In any application, we must be able to support node to node communication regardless of any signal attenuation. While it is very easy to simply place an nRF24 radio module onto each node and call it a day with direct node to node transmission, this type of network communication protocol ultimately does not satisfy all of our constraints and does not lend to an adaptive network. For example, using this type of transmission, we will always have one node directly communicating to another node. In this case, if there is heavy attenuation between two such nodes, no communication will ever be established. To overcome this, we decided to implement a mesh network topology for all communication.
The mesh network offers three main advantages:
- Multi-Node Path Communication
- Dynamic Route Discovery
- Dynamic Route Reconfiguration
Mesh Network Software Overview
The mesh network software consists of one source file and a header file which provides an API for the higher-level application layer to use. Each node is loaded with the exact same mesh network software, with the only difference being different hard-coded IDs. A cache data-structure is used to house path information for each node. Upon startup, the cache will be initially empty. The API provides a send function which will send a message from node i to node j if there exists any possible path in the mesh network between these two, otherwise it will return an error message. In summary, this function checks its path cache to see if there is an existing path between the two nodes. If there is, we get a cache hit and can send immediately by calling the radio layer's send code. Otherwise, it will begin the cache miss path which will be detailed more below.
STATUS sendA(int8_t dst_addr, char* message, int msg_len){
STATUS result = OK;
gv_originate_rreq_flag = 0;
int cacheIndex = 0;
memcpy(gv_message, message, msg_len);
gv_msg_len = msg_len;
gv_dest_node = dst_addr;
cacheIndex = checkCache(dst_addr);
if (cacheIndex != ERROR) {
setupSendMsg(dst_addr, message, msg_len, cacheIndex);
send((char *) &gv_send_message, gv_send_message.header.size, gv_routeTable[cacheIndex].next_hop_addr);
return OK;
}
else {
gv_originate_rreq_flag = 1;
setupRreq(dst_addr);
dataFlood(&gv_flood_message, gv_flood_message.header.size);
return ERROR;
}
}
The interface also provides a receive callback function to be called when a packet is received at the application layer. This callback function will decode the message and either route it through the mesh network (for path configuration purposes) or immediately forward the data back to the application layer as an encoded data packet. A software filter is also included in this receive function in order to prevent continuous flooding of the network when requesting paths.
STATUS recv_Msg(char* message, int msg_len){
gv_rcvd_flag = 1;
memcpy(&gv_recv_message, message, msg_len);
switch(gv_recv_message.header.type){
case 0:
if (gv_recv_message.header.dst_addr == gv_node_addr) {
recv(&(gv_recv_message.data),gv_recv_message.header.size - 7);
}
else {
gv_forward_flag = 1;
sendA(gv_recv_message.header.dst_addr, (char *)&(gv_recv_message.data), (gv_recv_message.header.size-7));
}
gv_blockFlood = 0;
gv_ignoreSrc = 0;
gv_ignoreDst = 0;
break;
case 1:
if (gv_originate_rreq_flag == 0){
if ((gv_blockFlood != 1) || (gv_ignoreSrc != gv_recv_message.header.src_addr) || (gv_ignoreDst != gv_recv_message.header.dst_addr) || (((rreq_message *)&(gv_recv_message.data))->broadcast_id > gv_savedID)){
serviceRreq(&gv_recv_message);
}
gv_blockFlood = 1;
gv_savedID = ((rreq_message *)&(gv_recv_message.data))->broadcast_id;
gv_ignoreSrc = gv_recv_message.header.src_addr;
gv_ignoreDst = gv_recv_message.header.dst_addr;
}
break;
case 2:
serviceRrep(&gv_recv_message);
gv_blockFlood = 0;
gv_ignoreSrc = 0;
gv_ignoreDst = 0;
//gv_savedID = 0;
break;
default:
break;
}
}
In addition to the interface functions, there are multiple functions used in the source file to actually implement the mesh network communication protocol. These functions mainly act as helper functions to check the different data structures or format and decode messages or as servicing functions for receive callbacks. These functions were hidden from other layers in order to provide the user with access to the capabilities of a network without the hassle of integrating a design with one.
