Implementation Process
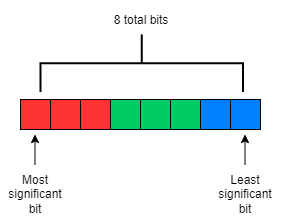
Figure 3: 8 bit color
When starting this project, we unfortunately received a broken camera, leaving us with only one that functioned. We therefore felt an appropriate first step with our current hardware was to implement an anaglyph image from a single camera with a constant shift between red and cyan filtered images. The Video In subsystem utilized an 8-bit color format of [RRR GGG BB], illustrated in figure 3, which provided 8 levels of intensity for red and green, and 4 levels for blue. To obtain a red filtered image, we logically AND'ed each pixel with the bitmask [111 000 00]. This zeroed out all green and blue components but retained the red components. Similarly for the cyan filtered image, we used the bitmask [000 111 11] to zero out all red components but retain the blue and green portions.
In order to produce this shift, we created a buffer that stored color values for a certain number of pixels, then performed Video In reads and VGA writes at addresses offset by the size of the buffer. As a result, we had to carefully manage the offset between the read and write addresses, since the pixel we were writing to the VGA depended on multiple pixel values.
We recognized that this would likely not produce the desired effect since a constant offset is not able to encode depth information. However, this served as a proof of concept for taking advantage of spatial locality using buffers, rather than having to repeatedly read from the same memory address to access the same data.
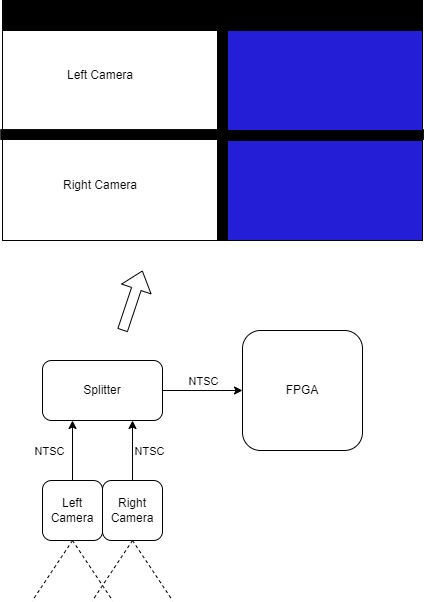
Once we had two working cameras, we created an FSM that first read a pixel color from the top video and then the bottom video, and then logically OR’ed the bit masked values together to produce the final color, which was written to VGA memory. The challenging part of this step was determining how the video splitter divided the 320x240 screen in displaying the different videos. After this was working, we spent most of our time restructuring the Qsys setup to support our depth map.
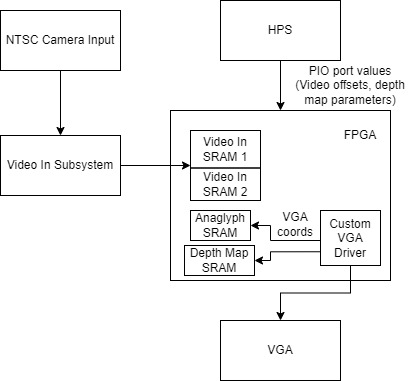
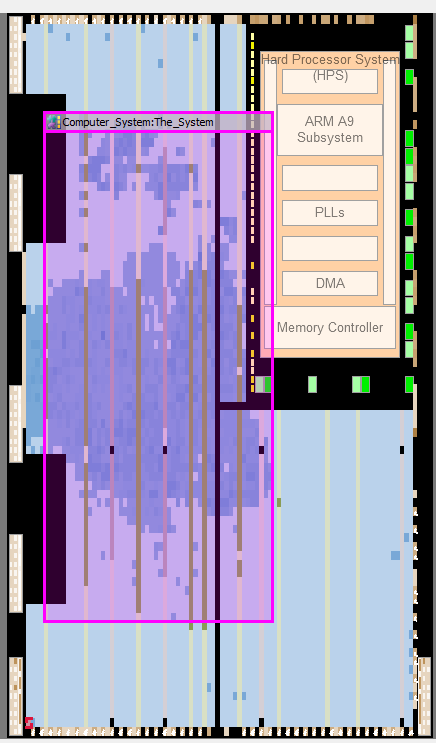
Figure 4: Block Diagram
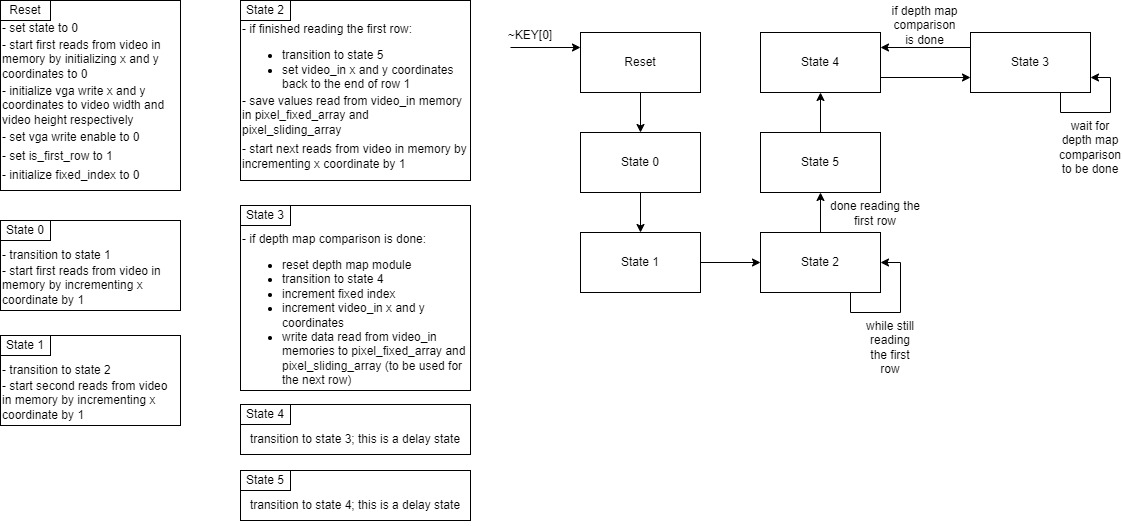
Figure 5: Video In FSM
Depth Map
To implement our depth map, we read in a row from each image at the same height. We take a fixed group of N pixels from one and scan groups of N pixels from the other until we find a matching set, and then record the distance between them. We repeat this process for each overlapping group of N pixels in the first row, and then for every row in the image. We determine the similarity between two pixels by taking the Euclidean distance between their red, green, and blue values. We can then determine the similarity between two groups of pixels by summing