
Conclusions
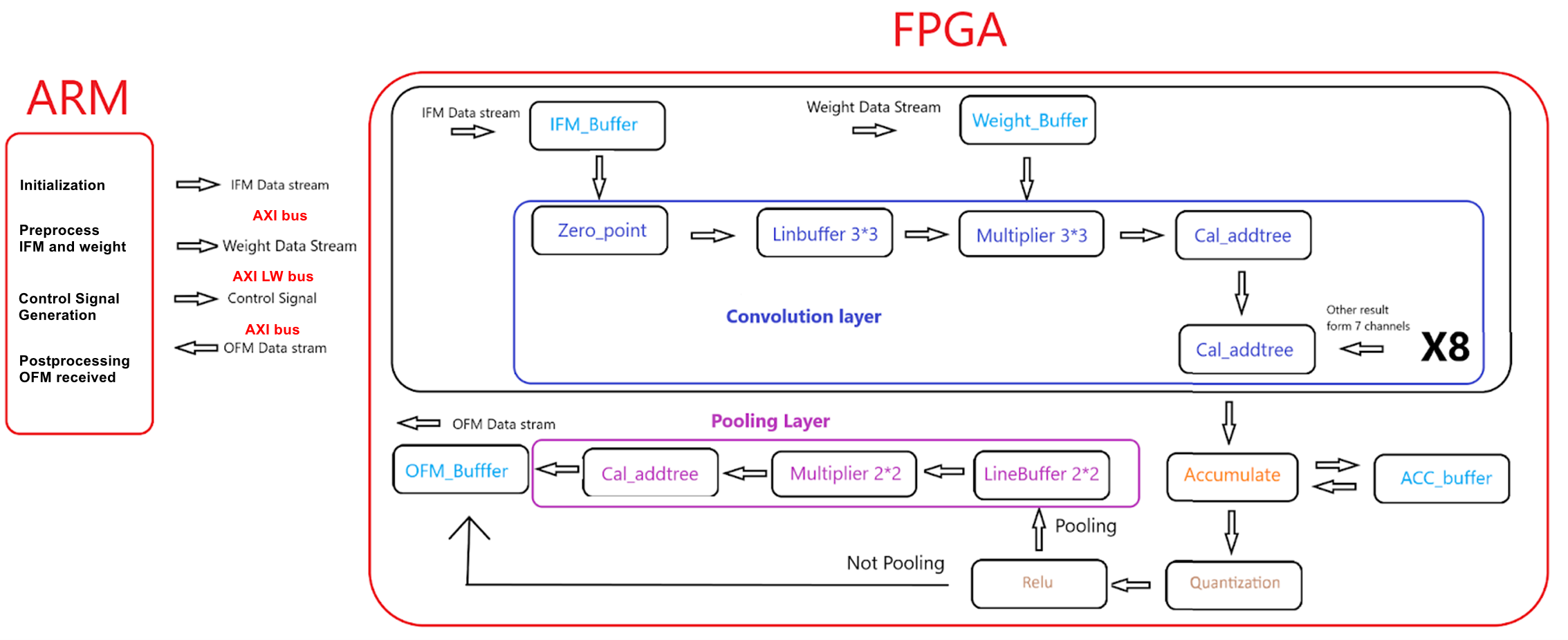
For this project, we've successfully implemented a high-parallelizable and parameterizable microarchitecture specifically for the inference of CNN layers. In the above test cases, we’ve demonstrated how to set relevant parameters of one single convolution layer and a high level of functional extensibility.
Improvement in the future work
However, the current architecture only supports the configuration of the convolution kernel of 3*3 with the stride of 1, and the pooling kernel of 2*2 with the stride of 2. So in the future, we might consider defining an improved architecture that also allows the modification of the kernel size and stride. Furthermore, one flaw of our design involves how we transferred data from HPS to FPGA fabric, in the current design, we loaded 8 whole feature maps into block memory on FPGA at one time. This scheme significantly increases the utilization of the on-chip memory resources, so the size of feature maps is highly limited, which is also the reason why the image we used in the demo is so small. So, we will try a different load scheme like only loading part of the input feature map at one time and continuing to load another part when the accelerator is working on the loaded part, that is, leveraging a ping-pong buffer.