Despite the fact that we are processing and analyzing data in
real time, the FWT analysis and summary were produced
instantaneously after the release of the yellow button. There are
no known errors associated with controlling the MCU operation via
both PuTTY and the physical button panel. Even when 2 buttons are
pressed at the same time, the system will sequentially execute
the valid commands.
Here are some screen shots of our system during operation:
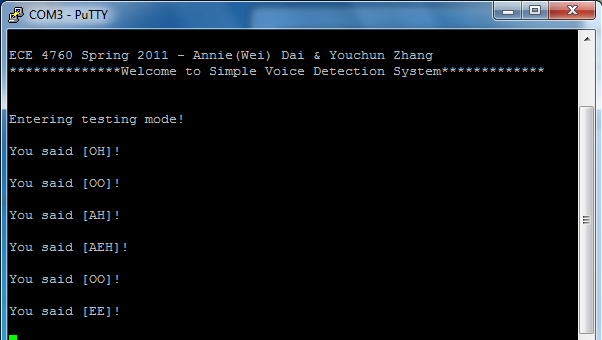
When the system is turned on, our MCU automatically enters the
default testing mode. At the same time, PuTTY will display a
welcome screen informing the user that the system is ready to
take inputs.
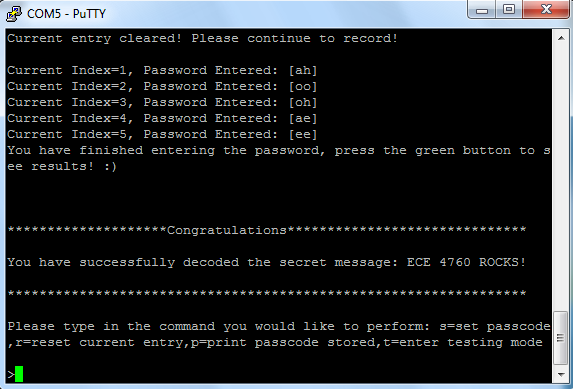
In the testing mode, the user is able to see the summary
results of only saying 1 vowel. Audio input is processed when
the user holds down the yellow button while speaking into the
microphone. When the yellow button is released, the program will
automatically compute the FWT and display the prediction in PuTTY.
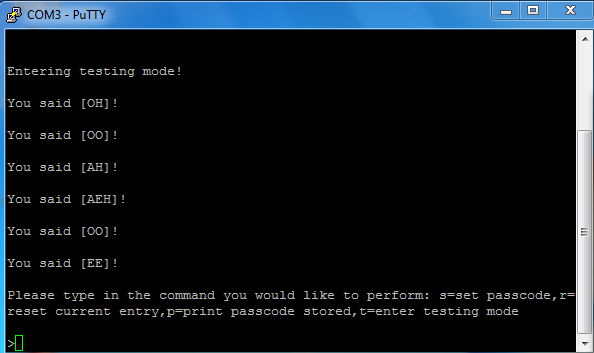
To leave testing mode, the user can just press and release the
red button once. As shown below, PuTTY shows that the program has
exited testing mode and entered the decoding mode.
In the decoding mode, the user can set a sequence of 5 vowels
as the system password and repeat the same sequence via the
microphone while holding down the yellow record button.
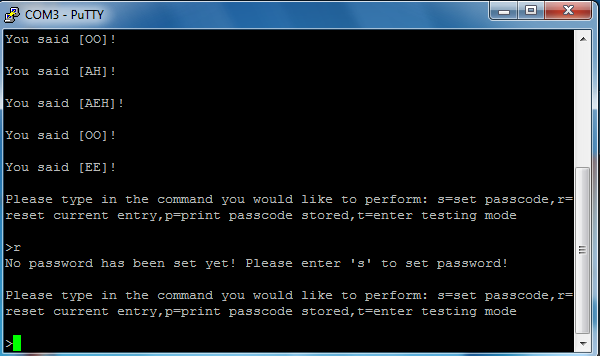
If the user accidently entered the reset command before setting
a password, the system will inform the user that there is no
valid password being stored at the time. The user should set
the password first by entering 's' to the command line.
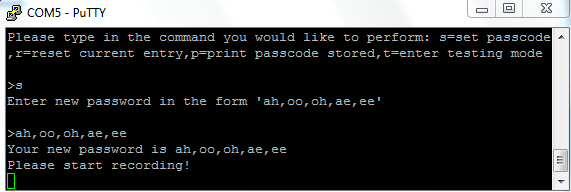
New password is entered by inputting the vowel sequence with
commas separating each vowel input. Once entered, the system will
display the entered result and automatically enter recording mode
where the MCU simply waits for user's audio input.