up these Euclidean distances. If this sum is below a threshold, we consider these groups of pixels as a match. Colors in the depth map are then assigned based on distance. To avoid an expensive square root calculation, we instead compared the squared distances. This color mapping was tuned by hand, and we eventually settled on 9 bins: (1,10), (10,20), (20,30), (30,40), (40,50), (50,60), (60,70), (70,80), (80,90), and a default case which primarily caught 0 distances.
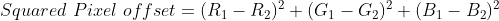
Figure 6: Equation for the pixel distance
In order to meet the timing requirements associated with real-time video and avoid memory bottlenecks, we had to carefully manage our memory reads and writes. Our main optimization was to concurrently read in new pixels into the arrays as we progressed through the groups. Due to our stereo camera setup, one of the images we received was shifted left and the other shifted right. So for a group of pixels in the right image, we knew its matching group of pixels in the left image must be at an index of greater or equal value. For example, if a group of pixels in the right image covered indices [50, 55], then the matching group of pixels in the left image must be somewhere in the indices [50, 164]; indices [0,49] did not need to be considered. Therefore, indices [0,49] could be overwritten with values for the next row's pixels.
The utilization of spatial locality meant that despite having to perform more involved calculations with data spanning across an entire row in the video, we were still doing the minimum amount of reads necessary. In addition, after the warmup associated with reading the first row, we did not have to wait more than one cycle after a read. Pipelining our memory interactions allowed our depth map to run in real time with the video. This was achieved by reading in a new value from the next row as we increment the value of our fixed index.
This simple algorithm worked surprisingly well, producing an image that discernibly showed near and far objects. When testing with a plain black piece of foam, we could clearly see the color transitions as we moved it away from the camera. However, we noticed that in the middle of the square there was a section of 0 distance, regardless of how far away it was. We believe this was due to the low resolution of the cameras, and without features in the middle, the first set of pixels tried was a match. We had a similar problem with people standing and our hand moving in front of the camera, so we think that a video with higher resolution or a more advanced algorithm could overcome this. Interestingly, in its current form the output worked better as an edge detection algorithm than a full depth map. This is another aspect of stereo cameras that we would have liked to explore given more time.
