Cornell University
Electrical Engineering 476
Fixed Point DSP functions in GCC
Introduction
This page concentrates on DSP applicaitons of 8:8 fixed point in which there are 8 bits of integer and 8 bits of fraction stored for each number. The emphasis of these implementations is on speed, but accuracy considerations are addressed.
This page has the following sections:
Older DSP based on a MAC function call instead of the multfix assembler macro.
Digital Filtering
One of the most demanding applications for fast arithmetic is digital flitering. Atmel application note AVR201 shows how to use the hardware multiplier to make a multiply-and-accumulate operation (MAC). The MAC is the basis for computing the sum of terms for any digital filter, such as the "Direct Form II Transposed" implementation of a difference equation shown below (from the Matlab filter description).
a(1)*y(n) = b(1)*x(n) + b(2)*x(n-1) + ... + b(nb+1)*x(n-nb)
- a(2)*y(n-1) - ... - a(na+1)*y(n-na)
The y(n) term is the current filter output and x(n) is the current filter input. The a's and b's are constant coefficients, determined by some design process, such as the Matlab butter routine. Usually, a(1) is set to one, but as we shall see below, setting a(1) to a power of two may increase filter accuracy, at the cost of slightly increased execution time. The y(n-x) and x(n-x) are past outputs and inputs respectively. You can use the Matlab filter design tools to determine the a's and b's. There are also various web-applets around which help design coefficients:
(cutoff frequency)/(Nyquist frequency)=(cutoff frequency)/4000, the same. The IIR filter description is summarized in an article I wrote for Circuit Cellar magazine (manuscript).
Technical Note: To print floating point, the GCC linker options (click on [Linker options] in Project-> configure options->Custom options) must include the following specifications:
-Wl,-u,vfprintf -lprintf_flt -lm.
See AVRLIB description and a tutorial, but note that the tutorial has a misprint near the end. One linker option is left out in the tutorial.
Second order IIR Filters for 8:8
The 2nd order IIR code (plus uart.c, uart.h) implements an efficient MAC operation using the multfix asssembler macro and then uses it to produce a second order IIR filter. The time/sample is 140 cycles. It would not be reasonable to use this fixed-point algorithm with normalized cutoff frequency below about 0.10 because of the lack of relative precision in the b coefficients. With a normalized cutoff frequency=0.25, the impulse response is accurate to within 1% of peak response. With a normalized cutoff frequency=0.10, the impulse response is accurate within 5% of peak response. If you need a cutoff lower than 0.10, consider changing your hardware sample rate or using CIC filters (see below) to lower the effective sample rate. It is also possible to scale up all of the filter coefficients by 16 to give 4 bits more percision, then divide the output of the filter by 16 for each sample. IIRfilterScaledGCC644_macro.c is an example which executes in 190 cycles. This Matlab program allows you to simulate the effect of coefficient truncation on filter response.
Another approach used in speech synthesis is to use impulse-invariant second order filters which are a bit quicker to execute because they zero out two of the general second order filter coefficients (b(2) and b(3)). These filters can also be designed on-the-fly in a C program, rather than using Matlab. It is possible to build bandpass and lowpass filters using this technique, but you need to be careful of aliasing effects and the sensitivity of coefficients to 8-bit truncation. This matlab program allows you to estimate truncation errors and design filters. Note that the bandpass filters have a gain greater than one in the passband, so you may need to scale output to avoid overflow of fixed point numbers. At 8000 Hz sample rate, you can expect to get reasonable bandpass filter accuracy down to F=250, BW=25 Hz, and lowpass accuracy down to BW=250 Hz.
Impulse invariant second order filter design process:
F. If the filter is to be lowpass, set F=0. BW. If the filter is to be lowpass, the cutoff frequency is BW/2.C = -exp(-2*pi*BW*T) where T=1/(sample rate) B = 2 * exp(-pi*BW*T) * cos(2*pi*F*T) where T=1/(sample rate)A = 1 - B - C output(i)=A*input(i) + B*output(i-1) + C*output(i-2)Second order and fourth order Butterworth IIR Filters for 8:8
If you use a Butterworth approximation for lowpass (maximally flat IIR filter) then you can simplify the general IIR filter further to only three MAC operations. Since b(1)=b(3)=0.5*b(2), the three multiplies on the first line below can be combined into one multiply by sum of inputs, with one input shifted left.
