FPU) automatically by default. For example, calculations with the float data type in C automatically use the standard FPU, while calculations with the double data type automatically use the RP2350 double-precision coprocessor.
NOTE-- Be sure to specify precision when using floating point literals. For instance use 1.2f, not 1.2.
The GCC default is to make all literals double precision! Don't do this default unless you really need it!
Fixed point
The fixed point page by Hunter Adams gives a good introduction to the general implementation and motivation for fixed point. Here we want to time the performance of two specific fixed point notations. Ffixed point arithemetic is somewhat faster than floating point on the 2350, and often has enough dynamic range and accuracy for animation and DSP. The two formats are optimized for different computing goals.
The s15x16 format gives good dynamic range for animation and high accuracy for fast cutoff IIR filters. The format s15x16 means16 bits to the left of the binary-point, one of which is the sign bit. The range is +32767.9999 to -32768.0 and the is resolution 2-16=1.5e-5. The range is enough for addressing pixels on a VGA screen, for example, and not worry too much about overflow. Since a full 32-bit number requires several 32-by-32 multiplies, s15x16 format is not as fast as s1x14 because the hardware multiplier is limited to a 32-bit output.
The s1x14 format means two bits to the left of the binary-point, one of which is the sign bit. The range is is +1.9999 to -2.0 and the is resolution 2-14=6e-5. This format is most useful when memory is limited, and the dynamic range of values is small and predictable. Analog-to-digital input is an obivious application. The range is strictly limited to 12-bits, of which the two LSB are somewhat noisy and can often be ignored. The 12-bit size fits nicely into a 14 bit fraction, with a couple of bits extra. This format is good for implementing FFTs on ADC data, or for FIR filters. These algorithms usually produce multiplications with numbers less than one, and so do not overflow the limited dynamic range.
Float vs Fixed Execution speeds
Execution speeds are for the standard clock rate of 150 MHz for rp2350 and 125 MHz for rp2040, and complier optimization -Ofast. The microsecond core timer was used to time execution of loops. The times include realistic loop overhead, as well as the time to store/retreive variables. Three operations were timed: Multiply and add (MAC), divide, and square-root. The MAC operation is used widely in filter operations and FFT. The calculations were each interative, but had to be chosen carefully so as not overflow s1x14. Raw data is shown below, then a table of speed ratios compared to floating point. For this code, there is no speed advantage to fixed point for the MAC operation, and a slowdown for divide and square root. However, for larger codes, with more data motion, the rates may be different. Some examples are below.
rp2350
input iterations: 100
Time in microseconds, then the actual loop value to check accuracy. ffptime 6 fp_mac 1.352407 fix16time 6 fix_mac 1.350418 fix14time 7 fix_mac 1.340637 fptime 11 fp_div 0.369712 fix16time 76 fix_div 0.369431 fix14time 7 fix_div 0.369568 fptime 86 fp_sqrt 2502.377197 fix16time 193 fix_sqrt 2502.373779
| op and speed ratio | float | s15x16 | s1.14 |
|---|---|---|---|
| MAC | 1 | 1 | 0.85 |
| divide | 1 | 0.14 | 1.5 |
| sqrt | 1 | 0.44 | --- |
rp2040
Iterations count: 100
Data is time in microseconds, then the actual loop value to check accuracy.
MAC
fptime 138 fp_mac 1.352407
fix16time 40 fix_mac 1.350418
fix14time 9 fix_mac 1.340637
DIVIDE
fptime 84 fp_div 0.369712
fix16time 53 fix_div 0.369431
fix14time 29 fix_div 0.369568
SQRT
fptime 303 fp_sqrt 2502.377197
fix16time 217 fix_sqrt 2502.373779
| op and speed ratio | float | s15x16 | s1.14 |
|---|---|---|---|
| MAC | 1 | 3.4 | 15 |
| divide | 1 | 1.6 | 2.9 |
| sqrt | 1 | 1.4 | --- |
Float/Fix application - Mandelbrot Set (Hunter Adams)
The Mandebrot set calculation requires lots of memory for the display, but the iteration calculation is quite compact and fits nicely into the floating point registers without much load/store activity. The result is that the fixed and floating solutions run at about the same speed, with the fixed point solution 5 times as fast as rp2040 and the floating point solution about 35 times faster. Floating point rate works out to about 50 MegaFlops/core. The video shows the top half computed in s4x28 fixed point and the botom half in single precision floating point hardware.
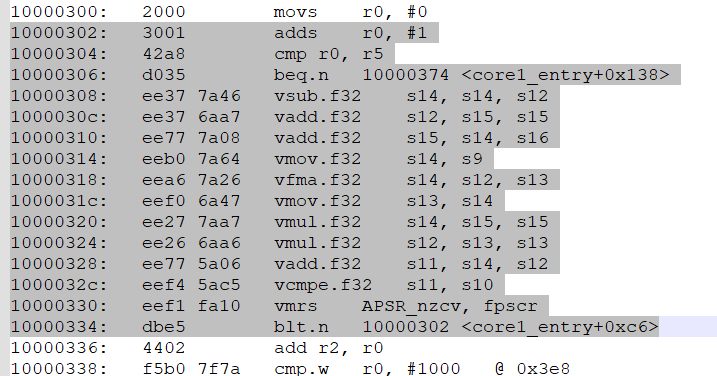
An excerpt fom the C-generated assembler code shows that the inner loop interation (in gray) is mostly floating
point operations. Most applications will not be this compact, and therefore not as fast.
Float/Fix application - Lattice Boltzmann solver
The Lattice Boltzmann solver requires a lot of memory for data and is probably more representative of a large floating point calculation in terms of data motion, indexing, and arithmetic. For a simulation that fills rp2350 memory, the fixed point solution is about 1.6 times faster than floating point. For a 200x40 grid, the fixed point takes 12 mSec/time step, and the floating point about 20 mSec. Floating point rate is about 23 MegaFlop/core. The first video is the fixed point solution, the second is the floating point flow solution. The simulated fluid flow is left to right, with a small vertical barrier near the left end. The Reynold's number is high enough to cause a von Kármán vortex street to form downstream of the barrier. Fluid speed is color coded. Around 200 particles are advects through the flow field.
Daniel V. Schroeder at Weber State University has written a good explaination of LB, as well a very nice interactive javascript simulation. We ported the javascript to C then optimized it for the rp2350. The alogrithm is a memory hog, requiring about twelve arrays of dimension equal to the total number of grid cells.
Code(fixed), Code(float), Project ZIP
Copyright Cornell University March 22, 2026