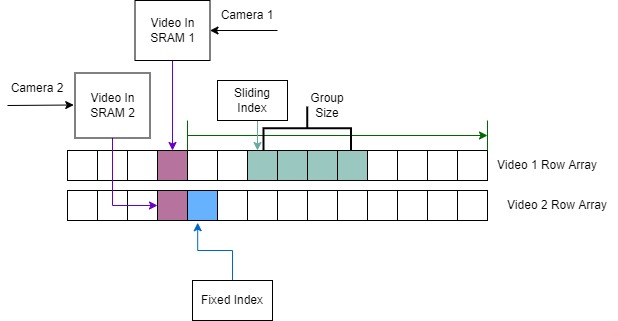
Figure 7: Our strategy for pixel comparisons in the depth map calculation
Depth Map Challenges
The two cycle memory read delay led to much difficulty in correctly mapping the data from Video In memory to its appropriate index in the array, since the read address was offset from the incoming value. This was most apparent when utilizing register arrays to store data for a row of video pixels. Our depth map module only interacted with these arrays and was not concerned with how the values were read from memory. This meant that after resetting the system, the arrays needed to be populated before utilizing the output from the depth calculations. The two cycle read delay necessitated waiting two additional cycles after the read address reached the last pixel in the first row in order to completely fill the first row. We identified this problem by studying the waveforms from Modelsim.
HPS: C Code
As with many of our previous labs, our C code was used as a command-line interface to set parameter values on the FPGA. This was done using a total of 16 PIO ports, all connected to the lightweight AXI bus. Nine of them were for setting color boundaries of our depth map so we could tune the sensitivity. This allowed us to more easily identify the relative shift amount between objects in the background and foreground. We also had two more PIO ports associated with the depth map. One was for the number of pixels in each group being compared (i.e. the number of pixels). The other was for setting the threshold value, which determined if pixel groups were similar enough to be considered a “match”. These PIO ports were established out of convenience, since they allowed us to tune the parameters of our depth map without having to recompile our verilog code.
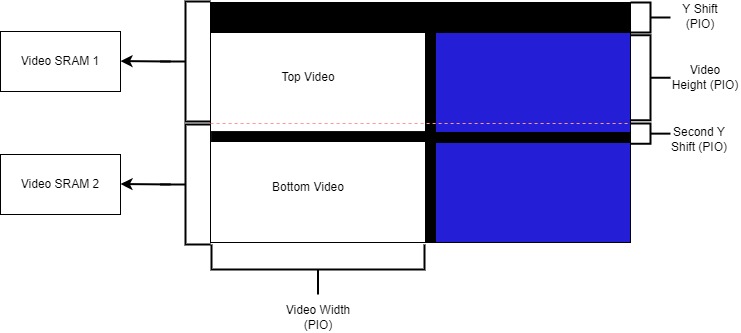
Our other five PIO ports were associated with the videos we displayed to the VGA screen as illustrated in figure 1. Two of them were values for the height and width of the videos output by the video splitter. This was important because we were unsure about the exact dimensions of the videos in the video splitter, and finding these values experimentally was more efficient. We also had two PIO ports for the y-offset of the heights of each video. These were necessary because not only were the videos output by the splitter at different heights but there were also black bars at the top and bottom of the videos creating discontinuities between images. Therefore, the locations in memory corresponding to the top of each video were different, so we needed to tune these values to properly overlay the two videos. The last PIO port was added to set an x shift amount for our video but was never actually used.
Within the C code, the address of each PIO is obtained by adding a specified offset to the lightweight bus address. All PIO ports are spaced out by a minimum of 16 bytes. We set initial values for each of the PIO ports and then run an infinite loop in our C code, which contains a large switch statement. The loop prompts the user for an input character, y (y shift), d (second or “dos” y shift), w (video width), h (video height), g (group size), m (max pixel distance threshold) or n (depth numbers to alter pixel colors). We read in the input character using the scanf function and then enter a case in the switch statement based on the value. In each case of our switch statement, the user is again prompted to input a value, but this time the number they wish to set the chosen parameter to. The only exception is for depth numbers input which also prompts the user to input which depth value they would like to change, as there are nine in total. The default case for all our switch statements simply print to standard-out that the user entered an invalid command.
An interesting fact we learned earlier on in the course is that when reading a character from standard-In using scanf(“ %c”, &myChar), placing a space before the %c automatically tells the program to ignore extraneous the newline character that is obtained when the enter key is pressed.
Things you tried which did not work
When modifying the configuration of Video In memory, we attempted to split it into more than just two different blocks. We wanted to further parallelize the reads from Video In memory by breaking it into smaller blocks and taking advantage of the increased number of read/write ports. However, because we were utilizing the Video In Subsystem from Qsys, these memory blocks needed to also be instantiated in Qsys. This introduced the unforeseen limitation of SRAMs needing to be page-aligned on the bus. Further dividing our memory caused them to be smaller than a page, meaning the SRAMs were not continuously aligned and data was getting lost.
