|
SimpleGPU
ECE 576 - Fall 2007 John Sicilia (jas328) & Austin Lu (asl45) |
|
Hardware Design Here is our top level Verilog code. The Pipeline In order to reach an acceptable hardware refresh rate, we decided to pipeline the drawing process within hardware. Because the computation involved so many successive multiplies and divides, it was the only way to achieve a decent rate. The pipeline moves at a clock divider set by the low 8 switches on the DE2 board. Through trial and error, we have learned that a clock divider of 4, and a clock of 12.5MHz seems to give us the best results. By pipelining the process, we were able to use a speed that could theoretically give us a refresh rate of 40Hz. Because of the high throughput needed, we found that only computing during the syncs was reducing our rate too much. As a result, we came up with an alternative scheme. In our current hardware, we now always are performing calculations so we truly achieve 12.5MHz. However, because we are only allowed to write to SRAM during the syncs, we buffered the process. We keep a buffer of 128 pixels in memory and our pipeline constantly iterates through them, writing and overwriting. Even though this buffer is small, it is sufficient, because now hardware is writing fast enough to make multiple passes if need be. During the horizontal and vertical syncs, we write from sramBuffer to the SRAM. We increment an index sramBufferWriteIndex appropriately and set a lock, just in case the sync ends before we can write to SRAM. If the lock happens to fail, the last pixel is rewritten. In order to do graphics, we decided to go for a medium between our old, simple 320x240 display method and the more complex 640x480 display. There are 640x480=307,200 addresses needed to map 16 bits of SRAM data to each pixel. Unforunately, there are only 218=262,144 addresses. Instead of halving our color range, we decided to get the maximum display screen we could with the addresses we had. 590x440 kept our resolution the same, and used almost every possible address (with 2,544 remaining). As a result, our screen size was centered with a black border of 25 on each side. The pipeline works by iterating through each pixel in the 590x440 grid. At each pixel, it sequentially performs operations on each polygon, storing into a buffer the polygon that both encapsulates the pixel and has the lowest Z. It is divided into five stages. Stage 1 ñ Polygon Fetch The Polygon Fetch stage updates the values of the pixel and polygon, and sends a clear flag if appropriate. The x and y coordinates (xpixs1, ypixs1) are chosen. If we have completed the last polygon, a clear next pixel command is sent down the pipeline (clearflagS1), and the x and y pixels are incremented appropriately. The clear next pixel command resets the Z buffer and polygon placeholder associated with each pixel. During normal operation, without clear flags, the polygon number is stored (polygonS1), and then flopped to stage two (polygonS2), where calculations begin. If we are not at the last polygon, the x and y coordinates do not change. xpixs1, ypixs1, polygonS1 and clearflagS1 are sent to stage 2. Stage 2 ñ Point Inside Polygon The Point Inside Polygon stage checks to see if the current polygon contains the pixel. The x and y coordinates are flopped into stage two. Additionally, we determine if the pixel is within the current polygon. If the pixel (x,y) is within the polygon, we store its depth into Z_S3 as if it were part of the polygon. The three coordinates, (x, y, z), are flopped into stage 3. To determine whether a pixel is within a polygon, we turn the following C code into verilog:
This algorithm works by essentially seeing how many edges a ray to the point must pass through. If it is an even number, then it is outside the polygon. If it is an odd number, it's inside the polygon. For convex polygons, the number will always be 0, 1, or 2. If c is one, the point lies within the polygon. Stage 2 is also where the plane equation is defined. The plane equation is: A(x-x0) + B(y-y0) + C(z-z0) = 0The xpixs2, ypixs2, polygonS2, A, B, C, and whether the pixel is within the polygon (the XOR of the bus oddNodes) are flopped to stage 3. Stage 3 ñ Z-Buffer Calculations If the x and y coordinate is within the polygon, we need to calculate its corresponding depth. To calculate the depth of the pixel, we take the first three points of the polygon, which form a plane, and use the plane equation to find the depth. 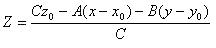 The xpixs3, ypixs3, Z, and inPolygonS3 are flopped to stage 4. Stage 4 ñ Z-Buffer Comparison If the coordinate is within a polygon, and its calculated Z is closer than the stored Z (zBuffer), the pixel becomes associated with the new polygon (zPolygon). Otherwise, nothing is stored in the buffer. The xpixs4, ypixs4, zBuffer, polygonS4, and zPolygon are all passed to stage 5. Stage 5 - Writeback In stage 5, if the polygon passed through is the last polygon, the zBuffer and zPolygon are written to the sramBuffer and the sramBufferReadIndex is incremented. If the sramBufferReadIndex is too large, it is reset. Additionally, stage 5 is where color is chosen. Although we originally used solid colors, we also created an implementation that uses greyscale to determine depth. The darker the grey, the farther the pixel is away from us. |