b(1)*x(n)+b(2)*x(n-1)+b(3)*x(n-2) = b(1)*x(n)+2*b(1)*x(n-1)+b(1)*x(n-2) = b(1)* (x(n)+(x(n-1)<<1)+x(n-2))While a Butterworth high pass design yields
b(1)=b(3)=-0.5*b(2),
b(1)*x(n)+b(2)*x(n-1)+b(3)*x(n-2) = b(1)*x(n)-2*b(1)*x(n-1)+b(1)*x(n-2) = b(1)* (x(n)-(x(n-1)<<1)+x(n-2))And a Butterworth bandpass pass design yields
b(1)=-b(3) and b(2)=0,
b(1)*x(n)+b(2)*x(n-1)+b(3)*x(n-2) = b(1)*x(n)+0*b(1)*x(n-1)-b(1)*x(n-2) = b(1)* (x(n)-x(n-2))
A 4th order Butterworth bandpass filter (2 poles on lower side, 2 on upper side) can be done in 5 multiplies since b(1)=b(5)=-0.5*b(3) and b(2)=b(4)=0. Impulse response accuracy is within 2% after 10 samples with cutoffs of [0.25 0.35]. As the bandwidth of the filter gets smaller, the b coefficients get smaller also and roundoff errors get worse. Various tools exist to choose filter coefficients, for example the Matlab command [b,a]=butter(2,[Flow,Fhigh]) will generate the coefficients for this bandpass filter.
Since adding and shifting are much faster than multiplying ,we get a speedup. The 2-pole butterworth high and low pass execute in 107 cycles, the 2-pole bandpass in 103 cycles and the 4-pole butterworth bandpass in 200 cycles. All three second order filters and the fourth order bandpass are in one test program.
As before, accuracy of fixed point filters is always a concern. As the filter bandwidth gets narrower, the accuracy decreases. This is because the b(n) coefficients become smaller and roundoff/truncation error dominates. We can minimize truncation errors by scaling the filter coefficients and the filter code. As an example, if we set a(1)=16, and multiply all of the other coefficients by 16, then the value of the output does not change, but 4 more bits are available to store the scaled filter coefficients.
CIC filters
CIC filters are a form of optimized FIR filter with uniform coefficients. For example, an FIR filter with coefficients 0.2*[1 1 1 1 1], which is a 5 point running average, could be implemented using a CIC filter. For general use, CIC filters are considered crude, but they are widely used as a antialiasing prefilter before down-sampling a signal to a slower sample rate. See also Multirate Techniques and CIC Filters by Robert Lacoste, Circuit Cellar issue 231, Oct 2009, page 50ff.
This CIC filter example is a fourth order filter and 4-times downsampler. The filter attenuates frequencies above the new (lower) Nyquist frequency by about 50 db (factor of 300). The effective passband is about 0.25 of the new Nyquist frequency. A matlab test program is included as a comment in the C source code. The filter takes 170 cycles when it is only integrating, but 360 cycles when it is doing the downsampling and comb filtering. A version with better bandwidth incorporates a Chebyshev compensator to increase the passband to about 0.42 of the new Nyquist frequency. The Chebyshev filter uses ripple in the passband to compensate for droop in the CIC filter. The filter takes 180 cycles when it is integrating, 290 cycles when it is integrating and Chebyshev filtering, and 360 cycles when it is doing the downsampling and comb filtering. You could interleave other IIR filter operations into the remaining filter phases. Another version of the fourth order filter only downsamples by a factor of 2, but keeps the Chebyshev compensator for good bandwidth.
This CIC filter is a second order filter and 4-times downsampler. The filter attenuates frequencies above the new (lower) Nyquist frequency by about 25 db (factor of 17). The effective passband is about 0.4 of the new Nyquist frequency. The filter takes 100 cycles when it is only integrating, but 190 cycles when it is doing the downsampling and comb filtering. Significant aliasing can occur with this filter, but it may be good enough for some applications where speed is more important that quality.
Waveform Generation
Sine wave synthesis by direct digital synthesis (DDS) and noise synthesis by 31-bit linear feedback shift register are demoed in this program. The sample rate is 62,500 samples/sec, which is the highest PWM rate at 16 MHz clock rate.