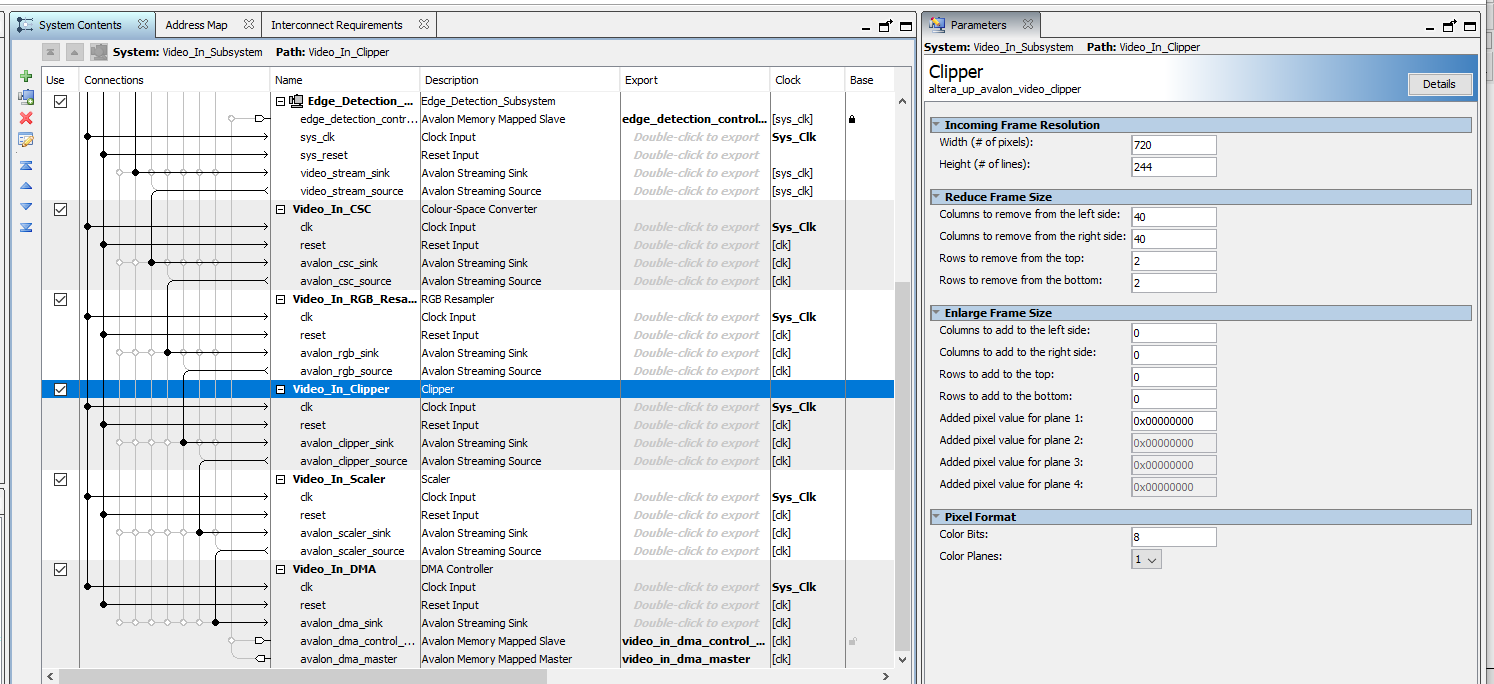
Figure 8: Video In Qsys
In addition, the black bar introduced by the video splitter meant that the two videos were not cleanly divided between the two blocks of memory. We attempted to solve this issue by modifying the amount that the input video was getting clipped in the Video In Subsystem (figure 8). Originally, the input was of size 720x244, and was then clipped by a total of 80 pixels horizontally and 4 pixels vertically. After being clipped, it was then horizontally compressed by a factor of 2. We tried increasing the amount being clipped at the top so that the first video would fit entirely in the first half of memory, since we figured that clipping it to a size smaller than 320x240 should not change anything. However, this strangely resulted in green dots appearing in our image. We suspected it was from the blue bits getting clipped and overflowing to green, but were unsure as to what caused this. However, even after reverting our changes, the green dots still persisted. In the end, we were never able to figure out the exact cause of the problem, but reverting back to another version allowed us to escape this issue. To get around the overlapping memory issue, we simply changed the video height to not include the small section of the top video that existed in Video SRAM 2.
In our depth map output, we strangely encountered colored vertical bars on the right side of the screen. We believe this is caused by the depth map reaching the end of the video without finding a match, but were unable to identify the exact source of the issue. Given more time, we would have liked to further debug this issue.