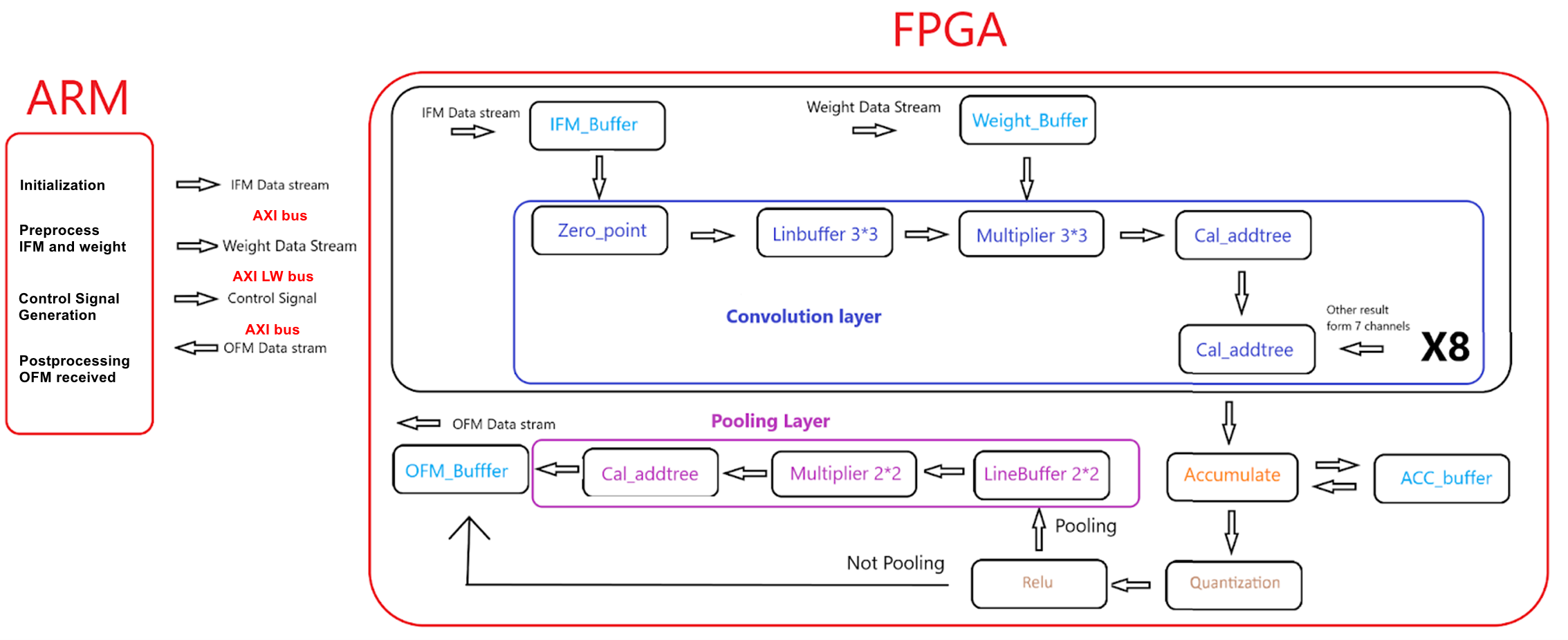

Software Design
On the HPS (Hard Processor System) side, we implemented preprocessing and transmission of input feature maps for each convolution layer, generation and transmission of control signals, and the reception and storage of FPGA output feature maps.
Methods We Tried
Due to the system's involvement in multiple convolution layers in real applications, there was a need to store substantial amounts of IFM (Input Feature Maps), OFM (Output Feature Maps), and weights, the specific sizes of which depend on the number of layers and input image size. Therefore, a large storage space with fast read and write capabilities was required. Initially, we planned to transmit control instructions to the DMA through the HPS, which would then read data from 1GB DDR3 using a memory map to AXI stream to transfer to the FPGA's receiving data interface. Using DMA as a bi-directional controller allowed for a transfer rate of around 270 MBytes/sec [6]. Once the FPGA processed the data, DMA would then handle the task of writing the data back to the DDR3. However, "the HPS has 64Kbytes of on-chip memory which does not seem to be touched by Linux" [6], which means there are only 64Kbytes of DDR3 can be used by DMA master. This was insufficient for our needs. We then considered other IPs such as Ethernet, but due to unfamiliarity and high learning curves, we decided against their use. Eventually, we opted to use Parallel ports (PIO ports) for bi-directional data transfer on both full AXI and light-weight AXI buses, storing data in FPGA SDRAM via a memory map.
Details in C program
Preprocess
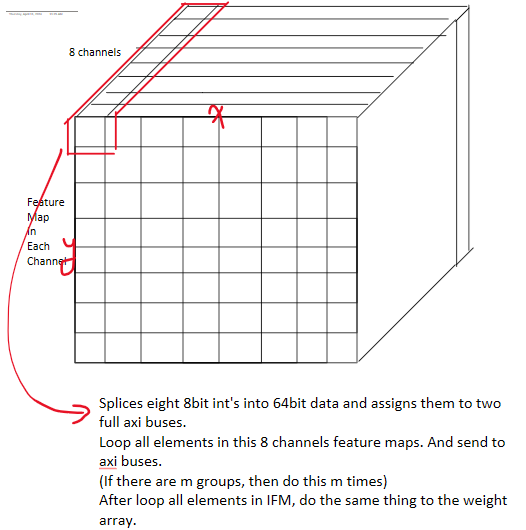
We implemented grayscale processing of PNG input images in C within Linux, storing the data in IFM's 4D arrays. The 4D array is structured by group, channel, and the x,y coordinates of each channel's feature map. The size of channel element is 8, as this is the maximum parallelism in the input channel dimension implemented on the HPS side. The group is calculated as the size of the input channels divided by the maximum number of channels, which is 8. We also managed the reading and storage of pre-trained weight text files into 4D weight array. The array is the same structure as the IFM array. Additionally, the ARM handled the padding of IFMs, as this process was cumbersome for FPGA programs constrained to a specific array size. Since the FPGA program was designed for 8-channel parallel input, requiring data to be transmitted in groups of 8 channels as shown in figure 18, HPS also implemented the concatenation of data for IFM and weight 4D arrays. With the maximum bit width of PIO ports being 32 bits, we used two full AXI PIOs to transmit input data. Additionally, we utilized some PIOs on lightweight AXI bus to transmit corresponding control signals, including indications of whether IFM or weights were being transmitted, the address for the IFM buffer, the address for the weight buffer, the completion of transmission of all 8 channels of IFM and weights, etc. Through actual measurements, when the full AXI bus was not busy, there was no need for delays, allowing FPGA to effectively receive all data. Therefore, we did not design a bi-directional handshake protocol.
Usability
To enhance usability and configurability, on the ARM side, we also implemented parameter configurations, including the number of input channels per convolution layer, the size of input feature images, the number of output channels, whether to perform max pooling, padding size, quantization input and output zero point, and thresholds. These parameters would be transmitted to the FPGA via PIO on the lightweight AXI bus. Users can configure these settings at the program's start through command-line inputs.
Receive
Finally, we received the 64-bit width OFM stream completed by the FPGA calculations through the full AXI bus, storing it into a 4D OFM array similar to IFM.