Fast Fourier Transform (FFT) for 8:8
I adapted the int_fft.c program from this webpage. I simplified the program for real-only input and forward direction only (no inverse FFT). The function returns the real and imaginary components of the transform. The table gives the exectuion times in cycles and mSec (at 16 MHz clock) as well as the time to accumulate the input samples at 8 kHz. At an 8 kHz ADC sample rate, the FFT runs faster than real time up to 128 samples (FFT time < Sample time). In an actual spectrum estimation application, you would need to add time for windowing the input and combining the real and imaginary outputs (sums of squares or sums of absolute values) to get the power or amplitude. The program crashes for any FFT size greater than 128 because of memory overflow.
Code is FFTfixGCC644_macro.c, uart.c, uart.h.
| FFT size | cycles | FFT time (mSec) | Sample time (mSec) at 8 kHz |
|---|---|---|---|
16 |
8,040 |
0.5 |
2 |
32 |
18,340 |
1.2 |
4 |
64 |
41,520 |
2.6 |
8 |
128 |
92,700 |
5.8 |
16 |
There are many uses for a FFT including filtering, convolution, and pattern matching. Some applets.
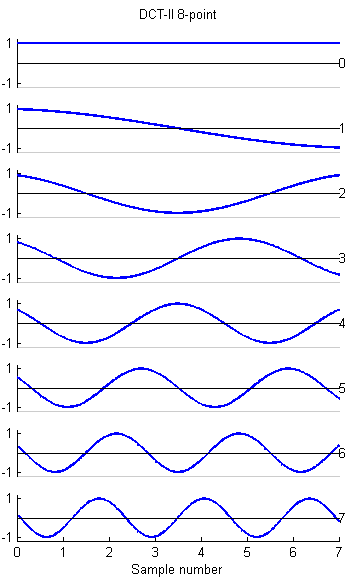
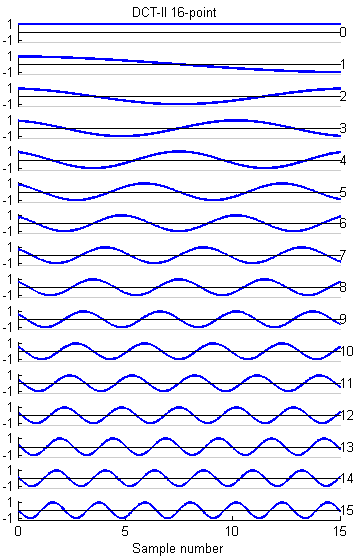
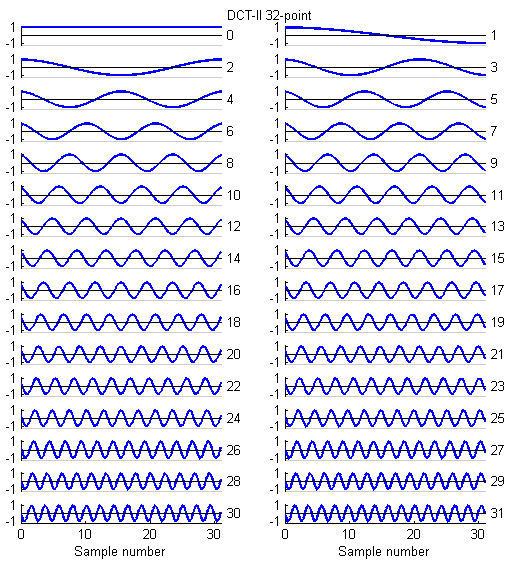
Discrete Cosine Transform (DCT) for 8:8
The DCT is a variant of the FFT which is used in image, sound, speech, and video processing and compression. I wrote 8,16 and 32-point versions based on the code in a web page by Yann Guidon <whygee@f-cpu.org> shows an optimized verion of the DCT-II algorithm for 8 points. I modified the code for GCC and assembler. The 16-point version was derived by combining two 8-point transforms. The book by KR Rao and P Yip Discrete Cosine Transform: Algorithms, Advantages, Applications (Academic Press 1990, pages 60-61) show how to combine transforms. The 32-point version was derived by combining two 16-point transforms. The test program requires uart.c and uart.h.
