Computer Vision based
Ball Catcher
| Introduction |
| Design |
| Object Recognition |
| Catching the Ball |
| Pictures & Video |
| Source Code |
| Contact |
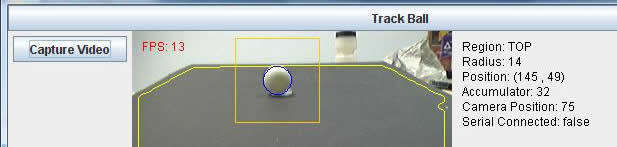
| Object Recognition |
Capturing:
float red = (pixels[index] >> 16) & 0xff;
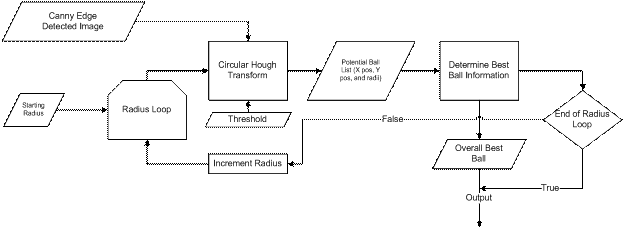
float green = (pixels[index] >> 8) & 0xff; float blue = (pixels[index]) & 0xff; pixels_gray[index]= (int)(red*.3 + green*.59 + blue*.11); After we have converted the image to grayscale, the next thing we want to do is define the region of interest. In our setup we want the region of interest to be everything that pertains to the black sheet. Due to variations in lighting, the fact that surrounding bodies may have colors of the same as the sheet, and other issues, determining the black sheet is not as easy as a simple black thresholding. In order to calculate the region of interest, we first have to make a few assumptions. One assumption is that what the camera is currently looking at should be dominated by the black sheet, and that at the bottom of the cameras view we will always see the black sheet. To account for the lighting in any given situation we take five regions in the image. They are centered in the top, bottom, left, right, and center of the image. Each region is 7 x 7 pixels big, and the average values of these pixels are computed. We then take the highest and lowest average values and throw them out. Out of the three remaining regions, we take the average of their values. This value is what we believe to be representative of the black colored sheet in any lighting. After we have the hypothesized average pixel value of the black sheet we then compute the Sobel operator in both the X and Y directions to compute the gradients of the gray scale image. Next, using assumption number two that the bottom center of the camera will always be in the black region we implement a recursive function that starts at this point and searches for other similar intensity pixels and marks them as the black sheet or not. The way this works is that it moves to the right checking to see if the pixel value is within a percentage of the average and that the X and Y gradients are less than a possible edge value (because we don’t want to continue off the edge of the sheet or into the ball). Once it cannot go right, it searches up, then left, and then down. The recursive search effectively marks the entire black sheet as the black sheet, with very little error. However, to account for some error, and to compute the polygon region of interest, we have to perform the following steps. The algorithm then starts in the bottom left of the image, and moves to the right, until it finds the third marked pixel as a sheet and adds that to its edge list. Then it moves up until the top of the image. Once it reaches the top it performs the same steps, but not starting from the left side and moving to the left until it reaches its third marked pixels to set as an edge for the polygon. After this is all complete, we have defined what we believe to be the black sheet. The next step in finding the ball is to perform edge detection on the image. Our method of edge detection is a Canny edge detector. This edge detector works by first convolving the image with a Gaussian slight blurring filter. This helps to remove noise from the image that could give false edges, while preserving dominant edge structure. Next, it calculates the X and Y gradients using the Sobel gradient operators. After this, a gradient magnitude is computed at each point. If the magnitude is greater than a threshold in which we are certain is an edge, it is marked as an edge, and if the magnitude is less than a certain threshold, it is marked as not an edge. For the middle regions, we look in the local region of the pixel to see if it is the greatest for its given direction, and if it is locally the highest, we then mark it as an edge. The end result is an array with two values, one indicating an edge, the other not an edge. We use a circular Hough transform (CHT) to find the ball in our image. The inputs to the CHT is the Canny edge detector array, a radius value, a threshold, and a region of interest. A CHT works by going to each pixel marked as an edge and it then traces a circle with the specified radius, centered at that edge. We have another accumulator array that has its array index incremented by one, every time a circle intersects that point. So, if you have a perfectly edge detected image, with a circle of radius R, and you input this to the CHT, you will find that at the center of that circle the accumulator value will be a maximum, because the Hough circles of radius R have interested many times over while being drawn. What we do to find these maximums is to split the image up into 16 x 16 grids and mark all pixels with highest value as a regional max. We then take the regional max pixels and check to see if their accumulator value is greater than the threshold. If it is, we record this point, along with its accumulator value, as a possible circle that could be the ball. The point list, along with the value list is returned at the end of the CHT. We perform the CHT in a loop where the value of the radius increases from a lower bound to an upper bound, depending on where we believe the ball to be in the image. During each loop we keep track of the highest accumulator value, and its corresponding x and y values and radius. At the end of the loop we have a radius and an X and Y value that is with highest probability a circle in the desired image. At this point we have determined where in the current image the ball lies and with what radius, assuming a ball is in the region of interest. The next step is the output to the microcontroller a position to move to so that we can catch the ball.  Figure: Shows the general processing steps for a given image, with wanted radius and threshold.
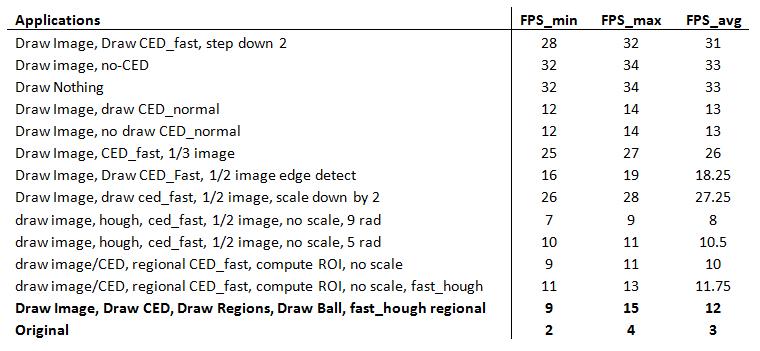
|