Message Format
The byte-level encoding of each message is shown below.
| Type | BYTE 0 | BYTE 1 | BYTE 2 | BYTE 3 | BYTE 4 | BYTE 5 | BYTE 6 |
|---|---|---|---|---|---|---|---|
| Message Header | type | size | src addr | dst addr | hop addr | num hops | curr hop |
| RREQ Message | broadcast id | dst addr | dst seq cnt | src addr | src seq cnt | hop cnt | pad |
| RREP Message | dst addr | dst seq num | src addr | lifetime | pad | pad | pad |
| Route Table Entry | dst addr | dst seq num | valid flag | hop count | next hop addr | lifetime | network int |
Multi-Node Path Communication
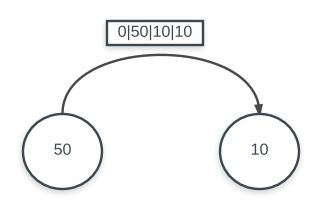
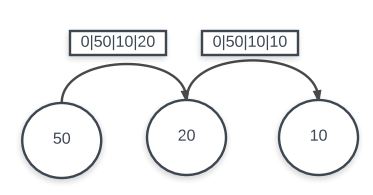
As previously stated, one of the main advantages of implementing a mesh network communication protocol is to provide multi-node sending of packets. This provides many advantages such as long-distance sending, network reconfiguration, and self-healing. Overall, implementing a multi-node send is as simple as sending from the source node to an intermediary node. Receiving the data at this node and copying it into a buffer and resending to another intermediary node or the destination. However, in order to allow this functionality along with a self-healing, reconfigurable mesh network, it was necessary to introduce a cache to house stored paths.
While the actual process of requesting fresh, new paths and will be detailed in a later section. This section will briefly discuss the basics behind multi-node sending. Each node will have a cache which is implemented via an array and several pointers to different sections of the buffer. When the send function is called by the interface layer, it will input a source node, a destination node, the message, and the size of the message. The send function will then search the cache in the node by seeing if there is a cache entry which has a path to the destination. Encoded inside each of these cache entries is the destination node, the next node to hop-to (for multi-node hops), and the total number of hops. If there is a match between the inputted destination node and a cache entry, it will return a cache hit and the node will send the data (along with a prepended 7-byte header for information) to the next hop node or the destination if none exists. At the next hop node, it will decode the packet and see that it is a data packet which has to be forwarded. Because of the way path requests work, this node will also have a cache entry to the destination, so when the send function is called again, it will always respond with a cache hit and send. If there is a cache miss, then there is currently no path from the current node to the destination, and thus the route request path must be started.
Dynamic Route Discovery
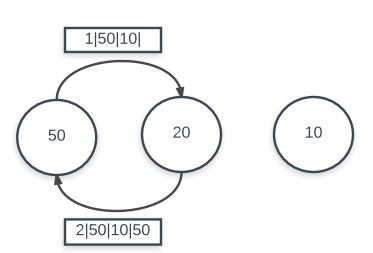
In addition to having multi-node sending, it is also important to be able to dynamically discover new routes from source nodes to destination nodes. By having this adaptive routing algorithm, the network is able to easily acclimate to sudden power-loss or hard-resets of individual nodes. At startup, each node has no route information to any other node. This means that the cache for the node which houses all routing information is empty. The first possible event that can happen is the master node sending out any of the four commands. In this case, we have the master node attempting to send to another node which it has not established route information for. In this case, there will be a cache miss which will begin the dynamic route discovery routine.
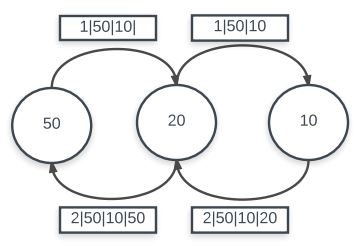
The dynamic route discovery routine works by first sending a RREQ message via a flood. The RREQ message acts as a broadcast to all nodes saying that the source node does not have a path to the destination node but would like to establish communication between them. Any node which receives the RREQ has two options: forward the RREQ message by flooding its own RREQ message or returning a RREP message (signifying that it has a path). In the former case, the receiving node does not know a path to the destination node and is also not the destination itself. It will thus, send out its own RREQ flood to try and find a path to send back to the original source. In the latter case, the receiving node either has a path in its cache or is in fact the destination node. It will then construct a RREP message and send it back in reverse direction. Because of this, all nodes which have propagated forward the RREQ will also be able to fill in its cache information about the path. Eventually the soruce node will receive the RREP message and fill in its own cache before reinitiating the send.