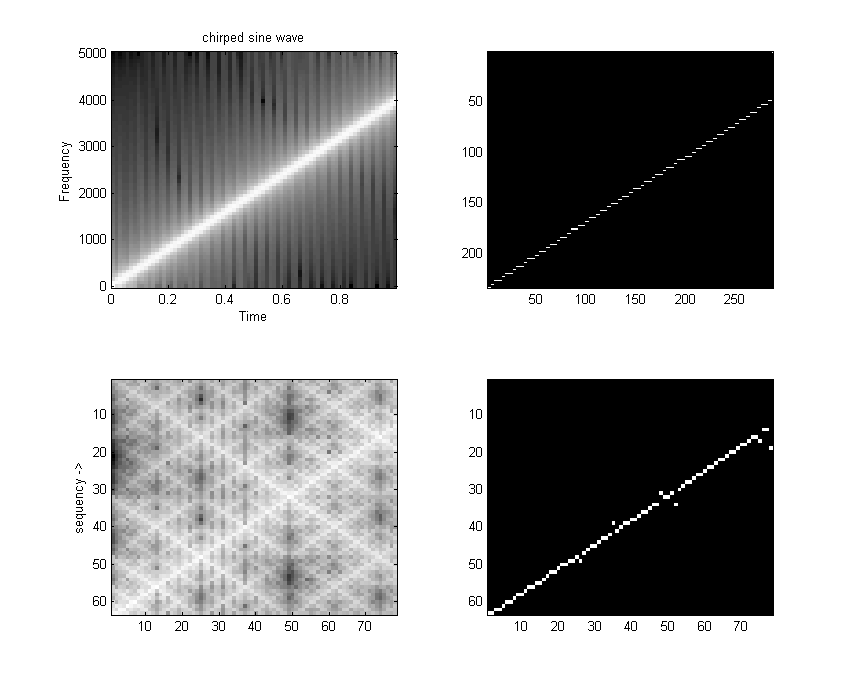
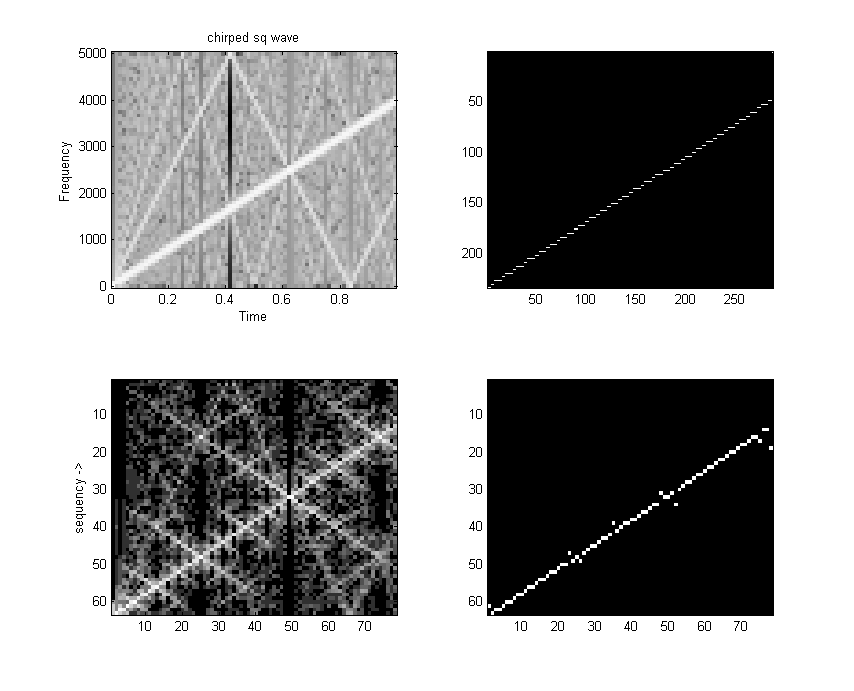
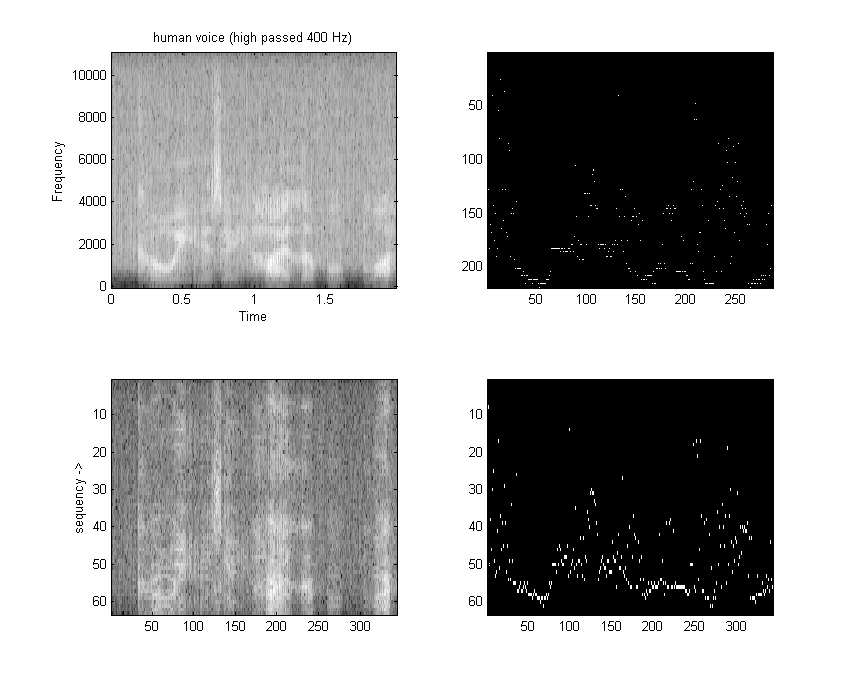
The 32 point DCT-II runs in 4070 cycles. This is fast enough to do some real time speech spectral analysis. At a sample rate of 8 KHz, a 32-point transform would cover 4 mSec of samples. Since the first (non-DC) harmonic is 1/2 cycle in a 4 mSec window, the fundamental of the transform is 125 Hz (low enough to catch a male voice fundamental) and the maximum frequency is about 3400 Hz (high enough to catch most information for speech). A matlab program which shows the spectral analysis properties of the DCT is here.
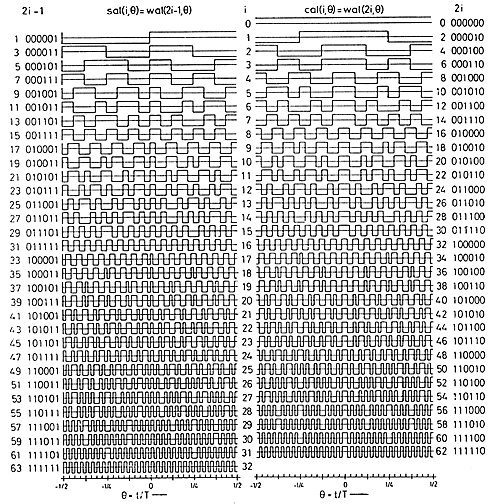
The basis functions for the 8, 16 and 32-point versions shown below are similar to the FFT, but capture gradients with fewer coefficients. For example, the first basis function (not