If the input audio sequence agrees with the stored password,
then the congratulations screen will appear along with the secret
message.
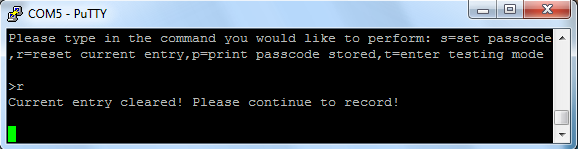
Anytime there is a command prompt at PuTTY, the user can choose
to reset his/her current audio input by entering 'r'. This erases
all of the audio inputs stored so far in the system and allows
the user to re-record the password again.
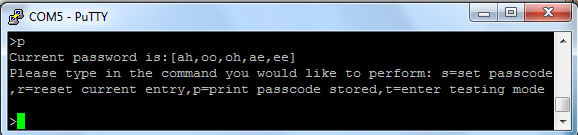
Anytime there is a command prompt at PuTTY, the user can see
the stored system password by entering 'p' for print. The system
will display the entered vowel sequence.
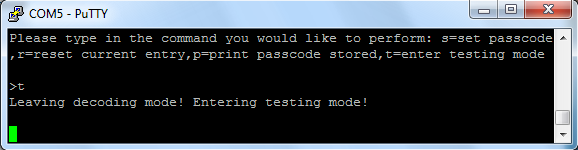
The user can reenter testing mode from decoding mode by
entering 't' at the PuTTY command line.
Here are 2 videos demonstrating our system at work
Performance
We originally designed our program to decode female voices.
However, when we tested our system, we discovered that it decodes
male voices (of much lower fundamental frequency) just as
accurate as it decodes female voices. However, due to the limited
precision of the FWT we implemented, in cases where the frequency
peaks are near our predefined characteristic peak value for a
vowel, errors occasionally occur. We tested our program with a
couple of our friends and for a male voice, the program is able
to accurately predict the vowel said 49/50 times and for female
voices, the program is able to accurately predict 45/50 times.
Furthermore, the program only accurately recognizes vowel is the
user is consistent in speaking (no accents or instability during
recording).
We tested our program with a
couple of our friends and for a male voice, the program is able
to accurately predict the vowel said 49/50 times and for female
voices, the program is able to accurately predict 45/50 times.
Furthermore, the program only accurately recognizes vowel is the
user is consistent in speaking (no accents or instability during
recording).
We also found that the MCU tend to confuse between "OO" and
"EE" or "OH" and "AE". In the case of "OO" and "EE", the
waveforms are very similar. In the FWT output, both vowels have
peaks that often overlap. In our program, "OO" and "EE" are
determined by the maximum amplitude obtained in the transform.
In normal speech, "OO" is louder and "EE" (see below for
waveform comparison). This explains why MCU mistakes one for
the other.
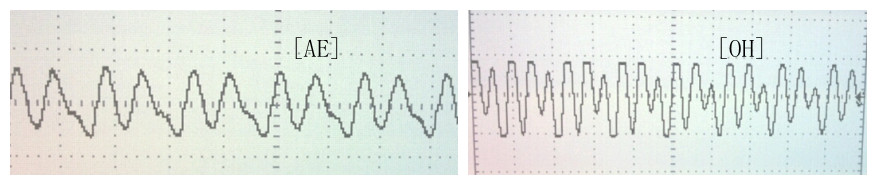
In the case of "OH" and "AE", FWT of the input waveforms
produce almost the same first and second peaks. The two vowels
are distinguished mainly based on the location of the third peak.
However, the amplitude of the third peak is relatively low and
can be easily mixed up with noise. Thus, predictions made about
"AE" and "OH" and differ greatly depending how the speech was
formulated.
Here are some test results we got using our system:
MCU Confusion for\Expectation
ah
oh
oo
ae
ee
Female
--
--
--
oh
oo
Male
oh
ae
--
--
--
MCU's Prediction Accuracy
95%
90%
95%
94%
90%
Safety and Usability
The system that we have designed can be used as a basis for
implementing speech recognition since speech consists of vowels
and consonants that can be identified using frequency analysis.
An example of possible implementation in the real world would be
using speech recognition in security systems, something that
could be more convenient than entering passwords on a keypad to
people with less proficient vision.
Furthermore, our system is simple and easily to handle. The
only precaution in using our prototype system is the user must be
careful in touching the PCB and port pins to minimize ESD hits.