IEEE754 floating point is very stable, well thought out, and expensive to run on small FPGAs. Full IEEE 754 floating point (FP) format uses a lot of hardware resource on the FPGA. For parallel DSP it would be nice to have a simpler, narrow word FP. Some papers (Fang, et.al., Tong, et.al., Ehliar, et.al.) suggest that only 9 to 11 bits of fraction is enough for video or audio encoding, as long as there is sufficient dynamic range supplied by the exponent. Students have written 18-bit fraction systems that fit well into one-half a Cyclone5 DSP unit for multiply and takes one cycle for a floating multiply and two for an floating add.
A student (Mark Eiding, 2015) made an 18-bit fraction system for faster inverse square root (for gravity calculations) based on a system by Skyler Schneider, 2010. See the DE2-115 floating point page for more details. Tyrone Whitmore-Wilson, Raphael Fortuna, and Nick George in the 2023 class found a bug in the inverse square root which added a cycle. Their version of all the floating point is at the above link.
bit 26: Sign (0: pos, 1: neg)
bits[25:18]: Exponent (unsigned)
bits[17:0]: Fraction (unsigned)
(-1)^SIGN * 2^(EXP-127) * (1+.FRAC) 1, and does not need to be stored. -25.0
((-1)**1) * (1.100100000000000000) * (2**(131-127))
-1 * 1.5625 * 16
1 10000011 100100000000000000 (Note that the integer part of 1.1001 is not actually stored)
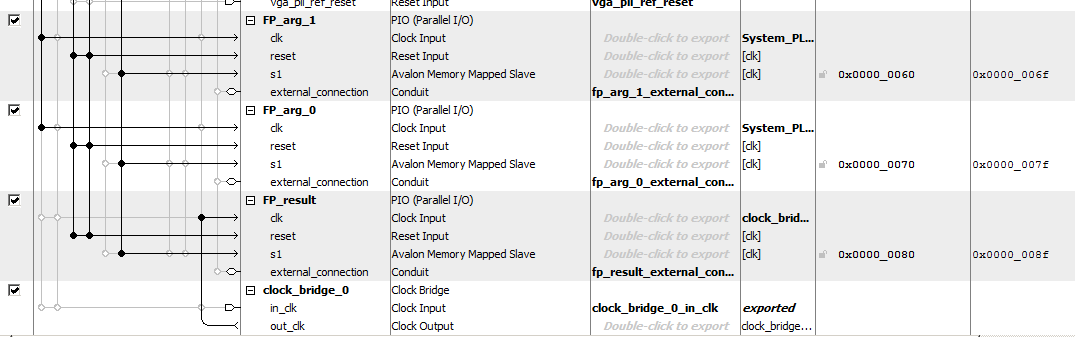
0x60E4000 I ported Mark's system to the Cyclone5 and (hopefully) fixed one small bug. For testing, the adder and multiplier were instantiated on the Cyclone5, attached to Qsys PIO bus-slaves which attach to the HPS light-weight bus. This connection allowed the HPS to test the floating hardware. The HPS program sends two 27-bit floats to the floating hardware, and receives back one float or integer. The HPS program also prints the float, hex and integer equilavents of the output. The top-level Verilog module uses switch settings on the board to choose which arithmetic module is attached to the output bus-slave. Switches are also used to set the shift-factor for FpShift.
(HPS program, top-level, ZIP)
A simpler test program just copies the two adder arguments to shared sram, then adds them in a short state machine arranged to check the timing of the combinatorial floating adder module (FpAdd_c). The HPS program also prints the total transaction time on the VGA for the bus transactions. The VGA bus-master is still in the Qsys description, but is unused in this example. (HPS program, top-level verilog, ZIP). The verilog has switch settings to choose number of cycles required for addition, but one cycle, at 50MHz, seems to work for the combinational adder. Actually, you can chain up to three additions in one cycle of 50MHz. The FPGA resource used for one floating point combinatorial adder is about 550 ALMs.
| FpAdd(clock, fp_in1, fp_in2, fp_sum) | Floating add with two-cycle pipeline, I modified the underflow flag calculation, because there seemed to be an error when subtacting two nearly equal numbers. (Mark Eiding) |
| FpAdd_c(fp_in1, fp_in2, fp_sum) | Floating add (combinatorial), modified from above. Seems to work at 50MHz clock. (Mark Eiding code, pipeline removed) Requires 550 ALMs. Three chained adds/50MHz clock. |
| FpMul(fp_in1, fp_in2, fp_product) | Floating multiply using combinatorial circuit. (Mark Eiding) |
| FpInvSqrt(fp_in, fp_reciprocal_root) | Floating reciprocal square root with five cycle pipeline. One more multiply converts inverse square root to square root, or to reciprocal. (Mark Eiding) |
| FpNegate(fp_in, -fp_in) | Floating sign negation. Flips the sign bit. |
| FpAbs(fp_in, |fp_in|) | Absolute value. Zeros the sign bit. |
| FpCompare(fp_in1, fp_in2, in1>=in2) | Returns either less-than or greater-than-or-equal, but you should read this. output is 1-bit binary. |
| FpShift(fp_in, 8_bit_in, fp_shifted_in) | Floating shift for fast multiply by powers of two. In1 is a float, shifted by a 8-bit, 2's complement value in in2. Positive in2 gives left_shift. Just increment/decrement the exponent. NO bounds checking on exponent overflow/underflow! |
| Int2Fp(integer_in, fp_out) | Convert 16-bit, 2's complement integer to float format. |
| Fp2Int(fp_in, integer_out) | Convert float to 16-bit 2's complment integer (+/-32767) with saturation. Truncates fractions. |
| The following conversion utilities run on HPS: |
----------------------------------------------------------------- |
unsigned int floatToReg27(float) |
Takes a C float and converts to 27-bit format for output to FPGA hardware modules |
float reg27ToFloat(unsigned int) |
Takes a 27-bit value from a FPGA input and converts to a standard C float. |
An older page shows a 9-bit floating point system that I wrote.
Fang Fang, Tsuhan Chen, Rob A. Rutenbar, Lightweight floating-point arithmetic: Case study of inverse discrete cosine transform, EURASIP J. Sig. Proc.; Special Issue on Applied Implementation of DSP and Communication Systems(2002)
Fang Fang, Tsuhan Chen, and Rob A. Rutenbar, FLOATING-POINT BIT-WIDTH OPTIMIZATION FOR LOW-POWER SIGNAL PROCESSING APPLICATIONS, http://amp.ece.cmu.edu/Publication/Fang/icassp02_Fang.pdf (2002)
Jonathan Ying Fai Tong, David Nagle, Rob. A. Rutenbar, Reducing power by optimizing the necessary precision/range of floating-point arithmetic, IEEE Transactions on Very Large Scale Integration (VLSI) Systems, Volume 8 , Issue 3 (2000) Special section on low-power electronics and design Pages: 273 - 285
Eilert, J. Ehliar, A. Dake Liu, Using low precision floating point numbers to reduce memory cost for MP3 decoding, IEEE 6th Workshop on Multimedia Signal Processing, 2004 : 29 Sept.-1 Oct. 2004 page(s): 119- 122
Copyright Cornell University May 24, 2023
{kind=link}
{kind=link}