the zeroth) in all images encodes an almost linear gradient, something which takes a sum of several basis functions of a Fourier series. The Matlab program to generate the plots is here.
Fast Walsh Transform (FWT) for 8:8
I wrote a FWT which
converts a time sequence to coeffieients of the orthogonal Walsh-function basis.
An example of the first 16 basis functions from Jacoby and
64 basis functions from Pichler is shown
below. Odd functions are called sal, analogous to sine, while
even functions are called cal. The following functions are in
arranged in sequency order. Sequency is defined as the number of zero
crossings, and is anaogous to arranging sines in frequency order.
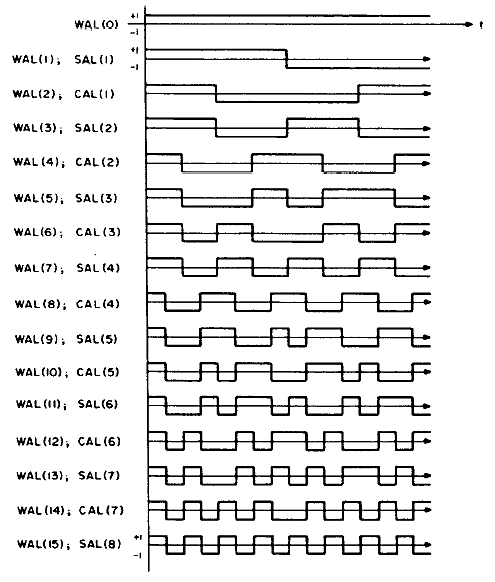
Os).
the program requires uart.c and uart.h. Note that the output of the FWTfix routine
is not in sequency order (it is actually in dyadic order).