typedef struct {
int64_t broadcast_id : 8;
int64_t dst_addr : 8;
int64_t dst_seq_cnt : 8;
int64_t src_addr : 8;
int64_t src_seq_cnt : 8;
int64_t hop_cnt : 8;
int64_t pad : 16;
} rreq_message;
typedef struct {
int64_t dst_addr : 8;
int64_t dst_seq_num : 8;
int64_t src_addr : 8;
int64_t lifetime : 8;
int64_t pad : 32;
} rrep_message;
It is important to note that when a node receives a RREQ flood message, it will save the address which it received the flood from and either propagate a flood or return a RREP. It is also important to note that whenver a node receives a RREP, it will either be a source or intermediary node on the path, and in every case it will store information in its cache so that the send will properly propagate through this path. This is encoded in a next hop field used in send. This means after a RREP has been propagated back to the store, the send will hop in a reverse manner in which the RREP was sent.
While there is a lot of startup overhead in terms of filling in all of the node's caches and flooding the network with RREQ messages and waiting for RREP messages, this networking algorithm works very efficiently for both very small networks with close proximitive nodes and also for very large networks with multiple nodes. In the first case, due to the proximity of the nodes, the discovered paths will generally be direct paths as simply receiving a message and returning at the destination is faster than processing multiple floods. On the other hand, for large networks, this is almost necessary to have in order to ultimately achieve efficient paths between the nodes. Furthermore, this system was designed to be long-term with a very large battery life. Because of this, the large overhead in terms of achieving full network throughput is weighed against getting the fastest path between all nodes at steady-state.
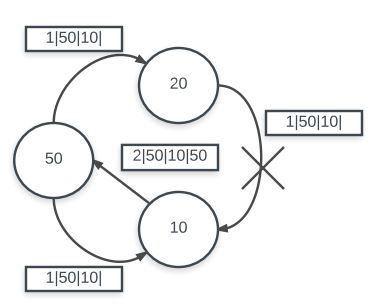
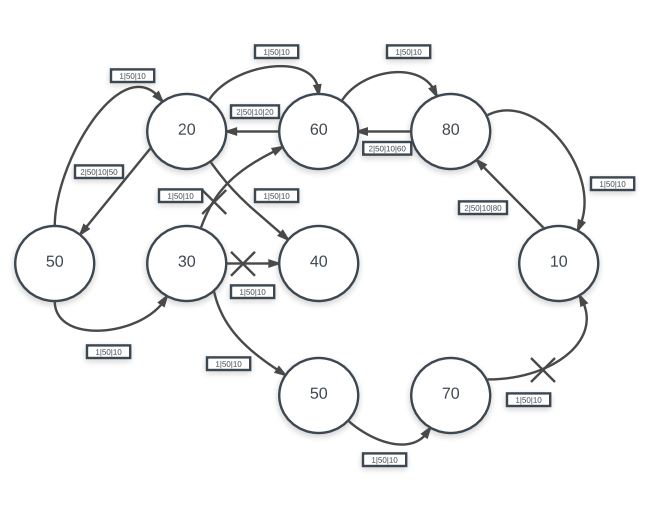
Dynamic Route Reconfiguration
Finally, it is important to be able to dynamically reconfigure paths between nodes in real-time. The current implementation fetures dynamic route reconfiguration by being able to reset the cache in the master node. By resetting the cache, the master node must then completely re-establish paths to each node via the RREQ and RREP paths discussed above. This generally works for the current system as only query commands and linked events will cause general nodes to communicate to each other. As most of the time, only the master will have routes to and from nodes, this simple resetting allows dynamically reconfigurable routes.
One unimplemented idea is to have a steady-state sending thread in each node asking other nodes if they are in range. If they aren't, the node will then remove all paths which include them from its cache. This way, there will never be a dead path in its route. Another easy fix is to implement a simple time-out in the cache, where it will remove an active path in the cache after it has not been used for a long-time.