Order is not important for some applications. Run the FWTreorder routine
to make a sequency order, but note that you must use the correct length reorder array.
The reorder routine takes about 780 cycles to order 16 points. Sound Synthesis
Karplus-Strong Algorithm, digital waveguides
The Karplus-Strong Algorithm (KSA) for plucked string synthesis is a special case of the digital waveguide technique for musical instrument synthesis. The KSA is particularly well suited for implementation on a microcontroller, and was originally programmed on an Intel 8080! The simplest version hardly needs fixed point arithmetic, but better approximations do require some more sophisticated digital filters. The basic algorithm fills a circular buffer (delay line) with white noise, then lowpass filters the shifted output of the buffer and adds it back into itself. The length of the buffer (along with an allpass fractional tuning filter and the sample rate) determine the fundamental of the simulated string. The type of lowpass filter in the feedback determines the timber. Prefiltering the white noise before loading the buffer changes the pluck transient timber. A matlab program to generate a plucked string is here. The equivalent C code is here. The C code takes about 200 cycles or 10% of the cpu (at a 8000 Hz sample rate) to generate one string.
Driving the Karplus-Strong string with a synthesized waveform expands the range of sounds you can make. In this version of the program, the string can be plucked using an initial waveform consisting of noise, sawtooth, triangle or sine wave. It can also be driven by an exponentially rising and falling waveform of all the previous types. A matlab program was used for testing, then converted to a DDS plus KSA C code. In the C code, each sample takes, around 380 cycles to compute. The PWM output is filtered through a simple RC lowpass with a cutoff of 10,000 radians/sec (about 1600 Hz). The string length of 61 (at 8000 Hz sample rate) corresponds to approximately note C3 (130.8 Hz). The examples below are generated from the C code.
| string Length |
fine tune |
string damping |
pluck | string LP_coeff |
drive freq | drive rise |
drive fall |
drive amp |
drive waveform |
sound out |
|---|---|---|---|---|---|---|---|---|---|---|
| 61 | 0.12 | 0.99 | none | 1 | 130.8 | 2 | 5 | 3 | saw | string_1.wav |
| 61 | 0.12 | 0.99 | triangle | 1 | - | - | - | - | - | string_2.wav |
| 61 | 0.12 | 0.99 | white | 1 | - | - | - | - | - | string_3.wav |
| 61 | 0.12 | 0.99 | white | 1 | 130.8 | 2 | 6 | 2 | saw | string_4.wav |
| 61 | 0.12 | 0.99 | none | 1 | 205.3 | 1 | 5 | 0 | saw | string_5.wav |
Changing the loop lowpass filter to a one-pole butterworth with a normalized cutoff of 0.2 (800 Hz), putting a one-pole butterworth highpass with a cutoff of 0.2 in the output, and introducing some clipping makes a sound which is vaguely clarinet-like. The matlab code. The C code and an example. The C code executes in about 430 cycles/sample at 8000 Hz sample rate.
Changing one plus to a minus makes a brassy percussion sound with a duration determined by the length of the delay line. More information can be found in referneces below.A generalization of the digital waveguide technique involves multiple waveguides, each with a bandpass filter. This is refered to as banded waveguides and is explained in papers by Essl, et.al (see below). The aim of banded waveguide programs is simulate spectrally complicated drum, bar (e.g. vibraphone), or multiple-string instruments. A matlab program to compute one banded waveguide is here. A banded waveguide with several diferent buffer lengths, and hence natural frequencies, (but no interaction between modes) is here. Modifying the program for additive mode interaction changes the sound somewhat. Parameters to control include: ratios of the different circular buffer lengths, width of the bandpass filters for each buffer, value of the damping factors for each buffer, and weights of the additive mixing. Please note that many of these techniques are patented by Stanford University and licensed to Yamaha and others.
ECE4760 projects which have used KSA
FM synthesis (Also see musical note generation)
An alternative to Karplus-Strong physical synthesis is to use FM modulation of a sine wave to approximate the sound of various instruments. Two matlab programs (1, 2) produce various string-like, chime-like or bell-like tones, depending on the FM parameters. A single FM modulator C version for Mega644 executes in about 220 cycles/sample, or about 10% cpu load at a 8000 Hz sample rate. There are several example parameter sets at the end of the C code. Two FM modulations (C program) applied to one DDS takes about 280-340 cycles/sample. Both of these programs could easily run at 16000 samples/second for better bandwidth. A third C version includes wave tables for different modulation shapes. The following table is from the third C version.
| main freq |
main rise |
main fall |
main type |
fm freq |
fm depth |
fm decay |
fm type |
sound out |
quality |
|---|---|---|---|---|---|---|---|---|---|
| 261 | 0 | 6 | sine | 350 | 8 | 5 | sine | fm_1.wav | chime |
| 1000 | 1 | 4 | sine | 50 | 10 | 5 | sine | fm_2.wav | rod resonator |
| 300 | 1 | 6 | sine | 1000 | 8 | 5 | sine | fm_3.wav | bell |
| 600 | 1 | 5 | sine | 150 | 8 | 6 | tri | fm_5.wav | electric guitar |
| 300 | 1 | 6 | sine | 1000 | 8 | 6 | tri | fm_4.wav | sound effect? |
| 261 | 4 | 5 | sine | 261 | 7 | 6 | tri | fm_6.wav | bowed string |
Additive synthesis
Additive synthesis attempts to match the Fourier spectrum of the desired sound. A matlab program and C program add three harmonics. The C program takes about 450 cycles/sample. At 8 KHz sample rate this is about 20% of the cpu time. Adding a high quality noise generator to the additive synthesis bumps up execution time to 970 cycles, but can make a steel drum effect. Adding three wavetable options (sine, sawtooth, and triangle) and reducing the quality of the random noise generator takes execution time to around 600 cycles/sample.
For the matlab program, with 5 additive frequencies, the following parameters and sounds give some idea of the capabilities of additive synthesis:
clarinet-like
f1 = 262 ;
f2 = 262 *2 ;
f3 = 262 * 3 ;
f4 = 262 * 4 ;
f5 = 262 * 5 ;amp1 = 1; fall_time1 = .7 ; attack_time1 = 0.7 ;
amp2 = .05; fall_time2 = .7 ; attack_time2 = 0.7 ;
amp3 = .5; fall_time3 = .7 ; attack_time3 = 0.7;
amp4 = 0.01; fall_time4 = .7 ; attack_time4 = 0.7 ;
amp5 = .2; fall_time5 = .7 ; attack_time5 = 0.7 ;
plucked string
f1 = 262 ;
f2 = 262 *2 ;
f3 = 262 * 3 ;
f4 = 262 * 4 ;
f5 = 262 * 5 ;
amp1 = 1; fall_time1 = .7 ; attack_time1 = 0.01 ;
amp2 = 1; fall_time2 = .3 ; attack_time2 = 0.01 ;
amp3 = .5; fall_time3 = .1 ; attack_time3 = 0.01;
amp4 = .3; fall_time4 = .1 ; attack_time4 = 0.01 ;
amp5 = .1; fall_time5 = .1 ; attack_time5 = 0.01 ;
drum
f1 = 262 ;
f2 = 262 * 1.58 ;
f3 = 262 * 3 ;
f4 = 262 * 2.24 ;
f5 = 262 * 2.55;
amp1 = 1; fall_time1 = .7 ; attack_time1 = 0.01 ;
amp2 = 1; fall_time2 = .3 ; attack_time2 = 0.01 ;
amp3 = 1; fall_time3 = .1 ; attack_time3 = 0.01;
amp4 = .3; fall_time4 = .4 ; attack_time4 = 0.01 ;
amp5 = .3; fall_time5 = .1 ; attack_time5 = 0.01 ;
bell
f = 523*2.
f1 = f ;
f2 = f * 1.58 ;
f3 = f * 3 ;
f4 = f * 2.24 ;
f5 = f * 2.55;
amp1 = 1; fall_time1 = .7 ; attack_time1 = 0.01 ;
amp2 = 1; fall_time2 = .3 ; attack_time2 = 0.01 ;
amp3 = 1; fall_time3 = .1 ; attack_time3 = 0.01;
amp4 = .3; fall_time4 = .2 ; attack_time4 = 0.01 ;
amp5 = .3; fall_time5 = .1 ; attack_time5 = 0.01 ;
References
The codevision/Mega32 DSP page has older versions.
Copyright Cornell University March 11, 2013
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}